") 一種單獨適配于NER的數(shù)據(jù)增強方法
一種單獨適配于NER的數(shù)據(jù)增強方法
本文首先介紹傳統(tǒng)的數(shù)據(jù)增強在NER任務中的表現(xiàn),然后介紹一種單獨適配于NER的數(shù)據(jù)增強方法,這種方法生成的數(shù)據(jù)更具豐富性、數(shù)據(jù)質(zhì)量更高。
0
前言
在NLP中有哪些數(shù)據(jù)增強技術?這一定是當今NLP面試中的必考題了吧。在《標注樣本少怎么辦?》(鏈接:https://zhuanlan.zhihu.com/p/146777068)一文中也詳細總結(jié)過這個問題。 但是,目前來看:大多數(shù)「數(shù)據(jù)增強」方法通常被用于文本分類、文本匹配等任務中,這類任務有一個共性:是“句子級別”(sentence level)的分類任務,大多數(shù)關于「文本增強」的研究也都針對這個任務。 在2020年5月的時候,JayJay突然在想:NER如何進行數(shù)據(jù)增強?有什么奇思妙想可以用上?于是我陷入沉思中......
NER做數(shù)據(jù)增強,和別的任務有啥不一樣呢?很明顯,NER是一個token-level的分類任務,在進行全局結(jié)構(gòu)化預測時,一些增強方式產(chǎn)生的數(shù)據(jù)噪音可能會讓NER模型變得敏感脆弱,導致指標下降、最終奔潰。 在實踐中,我們也可以把常用的數(shù)據(jù)增強方法遷移到NER中,比如,我們通常采用的「同類型實體」隨機替換等。但這類方法通常需要獲得額外資源(實體詞典、平行語料等),如果沒有知識庫信息,NER又該如何做數(shù)據(jù)增強呢?有沒有一種單獨為NER適配的數(shù)據(jù)增強方法呢? 本文JayJay主要介紹在最近頂會中、對NER進行數(shù)據(jù)增強的2篇paper:
COLING20:《An Analysis of Simple Data Augmentation for Named Entity Recognition》
EMNLP20:《DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks》
COLING20主要是將傳統(tǒng)的數(shù)據(jù)增強方法應用于NER中、并進行全面分析與對比。 EMNLP20主要是提出了一種適配于NER的數(shù)據(jù)增強方法——語言模型生成方法:1)這種方式不依賴于外部資源,比如實體詞典、平行語料等;2)可同時應用于有監(jiān)督、半監(jiān)督場景。 具體效果如何,我們來一探究竟吧~本文的組織結(jié)構(gòu)為:
1
傳統(tǒng)的數(shù)據(jù)增強方法遷移到NER,效果如何?
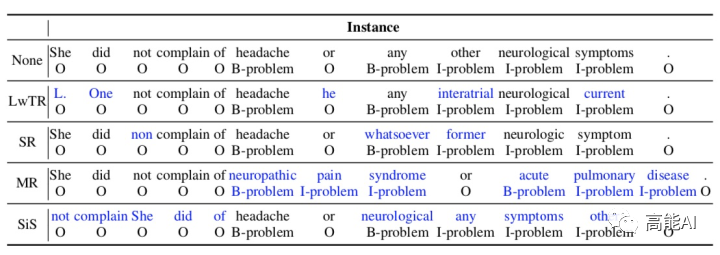
在COLING20的paper中,作者借鑒sentence-level的傳統(tǒng)數(shù)據(jù)增強方法,將其應用于NER中,共有4種方式(如上圖所示):
Label-wise token replacement (LwTR):即同標簽token替換,對于每一token通過二項分布來選擇是否被替換;如果被替換,則從訓練集中選擇相同的token進行替換。
Synonym replacement (SR):即同義詞替換,利用WordNet查詢同義詞,然后根據(jù)二項分布隨機替換。如果替換的同義詞大于1個token,那就依次延展BIO標簽。
Mention replacement (MR):即實體提及替換,與同義詞方法類似,利用訓練集中的相同實體類型進行替換,如果替換的mention大于1個token,那就依次延展BIO標簽,如上圖:「headache」替換為「neuropathic pain syndrome」,依次延展BIO標簽。
Shuffle within segments (SiS):按照mention來切分句子,然后再對每個切分后的片段進行shuffle。如上圖,共分為5個片段: [She did not complain of], [headache], [or], [any other neurological symptoms], [.]. 。也是通過二項分布判斷是否被shuffle(mention片段不會被shuffle),如果shuffle,則打亂片段中的token順序。
論文也設置了不同的資源條件:
Small(S):包含50個訓練樣本;
Medium (M):包含150個訓練樣本;
Large (L):包含500個訓練樣本;
Full (F):包含全量訓練集;
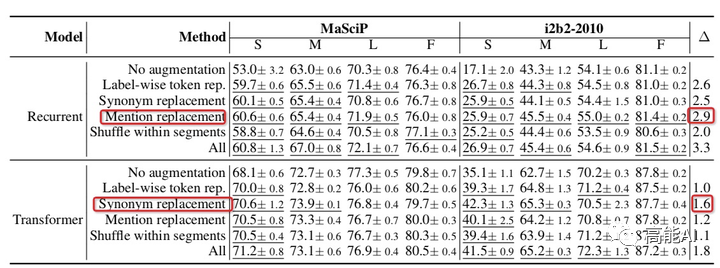
由上圖可以看出:
各種數(shù)據(jù)增強方法都超過不使用任何增強時的baseline效果。
對于RNN網(wǎng)絡,實體提及替換優(yōu)于其他方法;對于Transformer網(wǎng)絡,同義詞替換最優(yōu)。
總體上看,所有增強方法一起使用(ALL)會由于單獨的增強方法。
低資源條件下,數(shù)據(jù)增強效果增益更加明顯;
充分數(shù)據(jù)條件下,數(shù)據(jù)增強可能會帶來噪聲,甚至導致指標下降;
2
DAGA:單獨適配于NER的數(shù)據(jù)增強方法
EMNLP這篇NER數(shù)據(jù)增強論文DAGA來自阿里達摩院,其主要是通過語言模型生成來進行增強,其整體思路也非常簡單清晰。
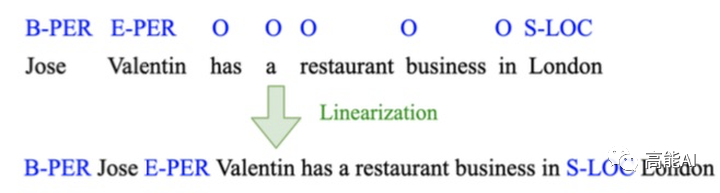
DAGA的核心思路也十分清晰,就是標簽線性化:即將原始的「序列標注標簽」與「句子token」進行混合,也就是變成「Tag-Word」的形式,如上圖所示:將「B-PER」放置在「Jose」之前,將「E-PER」放置在「Valentin」之前;對于標簽「O」則不與句子混合。標簽線性化后就可以生成一個句子了,基于這個句子就可以進行「語言模型生成」訓練啦~是不是超級簡單?!
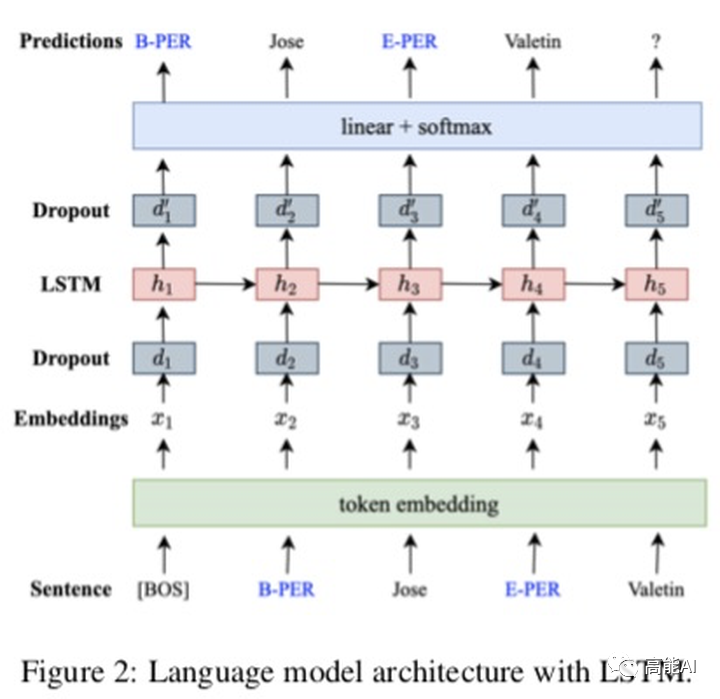
DAGA 網(wǎng)絡(如上圖)僅僅通過一層LSTM進行自回歸的語言模型訓練,網(wǎng)絡很輕,沒有基于BERT做。 DAGA的一大優(yōu)點就是不需要額外資源,比如同義詞替換就需要一個WordNet。但是論文也考慮到了使用外部資源時的情況,比如:1)有大量無標注語料時;2)有外部知識庫時;

對于不同的3種資源條件下,具體的訓練語料構(gòu)建如上圖所示:
對于標注語料,用[labeled]在句首作為條件標記;
對于無標注語料,用[unlabeled]在句首作為條件標記;
對于知識庫,對無標注語料進行詞典匹配后(正向最大匹配),用[KB]在句首作為條件標記;
只要輸入[BOS]+[labeled]/[unlabeled]/[KB],即可通過上述語言模型、自回歸生成新的增強數(shù)據(jù)啦~ 下面我們分別對上述3種資源條件下的生成方法進行驗證:2.1 只使用標注語料進行語言生成共采用4種實驗設置:
gold:通過標注語料進行NER訓練
gen:即DAGA,1)通過標注語料進行語言模型訓練、生成新的數(shù)據(jù):2) 過采樣標注語料; 3)新數(shù)據(jù)+過采樣標注語料,最后一同訓練NER;
rd:1)通過隨機刪除進行數(shù)據(jù)增強; 2)過采樣標注語料;3)新數(shù)據(jù)+過采樣標注語料,最后一同訓練NER;
rd*:同rd,只是不過采樣標注語料。
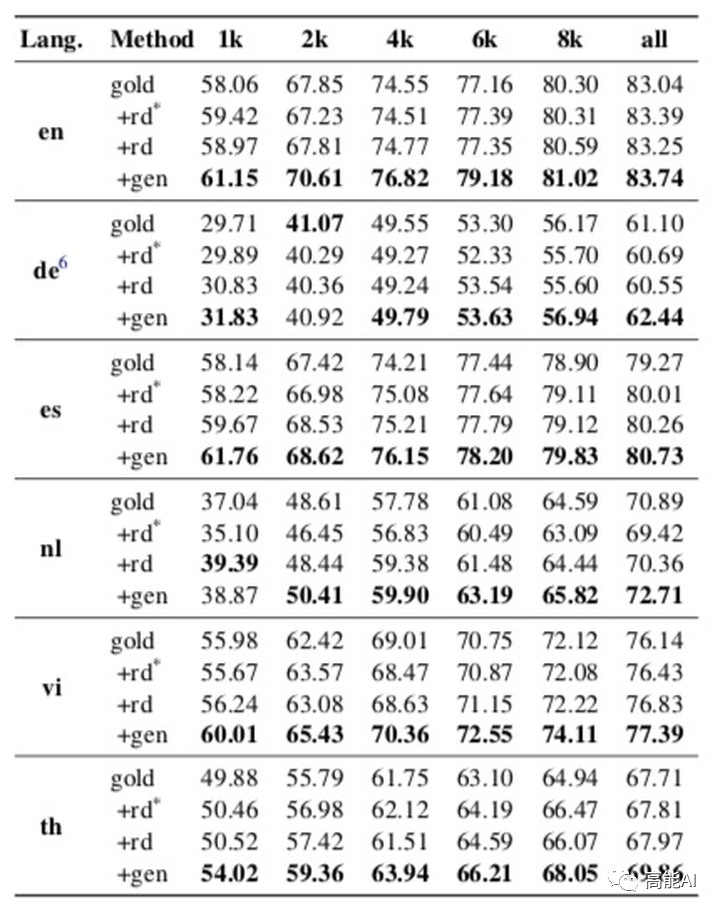
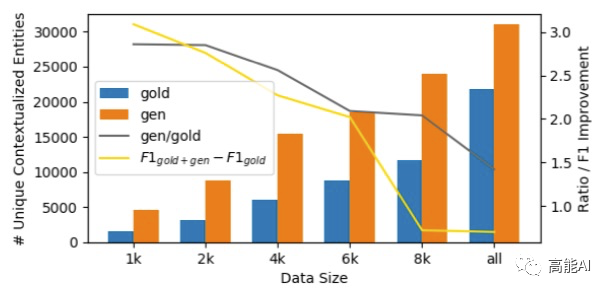
具體結(jié)果由上圖展示(設置了6種不同語言數(shù)據(jù)、不同的原始標注數(shù)據(jù)量進行對比),可以看出:DAGA方式(gen)明顯超過其他數(shù)據(jù)增強方法,特別是在低資源條件下(1k和2k數(shù)據(jù)量)。2.2 使用無標注語料進行語言生成共采用3種實驗設置:
gold:通過標注語料進行NER訓練;
wt:即弱監(jiān)督方法,采用標注語料訓練好一個NER模型,然后通過NER模型對無標注語料偽標生成新數(shù)據(jù),然后再重新訓練一個NER模型;
gen-ud:通過標注和無標注語料共同進行語言模型訓練、生成新數(shù)據(jù),然后再訓練NER模型;
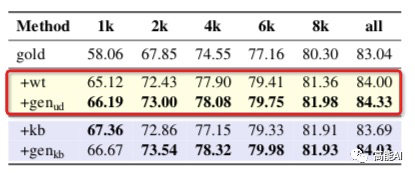
由上圖的紅框進行對比,可以看出:DAGA方法在所有設置下、均超過了弱監(jiān)督數(shù)據(jù)方法。其實弱監(jiān)督方法生成的數(shù)據(jù)質(zhì)量較低、噪聲較大,而DAGA可以有效改善這一情況。 可以預見的是:當有大量無標注語料時,DAGA進行的NER數(shù)據(jù)增強,將有效提升NER指標。2.3 使用無標注語料+知識庫進行語言生成同樣也是采用3種實驗設置:
gold:通過標注語料進行NER訓練;
kb:從全量訓練集中積累實體詞典(實體要在訓練集上中至少出現(xiàn)2次),然后用實體詞典匹配標注無標注語料、生成新數(shù)據(jù),最后再訓練NER模型;
gen-kb:與kb類似,將kb生成的新數(shù)據(jù)訓練語言模型,語言模型生成數(shù)據(jù)后、再訓練NER模型;
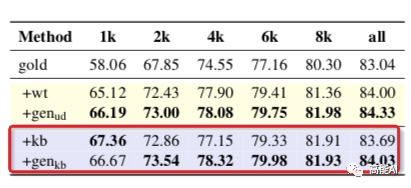
如上圖紅框所示,總體上DAGA超過了kb方式,低資源條件(1k)下,kb方式還是強于DAGA。
3
DAGA為何如此有效?

DAGA更具多樣性:
如上圖所示,在原始的訓練集中「Sandrine」只會和「Testud」構(gòu)成一個實體span,而DAGA生成的數(shù)據(jù)中,「Sandrine」會和更豐富的token構(gòu)成一個實體。
此外,DAGA會生成更豐富的實體上下文,論文以相同實體mention的1-gram作為評估指標進行了統(tǒng)計。如下圖所示,桔色代表DAGA生成的實體上下文,比原始的訓練集會有更豐富的上下文。
DAGA可以有效利用無標注語料:DAGA通過無標注語料來生成有用的數(shù)據(jù),新數(shù)據(jù)中會出現(xiàn)那些未在標注語料中出現(xiàn)的新實體。
4
總結(jié)
本文就「NER如何進行數(shù)據(jù)增強」進行了介紹:
雖然傳統(tǒng)的數(shù)據(jù)增強方法也可用于NER中,不過,JayJay認為:傳統(tǒng)的數(shù)據(jù)增強方法應用到NER任務時,需要外部資源,且數(shù)據(jù)增強的豐富性不足、噪音可能較大。
基于語言生成的DAGA方法是NER數(shù)據(jù)增強的一種新興方式,再不利用外部資源時會有較好的豐富性、數(shù)據(jù)質(zhì)量較好。
責任編輯:xj
原文標題:打開你的腦洞:NER如何進行數(shù)據(jù)增強 ?
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
-
數(shù)據(jù)
+關注
關注
8文章
7237瀏覽量
90921 -
自然語言處理
+關注
關注
1文章
626瀏覽量
13989 -
nlp
+關注
關注
1文章
490瀏覽量
22460
原文標題:打開你的腦洞:NER如何進行數(shù)據(jù)增強 ?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
一種永磁電機用轉(zhuǎn)子組件制作方法
解決電源適配器的干擾問題,用以下方法解決!
三大方法解決開關電源適配器絕緣掩護!
一種降低VIO/VSLAM系統(tǒng)漂移的新方法
一種混合顏料光譜分區(qū)間識別方法
一種面向飛行試驗的數(shù)據(jù)融合框架

一種提升無人機小物體跟蹤精度的方法

一種創(chuàng)新的動態(tài)軌跡預測方法
一種基于光強度相關反饋的波前整形方法
一種簡單高效配置FPGA的方法
BitEnergy AI公司開發(fā)出一種新AI處理方法
一種利用wireshark對遠程服務器/路由器網(wǎng)絡抓包方法

一種無透鏡成像的新方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論