 怎樣去增強PLM對于實體和實體間關系的理解?
怎樣去增強PLM對于實體和實體間關系的理解?
近年來,預訓練語言模型(PLM)在各種下游自然語言處理任務中表現出卓越的性能,受益于預訓練階段的自監督學習目標,PLM 可以有效地捕獲文本中的語法和語義,并為下游 NLP 任務提供蘊含豐富信息的語言表示。然而,傳統的預訓練目標并沒有對文本中的關系事實進行建模,而這些關系事實對于文本理解至關重要。
在這篇被ACL 2021主會錄用的文章中,清華大學聯合騰訊微信模式識別中心與伊利諾伊大學厄巴納香檳分校(UIUC),提出了一種新穎的對比學習框架ERICA,幫助PLM深入了解文本中的實體及實體間關系。具體來說,作者提出了兩個輔助性預訓練任務來幫助PLM更好地理解實體和實體間關系:(1)實體區分任務,給定頭實體和關系,推斷出文本中正確的尾實體;(2)關系判別任務,區分兩個關系在語義上是否接近,這在長文本情景下涉及復雜的關系推理。實驗結果表明,ERICA在不引入額外神經網絡參數的前提下,僅僅對PLM進行少量的額外訓練,就可以提升典型PLM(例如BERT 和 RoBERTa)在多種自然語言理解任務上(包括關系抽取、實體類別區分、問題回答等)的性能。尤其是在低資源(low-resource)的設定下,性能的提升更加明顯。
一、問題背景
傳統的預訓練目標沒有對文本中的關系事實進行顯式建模,而這些關系事實對于理解文本至關重要。為了解決這個問題,一些研究人員試圖改進 PLM 的架構、預訓練任務等,以更好地理解實體之間的關系。但是它們通常只對文本中的句子級別的單個關系進行建模,不僅忽略了長文本場景下多個實體之間的復雜關系,也忽略了對實體本身的理解,例如圖1中所展現的,對于長文本來說,為了讓PLM更加充分理解地單個實體,我們需要考慮該實體和其他實體之間的復雜關系;而這些復雜的關系的理解通常涉及復雜的推理鏈,往往需要綜合多個句子的信息得出結論。針對這兩個痛點,本文提出了實體區分任務和關系區分任務來增強PLM對于實體和實體間關系的理解。
二 、文檔級預訓練數據收集
ERICA的訓練依賴于大規模文檔級遠程監督數據,該數據的構造有三個階段:首先從wikipedia中爬取文本段落,然后用命名實體識別工具(例如spacy)進行實體標注,將所有獲得的實體和wikidata中標注的實體對應上,并利用遠程監督(distant supervision)信號獲得實體之間可能存在的關系,最終保留長度在128到512之間,含有多于4個實體,實體間多于4個遠程監督關系的段落。注意這些遠程監督的關系中存在大量的噪聲,而大規模的預訓練可以一定程度上實現降噪。作者也開源了由100萬個文檔組成的大規模遠程監督預訓練數據。
三 、實體與實體間關系的表示
鑒于每個實體可能在段落中出現多次,并且每次出現時對應的描述(mention)可能也不一樣,作者在使用PLM對tokenize后的段落進行編碼后,取每個描述的所有token均勻池化后的結果作為該描述的表示,接著對于全文中該實體所有的描述進行第二次均勻池化,得到該實體在該文檔中的表示;對于兩個實體,它們之間的關系表示為兩個實體表示的簡單拼接。以上是最簡單的實體/實體間關系的表示方法,不需要引入額外的神經網絡參數。作者在文中還探索了其它的表示方法,并驗證了所有方法相比baseline都有一致的提升。
四 、實體區分任務
實體區分任務旨在給定頭實體和關系,從當前文檔中尋找正確的尾實體。例如在上圖中,Sinaloa和Mexico具有country的遠程關系,于是作者將關系country和頭實體Sinaloa拼接在原文檔的前面作為提示(prompt),在此條件下區分正確的尾實體的任務可以在對比學習的框架下轉換成拉近頭實體和正確尾實體的實體表示的距離,推遠頭實體和文檔中其它實體(負樣本)的實體表示的距離,具體的公式如下所示:
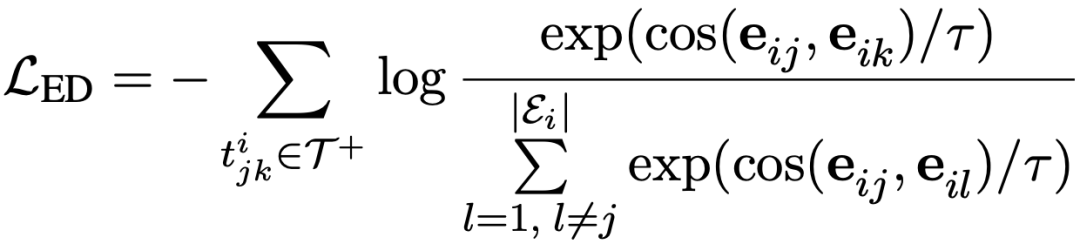
五、關系區分任務
關系區分任務旨在區分兩個關系的表示在語義空間上的相近程度。由于作者采用文檔級而非句子級的遠程監督,文檔中的關系區分涉及復雜的推理鏈。具體而言,作者隨機采樣多個文檔,并從每個文檔中得到多個關系表示,這些關系可能只涉及句子級別的推理,也可能涉及跨句子的復雜推理。之后基于對比學習框架,根據遠程監督的標簽在關系空間中對不同的關系表示進行訓練,如前文所述,每個關系表示均由文檔中的兩個實體表示構成。正樣本即具有相同遠程監督標簽的關系表示,負樣本與此相反。作者在實驗中還發現進一步引入不具有遠程監督關系的實體對作為負樣本可以進一步提升模型效果。由于進行對比訓練的兩個關系表示可能來自于多個文檔,也可能來自于單個文檔,因此文檔間/跨文檔的關系表示交互都得到了實現。巧妙的是,對于涉及復雜推理的關系,該方法不需要顯示地構建推理鏈,而是“強迫”模型理解這些關系并在頂層的關系語義空間中區分這些關系。具體的公式如下所示:
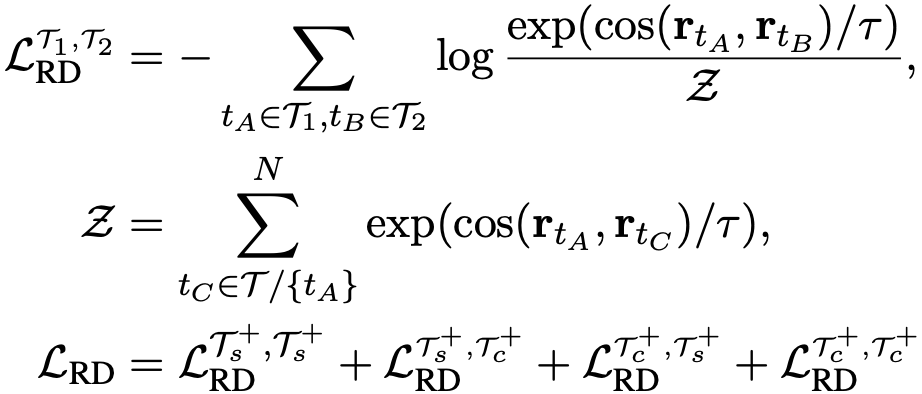
為了避免災難性遺忘,作者將上述兩個任務同masked language modeling (MLM)任務一起訓練,總的訓練目標如下所示:
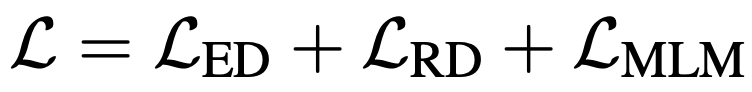
六、實驗結果
ERICA的訓練不需要引入除了PLM之外的任何參數,并且對于任意模型均能夠適配,具體的,作者采用了兩個經典的PLM:BERT和RoBERTa,并對其進行一定時間的post-training,最后在文檔級關系抽取、實體類別區分、問題回答等任務上進行了測試,并對比了例如CorefBERT, SpanBERT, ERNIE, MTB,CP等基線模型,驗證了ERICA框架的有效性。具體結果如下:
a) 文檔級關系抽取,模型需要區分文檔中的多個實體之間的關系,這需要PLM對實體間關系有較好的理解。
b) 實體類別區分,模型需要區分文本中的實體的具體類別,這需要PLM對實體本身有較好的理解。
c) 問題回答,作者測試了兩種常見的問題回答任務:多選問答(multi-choice QA)和抽取式問答(extractive QA)。這需要PLM對實體和實體間關系有較好的理解。
七、分析
a) 消融分析(ablation study)。作者對ERICA框架中的所有組成成分進行了細致的分析,并證明了這些組成成分對于模型整體效果的提升是缺一不可的。
b) 可視化分析。作者對經過ERICA訓練前后的PLM對實體和實體間關系的表示進行了可視化,結果如下圖所示。通過ERICA的對比學習訓練,PLM對于同類別的實體/實體關系的表示有明顯的聚類現象,這充分驗證了ERICA能夠顯著增強PLM對實體和實體間關系的理解。
c) 此外,作者分析了遠程監督關系的多樣性/預訓練文檔數量對于模型效果的提升。實驗結果發現,更加多樣的遠程監督關系與更大的預訓練數據集對于性能的提升有積極的作用。
d) 除了使用均勻池化的方式來獲得實體/關系表示,作者也嘗試使用entity marker的表示方法來測試模型的性能。實驗結果證明,ERICA對各種實體/關系表示方法均適用,進一步驗證了該架構的通用性。
八、總結
在本文中,作者提出了ERICA框架,通過對比學習幫助PLM提高實體和實體間關系的理解。作者在多個自然語言理解任務上驗證了該框架的有效性,包括關系提取、實體類別區分和問題問答。實驗結果表明ERICA顯著優于所有基線模型,尤其是在低資源的設定下,這意味著 ERICA 可以更好地幫助 PLM捕獲文本中的相關事實并綜合有關實體及其關系的信息。
責任編輯:lq6
-
PLM
+關注
關注
2文章
132瀏覽量
21273 -
實體
+關注
關注
0文章
8瀏覽量
7356
原文標題:ERICA: 提升預訓練語言模型實體與關系理解的統一框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何在MQTT中發布和訂閱實體
藍牙技術聯盟正式成立中國實體,擴展全球市場布局

探秘定制鋰電池實體店:開啟專屬電力新體驗

研發數據管理:從前PLM時代的Excel到PLM3.0、PLM 4.0
半導體企業回應美國出口管制 多家A股公司談實體清單影響
如何使用ar增強現實體驗
南方智能推出三維地理實體生產軟件
PLM系統 PLM軟件 PLM項目管理系統軟件 PLM產品生命周期管理系統哪個好?
傳音控股入選2023新型實體企業TOP100
立訊精密上榜《2023新型實體企業TOP100》
一站式解決企業難題:彩虹PLM系統引領企業管理革新

信號的時域波形和頻譜間的關系是什么
如何學習智能家居?8:Text文本實體使用方法

智能家居之旅(9):HomeAssistant 的開關實體具象化






 工商網監
工商網監
評論