 關于深度學習被濫用的調查淺析
關于深度學習被濫用的調查淺析
在某些情況下,神經網絡之類模型的表現可能會勝過更簡單的模型,但很多情況下事情并不是這樣的。
打個比方:假設你需要購買某種交通工具來跑運輸,如果你經常需要長距離運輸大型物品,那么, 購買卡車是很劃算的投資;但如果你只是要去本地超市買點牛奶,那么買一輛卡車就太浪費了。一輛汽車(如果你關心氣候變化的話,甚至可以買一輛自行車)也足以完成上述任務。
深度學習的使用場景也開始遇到這種問題了:我們假設它們的性能優于簡單模型,然后把相關數據一股腦兒地塞給它們。此外,我們在應用這些模型時往往并沒有對相關數據有適當的理解;比如說我們沒有意識到,如果對數據有直觀的了解,就不必進行深度學習。
任何模型被裝在黑匣子里來分析數據時,總是會存在危險,深度學習家族的模型也不例外。
時間序列分析我最常用的是時間序列分析,因此我們來考慮一個這方面的例子。
假設一家酒店希望預測其在整個客戶群中收取的平均每日費用(或每天的平均費用)——ADR。每位客戶的平均每日費用是每周開銷的平均值。
LSTM 模型的配置如下:
model.add(LSTM(4, input_shape=(1, lookback)))
model.add(Dense(1))
model.compile(loss=‘mean_squared_error’, optimizer=‘adam’)
history=model.fit(X_train, Y_train, validation_split=0.2, epochs=100, batch_size=1, verbose=2)
下面是預測與實際的每周 ADR:
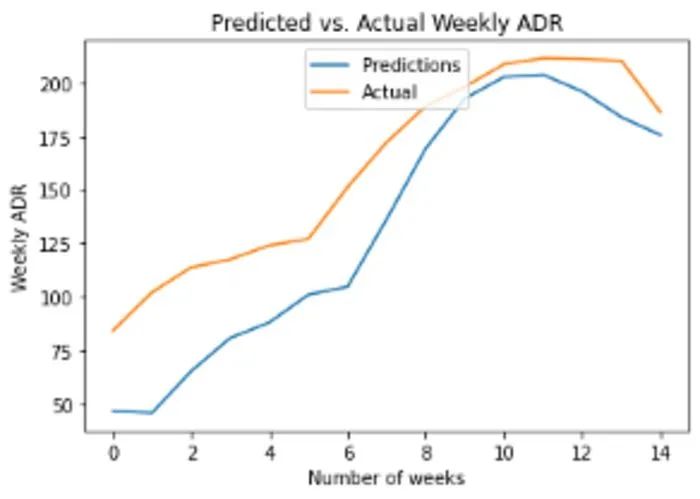
獲得的 RMSE 為 31,均值 160。RMSE(均方根誤差)的大小是平均 ADR 大小的 20%。誤差并不算高,但不得不承認,神經網絡的目的是盡可能獲得比其他模型更高的準確度,所以這個結果還是有些令人失望。
此外,這個 LSTM 模型是一個一步預測——意味著如果沒有可用的時間 t 之前的所有數據,該模型就無法進行長期預測。
也就是說,我們是不是太急著對數據應用 LSTM 模型了呢?
我們先回到出發點,首先對數據做一個全面的分析。
下面是 ADR 波動的 7 周移動平均值:
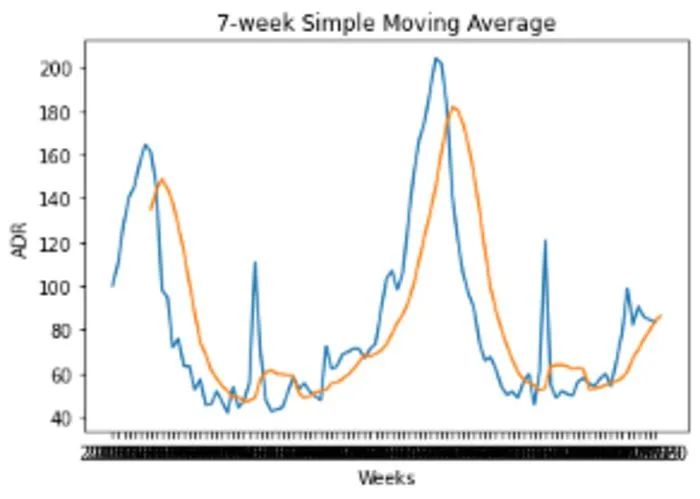
當數據通過 7 周的移動平均值進行平滑處理后,我們可以清楚地看到季節性模式的證據。
我們來仔細看看數據的自相關函數。
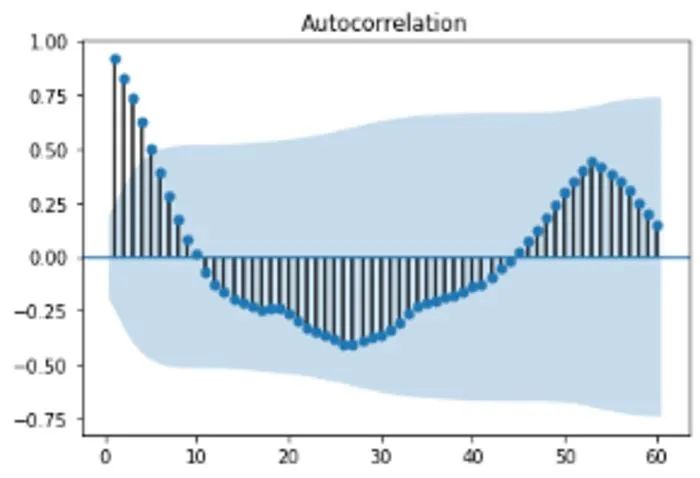
我們可以看到,峰值相關性(在一系列負相關性之后)滯后 52,表明數據中存在年度季節屬性。
有了這一信息后,我們可以使用 pmdarima 配置 ARIMA 模型來預測 ADR 波動的最后 15 周,并自動選擇 p、d、q 坐標以最小化赤池量信息準則。
》》》 Arima_model=pm.auto_arima(train_df, start_p=0, start_q=0, max_p=10, max_q=10, start_P=0, start_Q=0, max_P=10, max_Q=10, m=52, stepwise=True, seasonal=True, information_criterion=‘aic’, trace=True, d=1, D=1, error_action=‘warn’, suppress_warnings=True, random_state = 20, n_fits=30)Performing stepwise search to minimize aic
ARIMA(0,1,0)(0,1,0)[52] : AIC=422.399, Time=0.27 sec
ARIMA(1,1,0)(1,1,0)[52] : AIC=inf, Time=16.12 sec
ARIMA(0,1,1)(0,1,1)[52] : AIC=inf, Time=19.08 sec
ARIMA(0,1,0)(1,1,0)[52] : AIC=inf, Time=14.55 sec
ARIMA(0,1,0)(0,1,1)[52] : AIC=inf, Time=11.94 sec
ARIMA(0,1,0)(1,1,1)[52] : AIC=inf, Time=16.47 sec
ARIMA(1,1,0)(0,1,0)[52] : AIC=414.708, Time=0.56 sec
ARIMA(1,1,0)(0,1,1)[52] : AIC=inf, Time=15.98 sec
ARIMA(1,1,0)(1,1,1)[52] : AIC=inf, Time=20.41 sec
ARIMA(2,1,0)(0,1,0)[52] : AIC=413.878, Time=1.01 sec
ARIMA(2,1,0)(1,1,0)[52] : AIC=inf, Time=22.19 sec
ARIMA(2,1,0)(0,1,1)[52] : AIC=inf, Time=25.80 sec
ARIMA(2,1,0)(1,1,1)[52] : AIC=inf, Time=28.23 sec
ARIMA(3,1,0)(0,1,0)[52] : AIC=414.514, Time=1.13 sec
ARIMA(2,1,1)(0,1,0)[52] : AIC=415.165, Time=2.18 sec
ARIMA(1,1,1)(0,1,0)[52] : AIC=413.365, Time=1.11 sec
ARIMA(1,1,1)(1,1,0)[52] : AIC=415.351, Time=24.93 sec
ARIMA(1,1,1)(0,1,1)[52] : AIC=inf, Time=21.92 sec
ARIMA(1,1,1)(1,1,1)[52] : AIC=inf, Time=30.36 sec
ARIMA(0,1,1)(0,1,0)[52] : AIC=411.433, Time=0.59 sec
ARIMA(0,1,1)(1,1,0)[52] : AIC=413.422, Time=11.57 sec
ARIMA(0,1,1)(1,1,1)[52] : AIC=inf, Time=23.39 sec
ARIMA(0,1,2)(0,1,0)[52] : AIC=413.343, Time=0.82 sec
ARIMA(1,1,2)(0,1,0)[52] : AIC=415.196, Time=1.63 sec
ARIMA(0,1,1)(0,1,0)[52] intercept : AIC=413.377, Time=1.04 sec
Best model: ARIMA(0,1,1)(0,1,0)[52]
Total fit time: 313.326 seconds
根據上面的輸出,ARIMA(0,1,1)(0,1,0)[52] 是 AIC 的最佳擬合模型。使用這個模型,對于 160 的平均 ADR,可獲得 10 的 RMSE。
這比 LSTM 實現的 RMSE 要低得多(這是一件好事),僅占均值大小的 6%多。
對數據進行適當的分析后,人們會認識到,數據中存在的年度季節屬性可以讓時間序列更具可預測性,而使用深度學習模型來嘗試預測這種屬性在很大程度上是多余的。
回歸分析:預測客戶 ADR 值我們換個角度來討論上述問題。
現在我們不再嘗試預測平均每周 ADR,而是嘗試預測每個客戶的 ADR 值。
為此我們使用兩個基于回歸的模型:
線性 SVM(支持向量機)
基于回歸的神經網絡
兩種模型均使用以下特征來預測每個客戶的 ADR 值:
country:客戶的原籍國
marketsegment:客戶的細分市場
deposittype:客戶是否已支付訂金
customertype:客戶類型
rcps:所需的停車位
arrivaldateweekno:到達的星期數
我們使用平均絕對誤差作為效果指標,來對比兩個模型相對于平均值獲得的 MAE。
線性支持向量機這里定義了 epsilon 為 0.5 的 LinearSVR,并使用訓練數據進行了訓練:
svm_reg_05 = LinearSVR(epsilon=0.5)
svm_reg_05.fit(X_train, y_train)
現在使用測試集中的特征值進行預測:
》》》 svm_reg_05.predict(atest)array([ 81.7431138 , 107.46098525, 107.46098525, 。.., 94.50144931,
94.202052 , 94.50144931])
這是相對于均值的均值絕對誤差:
》》》 mean_absolute_error(btest, bpred)
30.332614341027753》》》 np.mean(btest)
105.30446539770578
MAE 是均值大小的 28%。讓我們看看基于回歸的神經網絡是否可以做得更好。
基于回歸的神經網絡神經網絡的定義如下:
model = Sequential()
model.add(Dense(8, input_dim=8, kernel_initializer=‘normal’, activation=‘elu’))
model.add(Dense(2670, activation=‘elu’))
model.add(Dense(1, activation=‘linear’))
model.summary()
使用的批大小是 150,用 30 個 epoch 訓練模型:
model.compile(loss=‘mse’, optimizer=‘adam’, metrics=[‘mse’,‘mae’])
history=model.fit(xtrain_scale, ytrain_scale, epochs=30, batch_size=150, verbose=1, validation_split=0.2)
predictions = model.predict(xval_scale)
現在將測試集的特征輸入到模型中,以下是 MAE 和平均值:
》》》 mean_absolute_error(btest, bpred)
28.908454264679218》》》 np.mean(btest)
105.30446539770578
我們看到,MAE 僅僅比使用 SVM 所獲得的 MAE 低一點。因此,當線性 SVM 模型顯示出幾乎相同的準確度時,很難證明使用神經網絡來預測客戶 ADR 是合適的選項。
無論如何,用于“解釋”ADR 的特征選擇之類的因素比模型本身有著更大的相關性。俗話說,“進垃圾,出垃圾”。如果特征選取很爛,模型輸出也會很差。
在上面這個例子里,盡管兩個回歸模型都顯示出一定程度的預測能力,但很可能要么 1)選擇數據集中的其他特征可以進一步提高準確性,要么 2)ADR 的變量太多,對數據集中特征的影響太大。例如,數據集沒有告訴我們關于每個客戶收入水平的任何信息,這些因素將極大地影響他們每天的平均支出。
結論
在上面的兩個示例中我們已經看到,使用“更輕”的模型已經能夠匹配(或超過)深度學習模型所實現的準確性。
在某些情況下,數據可能非常復雜,需要“從頭開始”在數據中使用算法學習模式,但這往往是例外,而不是規則。
對于任何數據科學問題,關鍵是首先要了解我們正在使用的數據,模型的選擇往往是次要的。
可以在此處找到上述示例的數據集和 Jupyter 筆記本。
編輯:lyn
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102889 -
深度學習
+關注
關注
73文章
5555瀏覽量
122515
原文標題:深度學習正在被濫用
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論