 新技術可有效地使用目標檢測的對抗示例欺騙多目標跟蹤
新技術可有效地使用目標檢測的對抗示例欺騙多目標跟蹤
對抗機器學習的最新研究開始關注自主駕駛中的視覺感知,并研究了目標檢測模型的對抗示例。然而在視覺感知管道中,在被稱為多目標跟蹤的過程中,檢測到的目標必須被跟蹤,以建立周圍障礙物的移動軌跡。由于多目標跟蹤被設計為對目標檢測中的錯誤具有魯棒性,它對現有的盲目針對目標檢測的攻擊技術提出了挑戰:我們發現攻擊方需要超過98%的成功率來實際影響跟蹤結果,這是任何現有的攻擊技術都無法達到的。本文首次研究了自主駕駛中對抗式機器學習對完全視覺感知管道的攻擊,并發現了一種新的攻擊技術——軌跡劫持,該技術可以有效地使用目標檢測的對抗示例欺騙多目標跟蹤。使用我們的技術,僅在一個幀上成功的對抗示例就可以將現有物體移入或移出自駕車輛的行駛區域,從而造成潛在的安全危險。我們使用Berkeley Deep Drive數據集進行評估,發現平均而言,當3幀受到攻擊時,我們的攻擊可以有接近100%的成功率,而盲目針對目標檢測的攻擊只有25%的成功率。
01
背景
自從Eykholt等人發現第一個針對交通標志圖像分類的對抗示例以來,對抗式機器學習中的若干研究工作開始關注自動駕駛中的視覺感知,并研究物體檢測模型上的對抗示例。例如,Eykholt等人和鐘等人針對YOLO物體探測器研究了停車標志或前車背面的貼紙形式的對抗示例, 并進行室內實驗,以證明攻擊在現實世界中的可行性。在這些工作的基礎上,最近趙等人利用圖像變換技術來提高戶外環境中這種對抗式貼紙攻擊的魯棒性,并且能夠在真實道路上以30 km/h的恒定速度行駛的汽車上實現72%的攻擊成功率。雖然之前研究的結果令人擔憂,但在自動駕駛或一般的機器人系統中,目標檢測實際上只是視覺感知管道的前半部分——在后半部分,在一個稱為多目標跟蹤的過程中,必須跟蹤檢測到的目標,以建立周圍障礙物的移動軌跡。這對于隨后的駕駛決策過程是必需的,該過程需要構建的軌跡來預測這些障礙物的未來移動軌跡,然后相應地規劃駕駛路徑以避免與它們碰撞。為了確保目標檢測中的高跟蹤精度和對錯誤的魯棒性,在多目標跟蹤中,只有在多個幀中具有足夠一致性和穩定性的檢測結果可以包括在跟蹤結果中,并且實際上影響駕駛決策。因此,自動駕駛視覺感知中的多目標跟蹤對現有的盲目針對目標檢測的攻擊技術提出了新的挑戰。例如,正如我們稍后在第3節中的分析所示,對目標檢測的攻擊需要連續成功至少60幀才能欺騙典型的多目標跟蹤過程,這需要至少98%的攻擊成功率。據我們所知,沒有現有的針對目標檢測的攻擊能夠達到如此高的成功率。在本文中,我們首次研究了自動駕駛中考慮完全視覺感知管道的對抗性機器學習攻擊,即目標檢測和目標跟蹤,并發現了一種新的攻擊技術,稱為跟蹤器劫持,它可以用在目標檢測上的對抗示例有效地欺騙多目標跟蹤過程。我們的關鍵見解是,雖然很難直接為假對象創建軌跡或刪除現有對象的軌跡,但我們可以仔細設計對抗示例來攻擊多目標跟蹤中的跟蹤誤差減少過程,以使現有對象的跟蹤結果偏離攻擊者希望的移動方向。這種過程旨在提高跟蹤結果的魯棒性和準確性,但諷刺的是,我們發現攻擊者可以利用它來大大改變跟蹤結果。利用這種攻擊技術,少至一幀的對抗示例足以將現有物體移入或移出自主車輛的行駛區域,從而導致潛在的安全危險。我們從Berkeley Deep Drive數據集隨機抽樣的100個視頻片段中選擇20個進行評估。在推薦的多目標檢測配置和正常測量噪聲水平下,我們發現我們的攻擊可以在少至一幀和平均2到3個連續幀的對抗示例中成功。我們重復并比較了之前盲目針對目標檢測的攻擊,發現當攻擊連續3幀時,我們的攻擊成功率接近100%,而盲目針對對象檢測攻擊的成功率只有25%。
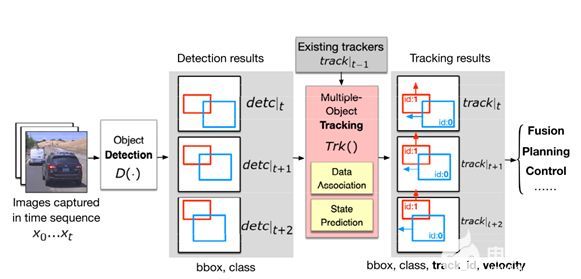
圖表 1自動駕駛中的完整視覺感知管道,即目標檢測和多目標跟蹤
本文貢獻
考慮到自動駕駛中完整的視覺感知管道,即目標檢測和運動檢測,我們首次研究了對抗性機器學習攻擊。我們發現,在不考慮多目標跟蹤的情況下,盲目針對目標檢測的攻擊至少需要98%的成功率才能真正影響自動駕駛中的完整視覺感知管道,這是任何現有攻擊技術都無法達到的。·我們發現了一種新的攻擊技術——軌跡劫持,它可以有效地利用物體檢測中的對抗示例來欺騙移動終端。這種技術利用了多目標跟蹤中的跟蹤誤差減少過程,并且可以使僅在一幀內成功的對抗示例將現有物體移入或移出自主車輛的行駛距離,從而導致潛在的安全危險。·使用Berkeley Deep Drive數據集進行的攻擊評估表明,我們的攻擊可以在少至一幀、平均只有2到3個連續幀的情況下獲得成功,當3個連續幀受到攻擊時,我們的攻擊成功率接近100%,而盲目針對目標檢測的攻擊成功率僅為25%。
多目標跟蹤
多目標跟蹤的目的是識別視頻幀序列中的物體及其運動軌跡。隨著物體檢測的進步,通過檢測進行跟蹤已經成為多目標跟蹤的范例,其中檢測步驟識別圖像中的物體,跟蹤步驟將物體鏈接到軌跡(即軌跡)。如圖1所示,在時間t檢測到的每個物體將與動態模型(例如,位置、速度)相關聯,動態模型表示物體的過去軌跡(track| t1)。,每一條軌跡都用卡爾曼濾波器來維護狀態模型,其以預測-更新循環運行:預測步驟根據運動模型估計當前對象狀態,更新步驟采用檢測結果detc|t 作為測量值來更新其狀態估計結果track|t。檢測到的物體與現有跟蹤器之間的關聯被公式化為二分匹配問題, 基于軌跡和被檢測對象之間的成對相似性損失,最常用的相似性度量是基于空間的損失,它測量邊界框或bbox之間的重疊量。為了減少這種關聯中的誤差,在卡爾曼濾波預測中需要精確的速度估計。由于攝像機幀的離散性,卡爾曼濾波器使用速度模型來估計下一幀中被跟蹤對象的位置,以補償幀間對象的運動。然而,如后面第3節中所述,這種錯誤減少過程意外地使得進行跟蹤者劫持成為可能。多目標跟蹤通過兩個閾值管理軌跡的創建和刪除。具體來說,只有當對象被持續檢測到一定數量的幀時,才會創建一個新的軌跡,該閾值將被稱為命中數,或用H指代,這有助于過濾掉物體檢測器偶爾產生的誤報。另一方面,如果在R幀的持續時間(或者稱為保留時間)內沒有對象與軌跡相關聯,軌跡將被刪除。它可以防止軌跡由于物體檢測器罕見的假陰性而被意外刪除。R和H的配置通常既取決于檢測模型的精度,也取決于幀速率(fps)。先前的研究提出了R = 2幀/秒和H = 0.2幀/秒的配置,對于普通的30幀/秒視覺感知系統給出了R = 60幀和H = 6幀。第3節的評估將表明,一個盲目地以目標檢測為目標的攻擊需要不斷地欺騙至少60幀(R)來擦除一個對象,而我們提出的軌跡劫持攻擊可以通過少到一幀,平均只有2~3幀的攻擊,來偽造持續R幀的對象,或在跟蹤結果中抹除H幀的目標對象。
02
軌道劫持攻擊
多目標跟蹤可以選擇包括一個或多個相似性度量來匹配跨幀的對象。常見的度量包括邊界框重疊、對象外觀、視覺表示和其他統計度量。作為多目標跟蹤對抗威脅的首次研究,我們選擇了基于并集的交集(IoU)的匈牙利匹配作為我們的目標算法,因為它是最廣泛采用和標準化的相似性度量,不僅是最近的研究,兩個真實世界的自動駕駛系統,百度阿波羅和Autoware也采用了這一度量 ,這確保了我們工作的代表性和實際意義。
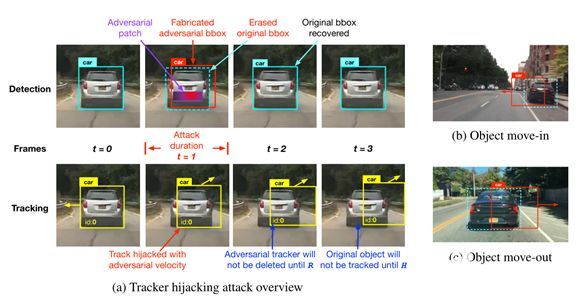
圖表 2描述軌跡劫持攻擊流程(a),以及兩種不同的攻擊場景:對象移入(b)和移出(c),其中軌跡劫持可能導致嚴重的安全后果,包括急停和追尾。
圖2a展示了本文發現的軌跡劫持攻擊,其中用于對象檢測的對抗示例(例如,前車上的對抗補丁)可以欺騙檢測結果,只用一幀就極大地偏離多目標跟蹤中目標對象(例如,前車)的軌跡。如圖所示,目標汽車最初在t0時被跟蹤到以預測的速度向左。攻擊開始于時間t1,在汽車后部貼上對抗的補丁。該補丁是精心生成的,以兩個對立的目標欺騙目標檢測器:(1)從檢測結果中刪除目標對象的邊界框;(2)制作一個類似形狀的邊界框,但稍微向攻擊者指定的方向移動。所構造的邊界框(t1處檢測結果中的紅色邊界框)將與跟蹤結果中的目標對象的原始軌跡相關聯,我們稱之為軌跡劫持,并且因此將向軌跡給出朝向攻擊者期望的方向的假速度。圖2a中所示的軌跡劫持僅持續一幀,但其對抗效果可能持續數十幀,這取決于MOT參數R和H(在第2節中介紹)。例如,在攻擊后的時間t2,所有的檢測邊界框都恢復正常,但是,兩個不利影響持續存在: (1)目標對象雖然在檢測結果中被恢復,但是將不會被跟蹤,直到達到命中計數(H),并且在此之前,該對象在跟蹤結果中仍然丟失;(2)受攻擊者誘導速度劫持的軌跡將不會被刪除,直到一個保留時間(R)過去。然而,值得注意的是,我們的攻擊在實踐中并不總是成功的,因為如果軌跡在短時間的攻擊期間沒有偏離對象的真實位置足夠遠,恢復的對象可能仍然與其原始軌跡相關聯。我們的實驗結果表明,當使用對抗示例成功攻擊3個連續幀時,我們的攻擊通常達到接近100%的成功率。這種持續的不良效應可能會在自動駕駛場景中造成嚴重的安全后果。我們強調兩種可能導致緊急停車甚至追尾事故的攻擊場景:
攻擊場景1: 目標物體移入
如圖2b所示,可以在路邊物體(例如停放的車輛)上放置對抗貼片,以欺騙經過的自駕車輛的視覺感知。在檢測結果中,生成對抗補丁以導致目標邊緣框向道路中心平移,并且被劫持的軌跡將在受害車輛的感知中表現為在前方加塞的移動車輛。如果按照朱等人的建議將R配置為2 fps,該跟蹤器將持續2秒鐘,并且這種情況下的軌跡劫持可能導致緊急停止和潛在的追尾碰撞。
攻擊場景2:目標物體移出
同樣,軌跡劫持攻擊也可以使受害自駕車輛前方的物體偏離道路,導致撞車,如圖2c所示。如果H使用0.2 fps的推薦配置,則應用于前車后部的對抗貼片可能會欺騙后面的自動車輛的多目標跟蹤器相信物體正在偏離其路線,并且前車將在200ms的持續時間內從跟蹤結果中消失,這可能會導致受害者的自動駕駛汽車撞上前車。

我們的攻擊目標是一階卡爾曼濾波器,它預測一個狀態向量,包含檢測到的對象與時間相關的位置和速度。對于數據關聯,我們采用最廣泛使用的并集的交集(IoU)作為相似性度量,通過匈牙利匹配算法計算邊緣框之間的IoU,以解決將連續幀中檢測到的邊緣框與現有軌跡關聯的二分匹配問題。多目標跟蹤中的這種算法組合在以前的研究和現實世界中是最常見的。現在描述我們的方法,即生成一個敵對補丁,操縱檢測結果劫持軌跡。詳見Alg.1,給定一個目標視頻圖像序列,攻擊迭代地找到成功劫持所需的最少干擾幀,并為這些幀生成對抗補丁。在每次攻擊迭代中,對原始視頻剪輯中的一個圖像幀進行處理,給定目標對象的索引K,該算法通過求解等式1找到放置對抗邊緣框的最佳位置pos,以劫持目標對象的軌跡。然后,攻擊使用對抗補丁構建針對目標檢測模型的對抗幀,使用等式2作為損失函數,擦除目標對象的原始邊緣框,并在給定位置構建對抗邊緣框。軌跡隨后被偏離其原始方向的對抗幀更新,如果下一幀中的目標對象沒有通過多目標跟蹤算法與其原始跟蹤器相關聯,則攻擊成功;否則,對下一幀重復該過程。我們下面討論這個算法中的兩個關鍵步驟。
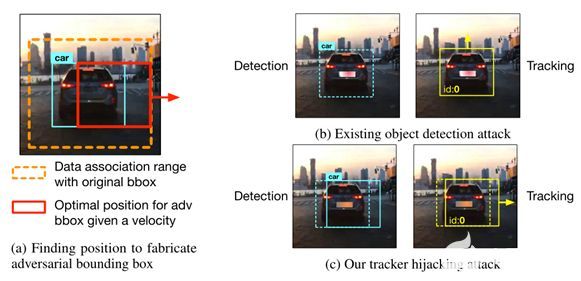
圖表 3現有的目標檢測攻擊和我們的軌跡劫持攻擊的比較。簡單擦除bbox的攻擊對跟蹤輸出沒有影響(b),而利用精心選擇的位置偽造bbox的軌跡劫持攻擊成功地將軌跡重定向到攻擊者指定的方向(c)。
尋找對抗包圍盒的最佳位置
為了偏離目標對象K的跟蹤器,除了移除其原始邊界框detc|t[K] 之外,攻擊還需要制造一個向指定方向移動δ的對抗框。這就變成了優化問題(Eq.1),即找到使檢測框和現有跟蹤器之間的匈牙利匹配(M())的損失最大化的平移向量δ,使得邊界框仍然與其原始跟蹤器相關聯(M ≤ λ),但是偏移足夠大,以給軌跡提供對抗速度。請注意,我們還將移動的邊界框限制為與補丁重疊,以方便對抗示例的生成,因為敵對擾動通常更容易影響其附近的預測結果,尤其是在物理環境中。
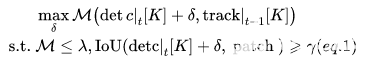
生成對抗目標檢測的補丁
類似于現有的針對目標檢測模型的對抗性攻擊,我們還將對抗性補丁生成公式化為等式2中所示的優化問題。現有的不考慮多目標跟蹤的攻擊直接將目標類(如停止標志) 的概率降到最低從而在檢測結果中抹去對象。然而,如圖3b所示,這種對抗示例在欺騙多目標跟蹤方面非常無效,因為即使在檢測邊界框被擦除之后,跟蹤器仍將跟蹤R幀。相反,我們的跟蹤器劫持攻擊的損失函數包含兩個優化目標:(1)最小化目標類概率以擦除目標對象的邊緣框;(2)在攻擊者想要的位置以特定的形狀偽造對抗邊緣框以劫持軌跡。
03
攻擊評估
評估指標
我們將成功的攻擊定義為當攻擊停止時,檢測到的目標對象的邊界框不再與任何現有的跟蹤器相關聯。我們使用物體檢測的對抗示例成功所需的最小幀數來衡量我們的軌跡劫持攻擊的有效性。攻擊效果高度依賴于原軌跡的方向向量與敵手目標的差異。例如,如果選擇對抗方向與其原始方向相反,攻擊者可以在只有一幀的情況下對跟蹤器進行大的移動,而如果敵手方向恰好與目標的原始方向相同,則很難使跟蹤器偏離其已建立的軌跡。為了控制變量,我們在前面定義的兩種攻擊場景中測量攻擊所需的幀數:即目標對象移入和移出。具體來說,在所有的移入場景中,我們選擇沿著道路停放的車輛作為目標,攻擊目標是將軌跡移動到中心,而在所有的移出場景中,我們選擇向前移動的車輛,攻擊目標是將目標軌跡移離道路。
數據集
我們從Berkeley Deep Drive數據集中隨機采樣了100個視頻片段,然后手動選擇10個適合對象移入場景,另外10個適合對象移出場景。對于每個片段,我們手動標記一個目標車輛,并將補丁區域標注為其后面的一個小區域,如圖3c所示。所有視頻每秒30幀。
實施細節
我們使用Python實現了我們的目標視覺感知管道,使用YOLOv3作為目標檢測模型,因為它在實時系統中非常受歡迎。對于多目標跟蹤實現,我們在sklearn包中使用了稱為線性賦值的匈牙利匹配實現來進行數據關聯,并在OpenCV中使用的基礎上提供了卡爾曼濾波器的參考實現。攻擊的有效性取決于卡爾曼濾波器的配置參數,稱為測量噪聲協方差(cov)。cov是對系統中有多少噪聲的估計,當更新軌跡時,較低的cov值將使卡爾曼濾波器對在時間t的檢測結果更有信心,而較高的cov值將使卡爾曼濾波器在時間t 更信任它先前在時間t- 1的預測。這種測量噪聲協方差通常基于實際中檢測模型的性能來調整。如圖4a所示,我們在從非常小(103)到非常大(10)的不同cov配置下評估我們的方法,而在實踐中cov通常設置在0.01和10之間。

圖表 4 在正常的測量噪聲協方差范圍(a)中,盡管有(R,H)設置,我們的軌跡劫持攻擊僅需要對抗示例平均只欺騙2~3個連續的幀來成功地帶偏目標軌跡。我們還比較了在不同的攻擊者能力下,軌跡劫持的成功率與以前對目標檢測器的敵對攻擊的成功率,即對抗示例可以可靠地欺騙目標檢測器所需的連續幀的數量(b)
評估結果
圖4a表明了在20個視頻剪輯上成功的軌道劫持,物體檢測上的對抗示例需要欺騙的平均幀數。雖然在fps為30時推薦R = 60、H = 6的配置,我們仍然測試不同的保留時間(R)和命中數(H)組合,這是因為現實部署通常比較保守,使用較小的R和H。結果表明,盡管有(R,H)配置,軌跡劫持攻擊僅需要平均在2到3個連續幀中成功的目標檢測對抗示例就能成功。我們還發現,即使只有一幀成功的對抗示例,當cov分別為0.1和0.01時,我們的攻擊仍有50%和30%的成功率。有趣的是,我們發現對象移入通常比對象移出需要更少的幀。原因是,在駛入場景中停放的車輛(圖2b)相對于自主車輛自然具有駛離速度。因此,與移出攻擊相比,移入攻擊觸發了攻擊者期望的速度和原始速度之間的較大差異。這使得原始對象一旦恢復,就更難正確關聯,使得劫持更容易。圖4b顯示了我們的攻擊和以前盲目針對目標檢測的攻擊(稱為檢測攻擊)的成功率。我們復制了鐘等人最近針對目標檢測的對抗性補丁攻擊,該攻擊針對自動駕駛環境,并通過真實世界的汽車測試顯示了其有效性。在這種攻擊中,目標是從每一幀的檢測結果中擦除目標類。在兩種(R,H)設置下進行評估,我們發現我們的軌跡劫持攻擊即使只攻擊3幀也能達到優越的攻擊成功率(100%),而檢測攻擊需要可靠地欺騙至少R個連續幀。當按照30 fps的幀率將R設置為60時,檢測攻擊需要在受害自駕車行駛的同時對抗性補丁能夠持續成功至少60幀。這意味著超過98.3% (59/60)的對抗示例成功率,這在以前的研究中從未達到。請注意,檢測攻擊在R之前仍然可以有高達約25%的成功率。這是因為檢測攻擊導致對象在某些幀中消失,并且當車輛航向在此消失期間發生變化時,仍然有可能導致原始對象在恢復時與原始軌跡中的軌跡預測不匹配。然而,由于我們的攻擊是為了故意誤導多目標跟蹤中的軌跡預測,我們的成功率要高得多(3-4倍),并且可以在少至3幀的攻擊下達到100%。
04
討論與總結
對該領域未來研究的啟示
如今,針對自動駕駛中視覺感知的對抗性機器學習研究,無論是攻擊還是防御,都使用目標檢測的準確性作為事實上的評估指標。然而,正如在我們的工作中具體顯示的,在不考慮多目標跟蹤的情況下,對檢測結果的成功攻擊并不意味著對多目標跟蹤結果的同等或接近成功的攻擊,多目標跟蹤結果是真實世界自動駕駛中視覺感知任務的最終輸出。因此,我們認為這一領域的未來研究應考慮:(1)使用多目標跟蹤準確度作為評估指標;(2)不僅僅關注目標檢測,還應研究多目標跟蹤特有的弱點或多目標跟蹤與目標檢測之間的相互作用,這是一個目前尚未充分探索的研究領域。這篇論文標志著第一次朝兩個方向努力的研究。
實用性提升
我們的評估目前都是用捕獲的視頻幀進行數字處理的,而我們的方法在應用于生成物理補丁時應該仍然有效。例如,我們提出的對抗補丁生成方法可以自然地與以前工作提出的不同技術相結合,以增強物理世界中的可靠性。
通用性提高
雖然在這項工作中,我們側重于使用基于IoU的數據關聯的多目標跟蹤算法,但我們尋找位置來放置對抗邊界框的方法通常適用于其他關聯機制(例如,基于外觀的匹配)。我們針對YOLOv3的對抗示例生成算法也應該適用于其他具有適度適應性的目標檢測模型。我們計劃提供更多真實世界端到端視覺感知管道的參考實現,為未來自動駕駛場景中的對抗學習研究鋪平道路。
fqj
-
濾波器
+關注
關注
162文章
8065瀏覽量
180955 -
目標檢測
+關注
關注
0文章
222瀏覽量
15891
發布評論請先 登錄
分時電價下光伏園區電動汽車有序充電多目標優化政策研究
使用RTSP攝像頭執行多攝像頭多目標Python演示,缺少輸出幀是怎么回事?
探索對抗訓練的概率分布偏差:DPA雙概率對齊的通用域自適的目標檢測方法

淺談多目標優化約束條件下充電設施有序充電控制策略
視頻目標跟蹤從0到1,概念與方法

使用STT全面提升自動駕駛中的多目標跟蹤
IP 地址欺騙:原理、類型與防范措施






 工商網監
工商網監
評論