") 信息檢索對(duì)話(huà)中ConversationShape框架介紹
信息檢索對(duì)話(huà)中ConversationShape框架介紹
參與混合主動(dòng)互動(dòng)的能力是會(huì)話(huà)搜索系統(tǒng)的核心要求之一。如何做到這一點(diǎn),人們知之甚少。我們提出了一組無(wú)監(jiān)督的度量標(biāo)準(zhǔn),稱(chēng)作ConversationShape,通過(guò)比較詞匯和話(huà)語(yǔ)類(lèi)型的分布來(lái)強(qiáng)調(diào)每個(gè)會(huì)話(huà)參與者所扮演的角色。以ConversationShape為標(biāo)準(zhǔn),仔細(xì)地研究了幾個(gè)會(huì)話(huà)搜索數(shù)據(jù)集,并將它們與其他對(duì)話(huà)數(shù)據(jù)集進(jìn)行比較,以便更好地理解它們所代表的對(duì)話(huà)交互類(lèi)型,無(wú)論是由信息搜索者還是助手驅(qū)動(dòng)的。我們發(fā)現(xiàn),同一類(lèi)型的人與人對(duì)話(huà)的對(duì)話(huà)形態(tài)與ConversationShape之間的偏離,可以預(yù)測(cè)人與機(jī)器對(duì)話(huà)的質(zhì)量。
1. 簡(jiǎn)介
雖然會(huì)話(huà)搜索的想法已經(jīng)存在了幾十年,但這個(gè)想法最近引起了相當(dāng)大的關(guān)注。會(huì)話(huà)式用戶(hù)界面被認(rèn)為比傳統(tǒng)的界面更有利于有效的信息訪問(wèn)。在這種情況下,對(duì)話(huà)是一種協(xié)作過(guò)程,允許信息尋求者滿(mǎn)足信息需求。會(huì)話(huà)交互的關(guān)鍵特征之一是混合主動(dòng)性的潛力,其中系統(tǒng)和用戶(hù)都可以采取適當(dāng)?shù)闹鲃?dòng)性。在這篇論文中,作者提出了一種分析評(píng)估對(duì)話(huà)參與者之間的主動(dòng)性和協(xié)作程度的指標(biāo)。
迄今為止提出的會(huì)話(huà)搜索任務(wù)主要將對(duì)話(huà)減少為一系列的問(wèn)題-答案對(duì)。在用于問(wèn)答任務(wù)的數(shù)據(jù)集中,交互的結(jié)構(gòu)事先是固定的:要么用戶(hù)主動(dòng),系統(tǒng)隨后給出答案,要么反過(guò)來(lái),這使得它們不適合研究角色之間的主動(dòng)性如何轉(zhuǎn)移。來(lái)自在線問(wèn)答論壇的討論是開(kāi)發(fā)會(huì)話(huà)搜索任務(wù)的一個(gè)流行的數(shù)據(jù)來(lái)源[18,19]。雖然在線論壇是研究現(xiàn)實(shí)世界交互模式的寶貴資源,但它們展示了一種異步信息交換類(lèi)型,正如我們?cè)诜治鲋兴@示的,這與同步對(duì)話(huà)交互非常不同。
會(huì)話(huà)系統(tǒng)通常分為問(wèn)答、任務(wù)導(dǎo)向和閑聊。值得注意的是,這種分類(lèi)模式主要基于構(gòu)建這種對(duì)話(huà)系統(tǒng)的方法的不同,而不是它們產(chǎn)生的對(duì)話(huà)的不同。在本文中,**我們著重分析和測(cè)量對(duì)話(huà)類(lèi)型之間的差異,并報(bào)告由此產(chǎn)生的維度和一個(gè)新的對(duì)話(huà)分類(lèi)方案。**我們表明,為會(huì)話(huà)搜索任務(wù)收集的人對(duì)人對(duì)話(huà)與面向任務(wù)的對(duì)話(huà)和閑聊對(duì)話(huà)在結(jié)構(gòu)上具有相似性。
最近對(duì)聊天對(duì)話(huà)模型的評(píng)估研究表明,對(duì)話(huà)系統(tǒng)傾向于通過(guò)問(wèn)太多的問(wèn)題和忽視用戶(hù)的主動(dòng)性來(lái)控制對(duì)話(huà)[4,9]。標(biāo)準(zhǔn)的評(píng)估指標(biāo)不能捕捉到對(duì)話(huà)互動(dòng)的這一維度,因此不能預(yù)測(cè)用戶(hù)參與度。對(duì)話(huà)評(píng)價(jià)最常用的指標(biāo)是回應(yīng)的相關(guān)性,通常是根據(jù)真實(shí)的回應(yīng)來(lái)衡量;如果響應(yīng)是一個(gè)答案,那么它可以與答案的準(zhǔn)確性相比較。我們的工作是對(duì)這項(xiàng)研究的補(bǔ)充。我們提出了一種新的基于一組無(wú)監(jiān)督特征的評(píng)價(jià)框架。該框架的設(shè)計(jì)目的是在適當(dāng)?shù)臅r(shí)候,根據(jù)平衡主動(dòng)性和衡量對(duì)話(huà)參與者之間的協(xié)作來(lái)捕獲對(duì)話(huà)互動(dòng)的質(zhì)量。
我們的評(píng)估框架是基于幾個(gè)獨(dú)立的詞匯特征,這些詞匯特征捕捉了對(duì)話(huà)中的主動(dòng)性和協(xié)作性。先前采用了基于語(yǔ)篇特征的簡(jiǎn)單自動(dòng)測(cè)量方法,如詞匯和句法多樣性,以減少重復(fù)的共性回答,并估計(jì)問(wèn)題的復(fù)雜性[14,23]。我們使用了一種無(wú)監(jiān)督的方法,類(lèi)似于在匹配[13]語(yǔ)言風(fēng)格和衡量生成敘事[22]的質(zhì)量時(shí)所使用的方法。一個(gè)關(guān)鍵特征的對(duì)話(huà)是。它是一種由多個(gè)對(duì)話(huà)參與者產(chǎn)生的話(huà)語(yǔ)敘事類(lèi)型。因此,我們分別估計(jì)每個(gè)參與者的詞匯特征,以便能夠比較他們的貢獻(xiàn),從而推斷他們?cè)趯?duì)話(huà)中扮演的角色。
我們的對(duì)話(huà)表示方法是無(wú)監(jiān)督和領(lǐng)域獨(dú)立的,這允許我們將以前只在少數(shù)對(duì)話(huà)上執(zhí)行的分析擴(kuò)展到數(shù)千個(gè)公開(kāi)可用的對(duì)話(huà)文本。
我們的主要貢獻(xiàn)可以總結(jié)為:(1)我們?cè)?0個(gè)數(shù)據(jù)集(超過(guò)97k個(gè)對(duì)話(huà))中考察了主動(dòng)性和協(xié)作的結(jié)構(gòu)模式。我們的研究是第一個(gè)在龐大而多樣的對(duì)話(huà)語(yǔ)料庫(kù)中自動(dòng)識(shí)別這些維度的研究,并將源自不同研究團(tuán)體的對(duì)話(huà)任務(wù)進(jìn)行類(lèi)比。(2)我們所識(shí)別的主動(dòng)性和協(xié)作模式與人類(lèi)對(duì)對(duì)話(huà)質(zhì)量的判斷相關(guān)。控制的分配(其中控制被定義為管理會(huì)話(huà)中的流程方向)是旨在增強(qiáng)人機(jī)協(xié)作的混合主動(dòng)對(duì)話(huà)系統(tǒng)的核心。對(duì)話(huà)系統(tǒng)應(yīng)能夠識(shí)別usera??s提示的主動(dòng)切換,從而提供適當(dāng)?shù)幕貞?yīng)。檢測(cè)主動(dòng)性對(duì)于描述交互的質(zhì)量也很重要。我們的工作有助于洞察,為評(píng)估和優(yōu)化方法的設(shè)計(jì)提供信息,這些方法能夠識(shí)別對(duì)話(huà)中的主動(dòng)性分配。
2. ConversationShape
ConversationShape是一種關(guān)注對(duì)話(huà)結(jié)構(gòu)屬性的對(duì)話(huà)表示方法。我們認(rèn)為對(duì)話(huà)是幾個(gè)參與者之間交換的一系列話(huà)語(yǔ)。我們實(shí)驗(yàn)中的所有對(duì)話(huà)都有兩名參與者。然而,我們的方法也適用于多方對(duì)話(huà)。信息尋求對(duì)話(huà)的特點(diǎn)通常是參與者在對(duì)話(huà)中扮演的角色不對(duì)稱(chēng):參與者通常扮演助手(A)的角色,其功能是通過(guò)對(duì)話(huà)搜索系統(tǒng)實(shí)現(xiàn)自動(dòng)化;另一個(gè)對(duì)話(huà)參與者是一個(gè)信息尋求者,他正在使用助手的服務(wù)來(lái)獲取信息。為了模擬對(duì)話(huà)中的混合主動(dòng)性,我們使用了四個(gè)指標(biāo),分別為每個(gè)對(duì)話(huà)參與者計(jì)算:(1)問(wèn)題(question);(2)信息(information);(3)重復(fù)(repetition);和(4)流(flow)。
問(wèn)題(question)是一種試圖控制談話(huà)方向的明確嘗試,因?yàn)樘岢龅膯?wèn)題會(huì)讓另一個(gè)參與者產(chǎn)生相應(yīng)的答案。我們?cè)贜PS聊天語(yǔ)料庫(kù)上訓(xùn)練了一個(gè)有監(jiān)督分類(lèi)器來(lái)識(shí)別問(wèn)題和其他類(lèi)型的話(huà)語(yǔ)。NPS聊天語(yǔ)料庫(kù)包含了來(lái)自網(wǎng)絡(luò)聊天室的7.9K個(gè)話(huà)語(yǔ),標(biāo)注了14種話(huà)語(yǔ)類(lèi)型:Statement、Emotion、Greet、Bye、Accept、Reject、whQuestion、ynQuestion、yAnswer、nAnswer、Emphasis、Continuer、clear、Other。我們的分類(lèi)模型是從預(yù)先訓(xùn)練的羅伯塔17初始化的,并進(jìn)一步為話(huà)語(yǔ)類(lèi)型預(yù)測(cè)任務(wù)進(jìn)行調(diào)整,在遞出測(cè)試集中實(shí)現(xiàn)F1為0.81。
其余的度量標(biāo)準(zhǔn)描述協(xié)作模式和對(duì)對(duì)話(huà)主題的控制。要解釋它們,我們首先需要介紹對(duì)話(huà)詞表的概念。對(duì)話(huà)詞表由出現(xiàn)在同一對(duì)話(huà)文本中的所有唯一單詞(或子單詞標(biāo)記)組成。我們對(duì)在同一對(duì)話(huà)中頻繁出現(xiàn)(不止一次)的單詞特別感興趣,因?yàn)橹貜?fù)模式很可能表明它們對(duì)對(duì)話(huà)主題的重要性。
信息(information)反映了參與者對(duì)談話(huà)主題的貢獻(xiàn)。我們將信息估計(jì)為會(huì)話(huà)參與者首先創(chuàng)造的頻繁令牌的計(jì)數(shù)。
重復(fù)(repetition)表示對(duì)談話(huà)主題的延續(xù)。為了分析共享詞匯表的出現(xiàn),我們跟蹤會(huì)話(huà)參與者之間的詞匯表重用模式。我們將重復(fù)估計(jì)為一個(gè)會(huì)話(huà)參與者首先引入并隨后被另一個(gè)會(huì)話(huà)參與者重復(fù)的標(biāo)記的數(shù)量。我們認(rèn)為重復(fù)是對(duì)話(huà)中可用的一種相關(guān)性反饋,假設(shè)重復(fù)行為是通過(guò)增加標(biāo)記頻率來(lái)認(rèn)可標(biāo)記對(duì)對(duì)話(huà)主題的重要性。另一種隱式引用前面標(biāo)記的方法是使用回指。因此,我們將回指計(jì)數(shù)加到重復(fù)計(jì)數(shù)中。從沃克和惠特克提出的分析框架中,我們使用了一小串英語(yǔ)回指:
“it”,“they”,“they”,“their”,“she”,“he”,“her”,“him”,“his”,“this”,“that”。我們也用現(xiàn)成的共參考分辨率模型進(jìn)行了實(shí)驗(yàn),但結(jié)果并不令人滿(mǎn)意。
“流”(flow)是重復(fù)和信息之間的區(qū)別,它反映了參與者通過(guò)引用之前的陳述來(lái)維持對(duì)話(huà)的連貫性,或者通過(guò)引入新的信息來(lái)推動(dòng)對(duì)話(huà)向前的作用。
對(duì)于每一次對(duì)話(huà),我們分別計(jì)算每個(gè)對(duì)話(huà)參與者的值:conceptA和ConceptS(A代表assistant,S代表Seeker),其中Concept表示我們剛剛介紹的四個(gè)指標(biāo)之一。為了能夠比較不同長(zhǎng)度的對(duì)話(huà),我們還通過(guò)對(duì)話(huà)中說(shuō)話(huà)的數(shù)量來(lái)標(biāo)準(zhǔn)化得分。然后,我們使用兩個(gè)指標(biāo)之間的平均值和差值來(lái)描述數(shù)據(jù)集中對(duì)話(huà)的類(lèi)型。平均值顯示了每個(gè)指標(biāo)的重要性,例如每次對(duì)話(huà)的平均問(wèn)題數(shù)量:
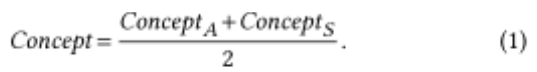
這種差異可以用來(lái)比較對(duì)話(huà)參與者之間的分布(平衡),例如在對(duì)話(huà)中誰(shuí)問(wèn)了更多的問(wèn)題。我們使用類(lèi)似于[13]的寫(xiě)作風(fēng)格的公式:
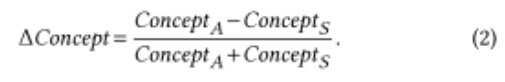
它不僅表明了不同角色之間的指標(biāo)差異,而且還表明了其方向:負(fù)值表示Seeker的主導(dǎo)地位,正值A(chǔ)ssistant表示Assistant的主導(dǎo)地位。
3. 數(shù)據(jù)集
我們的分析跨越了10個(gè)公開(kāi)可用的對(duì)話(huà)數(shù)據(jù)集,這些數(shù)據(jù)集是為各種對(duì)話(huà)任務(wù)而設(shè)計(jì)的。括號(hào)中的數(shù)字表示每個(gè)數(shù)據(jù)集中對(duì)話(huà)的數(shù)量。
4.結(jié)果
表1顯示了前一節(jié)中每個(gè)對(duì)話(huà)集的平均ConversationShape。這種表示允許比較集合并識(shí)別不同的對(duì)話(huà)類(lèi)型,例如,圖1顯示了基于問(wèn)題和信息分布的相似性而出現(xiàn)的集群。
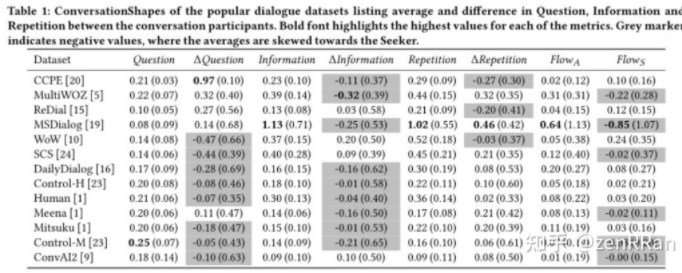
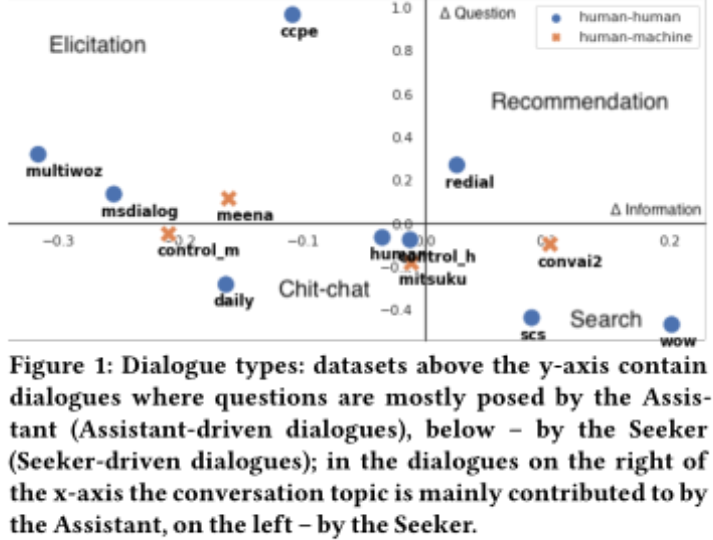
助手驅(qū)動(dòng)對(duì)話(huà)(Assistant-driven dialogues):從表1中我們可以看到,在CCPE中,助理通過(guò)提出問(wèn)題來(lái)引導(dǎo)對(duì)話(huà),探索者通過(guò)回答問(wèn)題來(lái)跟進(jìn)(負(fù)?重復(fù))。MultiWOZ和MSDialog也有助理提出的大部分問(wèn)題,但這些問(wèn)題是緊跟著探索者提供的問(wèn)題和答案(正?重復(fù))。在“ReDial”中,助理通過(guò)提供信息和提問(wèn)來(lái)推動(dòng)對(duì)話(huà),而探索者則繼續(xù)跟進(jìn)(負(fù)?重復(fù))。
探索者驅(qū)動(dòng)對(duì)話(huà)(Seeker-driven dialogue):SCS和WoW的相似之處在于:搜索者主要是提問(wèn),助理主要是提供信息。然而,在WoW中,導(dǎo)引頭會(huì)繼續(xù)跟隨助手介紹的主題(負(fù)?重復(fù)),而在SCS中,助手會(huì)跟隨導(dǎo)引頭。聊天對(duì)話(huà)(Human和Control-H)似乎更接近于起源,表明這種對(duì)話(huà)類(lèi)型的參與者之間的主動(dòng)性更平衡。然而,在DailyDialog數(shù)據(jù)集中,主動(dòng)權(quán)傾向于對(duì)話(huà)發(fā)起者,后者更有可能提出問(wèn)題并設(shè)置對(duì)話(huà)主題。
模型診斷:ConversationShape有助于評(píng)價(jià)對(duì)話(huà)模式,理解對(duì)話(huà)模式所表現(xiàn)出的越軌行為類(lèi)型。這些實(shí)驗(yàn)是在Control-M數(shù)據(jù)集的子集上進(jìn)行的,這些子集對(duì)應(yīng)于不同對(duì)話(huà)模型產(chǎn)生的文本。總共有28個(gè)模型,我們分別計(jì)算每個(gè)模型的ConversationShape。然后,我們測(cè)量模型分布和為人類(lèi)-人類(lèi)對(duì)話(huà)子集(Control-H)計(jì)算的分布之間的交叉熵。最后,我們將我們的結(jié)果與原始論文[23]中報(bào)道的人類(lèi)評(píng)價(jià)結(jié)果進(jìn)行比較。與人類(lèi)-人類(lèi)分布的交叉熵最低(0.01)的模型,也是人類(lèi)法官關(guān)于興趣偏好的模型,其特征是更好的flow和更多的信息共享(information sharing)。
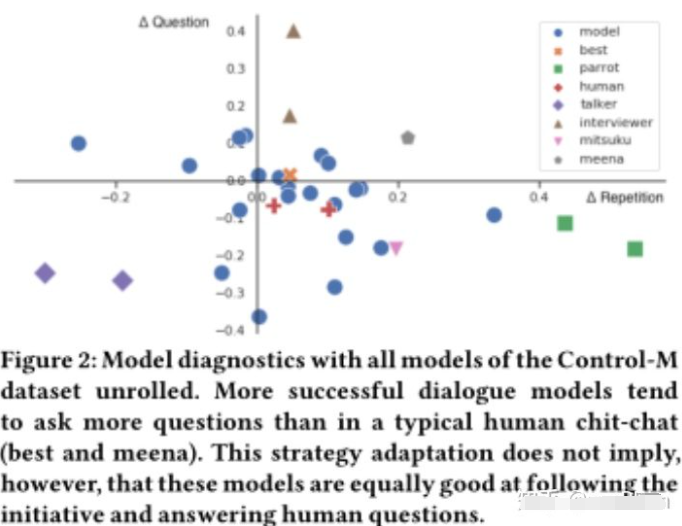
此外,ConversationShape允許解釋對(duì)話(huà)模型所展示的偏差類(lèi)型。在圖2中,我們正確地識(shí)別出了問(wèn)太多問(wèn)題(優(yōu)化為好奇、面試官)、重復(fù)太多(優(yōu)化為響應(yīng)性、鸚鵡式)或沒(méi)有跟進(jìn)(優(yōu)化為多樣性或消極響應(yīng)性、說(shuō)話(huà)者式)的模型。在比較Meena和Mitsuku對(duì)話(huà)[1]的transcripts時(shí),我們無(wú)法達(dá)到同樣的結(jié)果。問(wèn)題分布表明,Meena和Mitsuku對(duì)話(huà)在結(jié)構(gòu)上彼此非常不同,也不同于典型的人類(lèi)閑聊分布。Mitsuku正在被審訊,而Meena則主動(dòng)提出問(wèn)題。
5. 結(jié)論
在本文中,我們介紹了ConversationShape框架,該框架提供了一組簡(jiǎn)單但有效的無(wú)監(jiān)督度量,旨在度量會(huì)話(huà)的主動(dòng)性和流(flow)。我們的分析揭示了不同對(duì)話(huà)類(lèi)型之間的關(guān)系,并提出了一組適合在開(kāi)發(fā)和評(píng)估對(duì)話(huà)系統(tǒng)或收集新的對(duì)話(huà)數(shù)據(jù)集時(shí)考慮的維度。我們的“Repetition”度量(估計(jì)會(huì)話(huà)主題的后續(xù)內(nèi)容)是相當(dāng)粗糙的,因?yàn)樗豢紤]詞法匹配和回指語(yǔ)。盡管我們表明它足以對(duì)數(shù)據(jù)集分布進(jìn)行高級(jí)分析,但預(yù)測(cè)單個(gè)對(duì)話(huà)的質(zhì)量需要更細(xì)粒度的檢查。未來(lái)的工作應(yīng)該集中在開(kāi)發(fā)一個(gè)可以解釋token之間語(yǔ)義相似度的擴(kuò)展。下一步將這些指標(biāo)合并到一個(gè)學(xué)習(xí)算法的優(yōu)化標(biāo)準(zhǔn),模型提供一個(gè)適當(dāng)?shù)囊暯堑膶?duì)話(huà),給一個(gè)明確的激勵(lì)來(lái)控制一個(gè)適當(dāng)?shù)钠胶猓缥覀兯故镜模Q于對(duì)話(huà)的類(lèi)型。
原文標(biāo)題:【SIGIR2020】信息檢索對(duì)話(huà)中混合主動(dòng)性和協(xié)同性的分析
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
29525瀏覽量
211687 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102889
原文標(biāo)題:【SIGIR2020】信息檢索對(duì)話(huà)中混合主動(dòng)性和協(xié)同性的分析
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
《AI Agent 應(yīng)用與項(xiàng)目實(shí)戰(zhàn)》閱讀心得2——客服機(jī)器人、AutoGen框架 、生成式代理
海康威視文搜存儲(chǔ)系列:跨模態(tài)檢索,安防新境界
AI開(kāi)發(fā)框架集成介紹
HarmonyOS NEXT 應(yīng)用開(kāi)發(fā)練習(xí):AI智能對(duì)話(huà)框
軟通動(dòng)力與深信息簽署校企合作框架協(xié)議
浪潮信息發(fā)布"源"Yuan-EB,刷新RAG檢索最高成績(jī)
SSM框架的性能優(yōu)化技巧 SSM框架中RESTful API的實(shí)現(xiàn)
SSM框架在Java開(kāi)發(fā)中的應(yīng)用 如何使用SSM進(jìn)行web開(kāi)發(fā)
浪潮信息發(fā)布“源”Yuan-EB助力RAG檢索精度新高
HarmonyOS NEXT應(yīng)用元服務(wù)開(kāi)發(fā)Intents Kit(意圖框架服務(wù))技能調(diào)用方案概述
HarmonyOS NEXT應(yīng)用元服務(wù)開(kāi)發(fā)Intents Kit(意圖框架服務(wù))本地搜索方案概述
芯片封裝設(shè)計(jì)引腳寬度和框架引腳的設(shè)計(jì)介紹

京東金融APP的鴻蒙之旅系列專(zhuān)題 新特性篇:意圖框架接入

軟件系統(tǒng)的數(shù)據(jù)檢索設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論