") Spark SQL的概念及查詢方式
Spark SQL的概念及查詢方式
一、Spark SQL的概念理解
Spark SQL是spark套件中一個(gè)模板,它將數(shù)據(jù)的計(jì)算任務(wù)通過(guò)SQL的形式轉(zhuǎn)換成了RDD的計(jì)算,類似于Hive通過(guò)SQL的形式將數(shù)據(jù)的計(jì)算任務(wù)轉(zhuǎn)換成了MapReduce。
Spark SQL的特點(diǎn):
和Spark Core的無(wú)縫集成,可以在寫整個(gè)RDD應(yīng)用的時(shí)候,配置Spark SQL來(lái)完成邏輯實(shí)現(xiàn)。
統(tǒng)一的數(shù)據(jù)訪問(wèn)方式,Spark SQL提供標(biāo)準(zhǔn)化的SQL查詢。
Hive的繼承,Spark SQL通過(guò)內(nèi)嵌的hive或者連接外部已經(jīng)部署好的hive案例,實(shí)現(xiàn)了對(duì)hive語(yǔ)法的繼承和操作。
標(biāo)準(zhǔn)化的連接方式,Spark SQL可以通過(guò)啟動(dòng)thrift Server來(lái)支持JDBC、ODBC的訪問(wèn),將自己作為一個(gè)BI Server使用
Spark SQL數(shù)據(jù)抽象:
RDD(Spark1.0)-》DataFrame(Spark1.3)-》DataSet(Spark1.6)
Spark SQL提供了DataFrame和DataSet的數(shù)據(jù)抽象
DataFrame就是RDD+Schema,可以認(rèn)為是一張二維表格,劣勢(shì)在于編譯器不進(jìn)行表格中的字段的類型檢查,在運(yùn)行期進(jìn)行檢查
DataSet是Spark最新的數(shù)據(jù)抽象,Spark的發(fā)展會(huì)逐步將DataSet作為主要的數(shù)據(jù)抽象,弱化RDD和DataFrame.DataSet包含了DataFrame所有的優(yōu)化機(jī)制。除此之外提供了以樣例類為Schema模型的強(qiáng)類型
DataFrame=DataSet[Row]
DataFrame和DataSet都有可控的內(nèi)存管理機(jī)制,所有數(shù)據(jù)都保存在非堆上,都使用了catalyst進(jìn)行SQL的優(yōu)化。
Spark SQL客戶端查詢:
可以通過(guò)Spark-shell來(lái)操作Spark SQL,spark作為SparkSession的變量名,sc作為SparkContext的變量名
可以通過(guò)Spark提供的方法讀取json文件,將json文件轉(zhuǎn)換成DataFrame
可以通過(guò)DataFrame提供的API來(lái)操作DataFrame里面的數(shù)據(jù)。
可以通過(guò)將DataFrame注冊(cè)成為一個(gè)臨時(shí)表的方式,來(lái)通過(guò)Spark.sql方法運(yùn)行標(biāo)準(zhǔn)的SQL語(yǔ)句來(lái)查詢。
二、Spark SQL查詢方式
DataFrame查詢方式
DataFrame支持兩種查詢方式:一種是DSL風(fēng)格,另外一種是SQL風(fēng)格
(1)、DSL風(fēng)格:
需要引入import spark.implicit. _ 這個(gè)隱式轉(zhuǎn)換,可以將DataFrame隱式轉(zhuǎn)換成RDD
(2)、SQL風(fēng)格:
a、需要將DataFrame注冊(cè)成一張表格,如果通過(guò)CreateTempView這種方式來(lái)創(chuàng)建,那么該表格Session有效,如果通過(guò)CreateGlobalTempView來(lái)創(chuàng)建,那么該表格跨Session有效,但是SQL語(yǔ)句訪問(wèn)該表格的時(shí)候需要加上前綴global_temp
b、需要通過(guò)sparkSession.sql方法來(lái)運(yùn)行你的SQL語(yǔ)句
DataSet查詢方式
定義一個(gè)DataSet,先定義一個(gè)Case類
三、DataFrame、Dataset和RDD互操作
RDD-》DataFrame
普通方式:例如rdd.map(para(para(0).trim(),para(1).trim().toInt)).toDF(“name”,“age”)
通過(guò)反射來(lái)設(shè)置schema,例如:
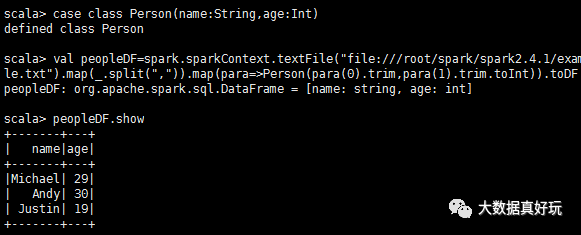
#通過(guò)反射設(shè)置schema,數(shù)據(jù)集是spark自帶的people.txt,路徑在下面的代碼中case class Person(name:String,age:Int)
val peopleDF=spark.sparkContext.textFile(“file:///root/spark/spark2.4.1/examples/src/main/resources/people.txt”).map(_.split(“,”)).map(para=》Person(para(0).trim,para(1).trim.toInt)).toDF
peopleDF.show
#注冊(cè)成一張臨時(shí)表
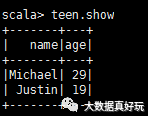
peopleDF.createOrReplaceTempView(“persons”)
val teen=spark.sql(“select name,age from persons where age between 13 and 29”)
teen.show
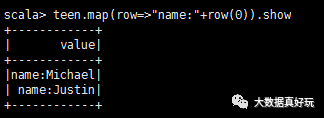
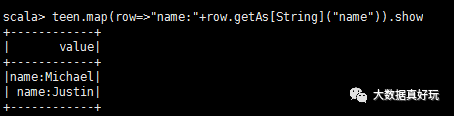
這時(shí)teen是一張表,每一行是一個(gè)row對(duì)象,如果需要訪問(wèn)Row對(duì)象中的每一個(gè)元素,可以通過(guò)下標(biāo) row(0);你也可以通過(guò)列名 row.getAs[String](“name”)
也可以使用getAs方法:
3、通過(guò)編程的方式來(lái)設(shè)置schema,適用于編譯器不能確定列的情況
val peopleRDD=spark.sparkContext.textFile(“file:///root/spark/spark2.4.1/examples/src/main/resources/people.txt”)
val schemaString=“name age”
val filed=schemaString.split(“ ”).map(filename=》 org.apache.spark.sql.types.StructField(filename,org.apache.spark.sql.types.StringType,nullable = true))
val schema=org.apache.spark.sql.types.StructType(filed)
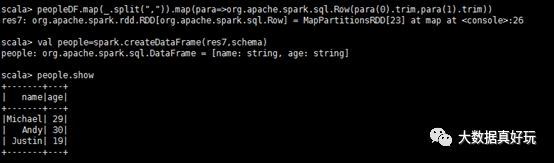
peopleRDD.map(_.split(“,”)).map(para=》org.apache.spark.sql.Row(para(0).trim,para(1).trim))
val peopleDF=spark.createDataFrame(res6,schema)
peopleDF.show


DataFrame-》RDD
dataFrame.rdd
RDD-》DataSet
rdd.map(para=》 Person(para(0).trim(),para(1).trim().toInt)).toDS
DataSet-》DataSet
dataSet.rdd
DataFrame -》 DataSet
dataFrame.to[Person]
DataSet -》 DataFrame
dataSet.toDF
四、用戶自定義函數(shù)
用戶自定義UDF函數(shù)
通過(guò)spark.udf功能用戶可以自定義函數(shù)
自定義udf函數(shù):
通過(guò)spark.udf.register(name,func)來(lái)注冊(cè)一個(gè)UDF函數(shù),name是UDF調(diào)用時(shí)的標(biāo)識(shí)符,fun是一個(gè)函數(shù),用于處理字段。
需要將一個(gè)DF或者DS注冊(cè)為一個(gè)臨時(shí)表
通過(guò)spark.sql去運(yùn)行一個(gè)SQL語(yǔ)句,在SQL語(yǔ)句中可以通過(guò)name(列名)方式來(lái)應(yīng)用UDF函數(shù)
用戶自定義聚合函數(shù)
1. 弱類型用戶自定義聚合函數(shù)
新建一個(gè)Class 繼承UserDefinedAggregateFunction ,然后復(fù)寫方法:
//聚合函數(shù)需要輸入?yún)?shù)的數(shù)據(jù)類型
override def inputSchema: StructType = ???
//可以理解為保存聚合函數(shù)業(yè)務(wù)邏輯數(shù)據(jù)的一個(gè)數(shù)據(jù)結(jié)構(gòu)
override def bufferSchema: StructType = ???
// 返回值的數(shù)據(jù)類型
override def dataType: DataType = ???
// 對(duì)于相同的輸入一直有相同的輸出
override def deterministic: Boolean = true
//用于初始化你的數(shù)據(jù)結(jié)構(gòu)
override def initialize(buffer: MutableAggregationBuffer): Unit = ???
//用于同分區(qū)內(nèi)Row對(duì)聚合函數(shù)的更新操作
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = ???
//用于不同分區(qū)對(duì)聚合結(jié)果的聚合。
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = ???
//計(jì)算最終結(jié)果
override def evaluate(buffer: Row): Any = ???
你需要通過(guò)spark.udf.resigter去注冊(cè)你的UDAF函數(shù)。
需要通過(guò)spark.sql去運(yùn)行你的SQL語(yǔ)句,可以通過(guò) select UDAF(列名) 來(lái)應(yīng)用你的用戶自定義聚合函數(shù)。
2、強(qiáng)類型用戶自定義聚合函數(shù)
新建一個(gè)class,繼承Aggregator[Employee, Average, Double],其中Employee是在應(yīng)用聚合函數(shù)的時(shí)候傳入的對(duì)象,Average是聚合函數(shù)在運(yùn)行的時(shí)候內(nèi)部需要的數(shù)據(jù)結(jié)構(gòu),Double是聚合函數(shù)最終需要輸出的類型。這些可以根據(jù)自己的業(yè)務(wù)需求去調(diào)整。復(fù)寫相對(duì)應(yīng)的方法:
//用于定義一個(gè)聚合函數(shù)內(nèi)部需要的數(shù)據(jù)結(jié)構(gòu)
override def zero: Average = ???
//針對(duì)每個(gè)分區(qū)內(nèi)部每一個(gè)輸入來(lái)更新你的數(shù)據(jù)結(jié)構(gòu)
override def reduce(b: Average, a: Employee): Average = ???
//用于對(duì)于不同分區(qū)的結(jié)構(gòu)進(jìn)行聚合
override def merge(b1: Average, b2: Average): Average = ???
//計(jì)算輸出
override def finish(reduction: Average): Double = ???
//用于數(shù)據(jù)結(jié)構(gòu)他的轉(zhuǎn)換
override def bufferEncoder: Encoder[Average] = ???
//用于最終結(jié)果的轉(zhuǎn)換
override def outputEncoder: Encoder[Double] = ???
新建一個(gè)UDAF實(shí)例,通過(guò)DF或者DS的DSL風(fēng)格語(yǔ)法去應(yīng)用。
五、Spark SQL和Hive的繼承
1、內(nèi)置Hive
Spark內(nèi)置有Hive,Spark2.1.1 內(nèi)置的Hive是1.2.1。
需要將core-site.xml和hdfs-site.xml 拷貝到spark的conf目錄下。如果Spark路徑下發(fā)現(xiàn)metastore_db,需要?jiǎng)h除【僅第一次啟動(dòng)的時(shí)候】。
在你第一次啟動(dòng)創(chuàng)建metastore的時(shí)候,你需要指定spark.sql.warehouse.dir這個(gè)參數(shù), 比如:bin/spark-shell --conf spark.sql.warehouse.dir=hdfs://master01:9000/spark_warehouse
注意,如果你在load數(shù)據(jù)的時(shí)候,需要將數(shù)據(jù)放到HDFS上。
2、外部Hive(這里主要使用這個(gè)方法)
需要將hive-site.xml 拷貝到spark的conf目錄下。
如果hive的metestore使用的是mysql數(shù)據(jù)庫(kù),那么需要將mysql的jdbc驅(qū)動(dòng)包放到spark的jars目錄下。
可以通過(guò)spark-sql或者spark-shell來(lái)進(jìn)行sql的查詢。完成和hive的連接。

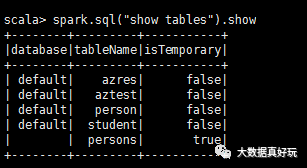
這就是hive里面的表
六、Spark SQL的數(shù)據(jù)源
1、輸入
對(duì)于Spark SQL的輸入需要使用sparkSession.read方法
通用模式 sparkSession.read.format(“json”).load(“path”) 支持類型:parquet、json、text、csv、orc、jdbc
專業(yè)模式 sparkSession.read.json、 csv 直接指定類型。
2、輸出
對(duì)于Spark SQL的輸出需要使用 sparkSession.write方法
通用模式 dataFrame.write.format(“json”).save(“path”) 支持類型:parquet、json、text、csv、orc
專業(yè)模式 dataFrame.write.csv(“path”) 直接指定類型
如果你使用通用模式,spark默認(rèn)parquet是默認(rèn)格式、sparkSession.read.load 加載的默認(rèn)是parquet格式dataFrame.write.save也是默認(rèn)保存成parquet格式。
如果需要保存成一個(gè)text文件,那么需要dataFrame里面只有一列(只需要一列即可)。
七、Spark SQL實(shí)戰(zhàn)
1、數(shù)據(jù)說(shuō)明
這里有三個(gè)數(shù)據(jù)集,合起來(lái)大概有幾十萬(wàn)條數(shù)據(jù),是關(guān)于貨品交易的數(shù)據(jù)集。

2、任務(wù)
這里有三個(gè)需求:
計(jì)算所有訂單中每年的銷售單數(shù)、銷售總額
計(jì)算所有訂單每年最大金額訂單的銷售額
計(jì)算所有訂單中每年最暢銷貨品
3、步驟
1. 加載數(shù)據(jù)
tbStock.txt
#代碼case class tbStock(ordernumber:String,locationid:String,dateid:String) extends Serializable
val tbStockRdd=spark.sparkContext.textFile(“file:///root/dataset/tbStock.txt”)
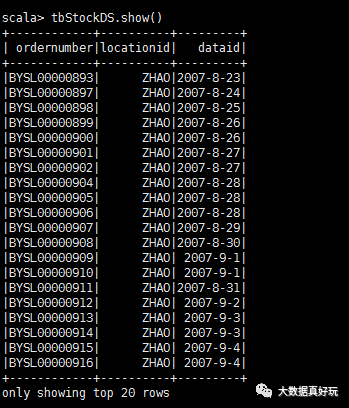
val tbStockDS=tbStockRdd.map(_.split(“,”)).map(attr=》tbStock(attr(0),attr(1),attr(2))).toDS
tbStockDS.show()



tbStockDetail.txt
case class tbStockDetail(ordernumber:String,rownum:Int,itemid:String,number:Int,price:Double,amount:Double) extends Serializable
val tbStockDetailRdd=spark.sparkContext.textFile(“file:///root/dataset/tbStockDetail.txt”)
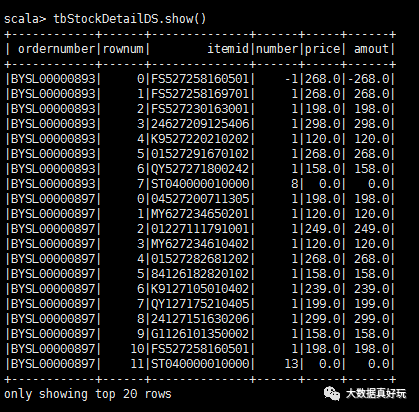
val tbStockDetailDS=tbStockDetailRdd.map(_.split(“,”)).map(attr=》tbStockDetail(attr(0),attr(1).trim().toInt,attr(2),attr(3).trim().toInt,attr(4).trim().toDouble,attr(5).trim().toDouble)).toDS
tbStockDetailDS.show()



tbDate.txt
case class tbDate(dateid:String,years:Int,theyear:Int,month:Int,day:Int,weekday:Int,week:Int,quarter:Int,period:Int,halfmonth:Int) extends Serializable
val tbDateRdd=spark.sparkContext.textFile(“file:///root/dataset/tbDate.txt”)
val tbDateDS=tbDateRdd.map(_.split(“,”)).map(attr=》tbDate(attr(0),attr(1).trim().toInt,attr(2).trim().toInt,attr(3).trim().toInt,attr(4).trim().toInt,attr(5).trim().toInt,attr(6).trim().toInt,attr(7).trim().toInt,attr(8).trim().toInt,attr(9).trim().toInt)).toDS
tbDateDS.show()



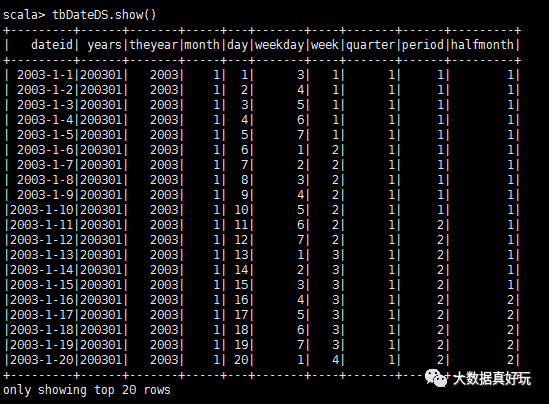
2. 注冊(cè)表
tbStockDS.createOrReplaceTempView(“tbStock”)
tbDateDS.createOrReplaceTempView(“tbDate”)
tbStockDetailDS.createOrReplaceTempView(“tbStockDetail”)

3. 解析表
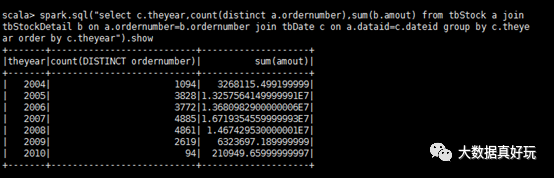
計(jì)算所有訂單中每年的銷售單數(shù)、銷售總額
#sql語(yǔ)句
select c.theyear,count(distinct a.ordernumber),sum(b.amount)
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear
order by c.theyear
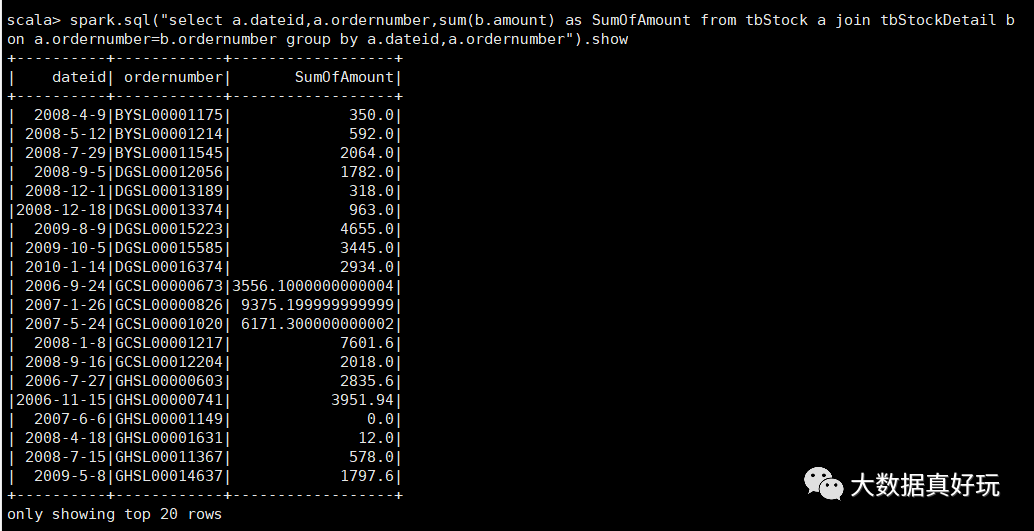
計(jì)算所有訂單每年最大金額訂單的銷售額
a、先統(tǒng)計(jì)每年每個(gè)訂單的銷售額
select a.dateid,a.ordernumber,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
group by a.dateid,a.ordernumber
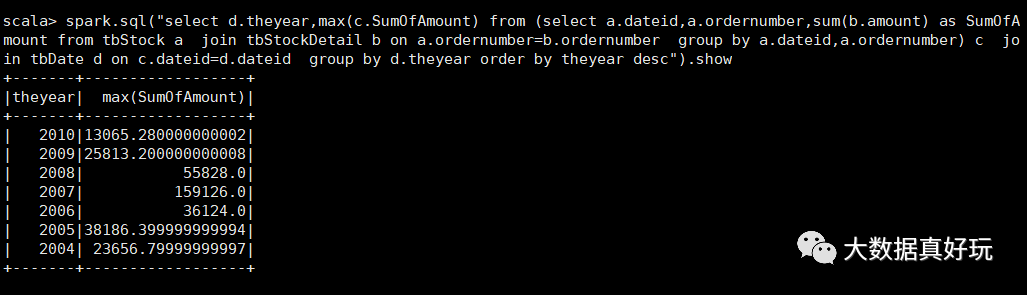
b、計(jì)算最大金額訂單的銷售額
select d.theyear,c.SumOfAmount as SumOfAmount
from
(select a.dateid,a.ordernumber,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
group by a.dateid,a.ordernumber) c
join tbDate d on c.dateid=d.dateid
group by d.theyear
order by theyear desc
計(jì)算所有訂單中每年最暢銷貨品
a、求出每年每個(gè)貨品的銷售額
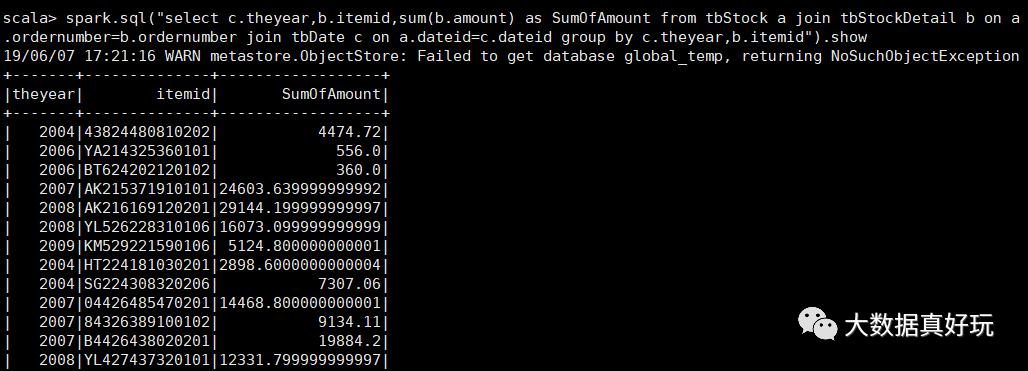
select c.theyear,b.itemid,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid
b、在a的基礎(chǔ)上,統(tǒng)計(jì)每年單個(gè)貨品的最大金額
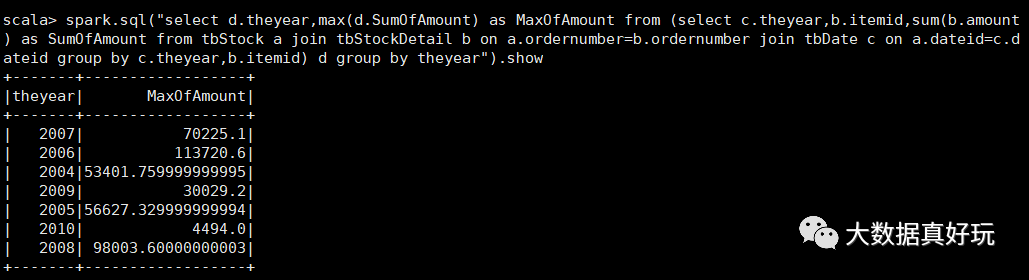
select d.theyear,max(d.SumOfAmount) as MaxOfAmount
from
(select c.theyear,b.itemid,sum(b.amount) as SumOfAmount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid) d
group by theyear
c、用最大銷售額和統(tǒng)計(jì)好的每個(gè)貨品的銷售額join,以及用年join,集合得到最暢銷貨品那一行信息
select distinct e.theyear,e.itemid,f.maxofamount
from
(select c.theyear,b.itemid,sum(b.amount) as sumofamount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid) e
join
(select d.theyear,max(d.sumofamount) as maxofamount
from
(select c.theyear,b.itemid,sum(b.amount) as sumofamount
from tbStock a
join tbStockDetail b on a.ordernumber=b.ordernumber
join tbDate c on a.dateid=c.dateid
group by c.theyear,b.itemid) d
group by d.theyear) f on e.theyear=f.theyear
and e.sumofamount=f.maxofamount order by e.theyear

編輯:jq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7239瀏覽量
90971 -
SQL
+關(guān)注
關(guān)注
1文章
780瀏覽量
44795 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4367瀏覽量
64136 -
RDD
+關(guān)注
關(guān)注
0文章
7瀏覽量
8074
原文標(biāo)題:Spark SQL 重點(diǎn)知識(shí)總結(jié)
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何一眼定位SQL的代碼來(lái)源:一款SQL染色標(biāo)記的簡(jiǎn)易MyBatis插件

Devart: dbForge Compare Bundle for SQL Server—比較SQL數(shù)據(jù)庫(kù)最簡(jiǎn)單、最準(zhǔn)確的方法
dbForge Studio For SQL Server:用于有效開發(fā)的最佳SQL Server集成開發(fā)環(huán)境
創(chuàng)建唯一索引的SQL命令和技巧
淺談SQL優(yōu)化小技巧
不用編程不用電腦,快速實(shí)現(xiàn)多臺(tái)Modbus協(xié)議的PLC、智能儀表對(duì)接SQL數(shù)據(jù)庫(kù)
SQL與NoSQL的區(qū)別
大數(shù)據(jù)從業(yè)者必知必會(huì)的Hive SQL調(diào)優(yōu)技巧
spark為什么比mapreduce快?
S參數(shù)的概念及應(yīng)用
IP 地址在 SQL 注入攻擊中的作用及防范策略
什么是 Flink SQL 解決不了的問(wèn)題?
spark運(yùn)行的基本流程
Spark基于DPU的Native引擎算子卸載方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論