 基于PyTorch的深度學習入門教程之PyTorch重點綜合實踐
基于PyTorch的深度學習入門教程之PyTorch重點綜合實踐
前言
PyTorch提供了兩個主要特性:
(1) 一個n維的Tensor,與numpy相似但是支持GPU運算。
(2) 搭建和訓練神經網絡的自動微分功能。
我們將會使用一個全連接的ReLU網絡作為實例。該網絡有一個隱含層,使用梯度下降來訓練,目標是最小化網絡輸出和真實輸出之間的歐氏距離。
目錄
Tensors(張量)
Warm-up:numpy
PyTorch:Tensors
Autograd(自動梯度)
PyTorch:Variables and autograd (變量和自動梯度)
PyTorch : Defining new autograd functions(定義新的自動梯度函數)
TensorFlow: Static Graphs (靜態圖)
nn module
PyTorch: nn
PyTorch: optim
PyTorch: Custom nn Modules (定制nn模塊)
PyTorch: Control Flow + Weight Sharing (控制流+權重分享)
Tensors(張量)
Warm-up:numpy
在介紹PyTorch之前,我們先使用numpy來實現一個網絡。
Numpy提供了一個n維數組對象,以及操作這些數組的函數。Numpy是一個通用的科學計算框架。它不是專門為計算圖、深度學習或者梯度計算而生,但是我們能用它來把一個兩層的網絡擬合到隨機數據上,只要我們手動把numpy運算在網絡上前向和反向執行即可。
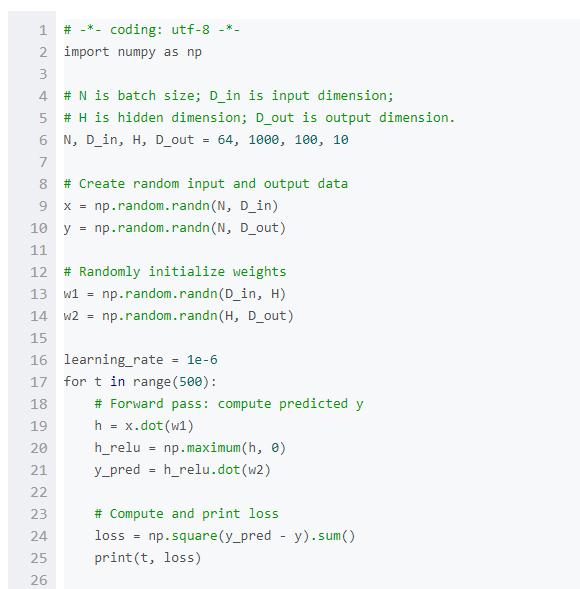
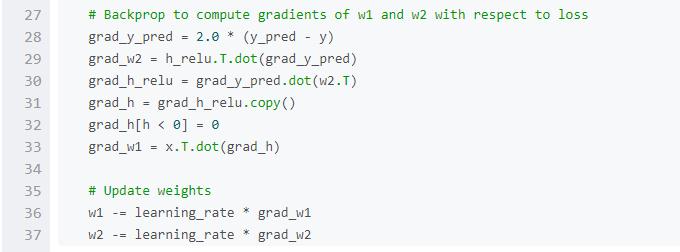
Numpy是一個了不起的框架,但是它很遺憾地不能支持GPU運算,無法對數值計算進行GPU加速。對于現在的深度神經網絡,GPU一般能提供50倍以上的加速,所以numpy由于對GPU缺少支持,不能滿足深度神經網絡的計算需求。
這里介紹一下最基本的PyTorch概念:Tensor。一個PyTorch Tensor在概念上等價于numpy array:Tensor是一個n維的array,PyTorch提供了很多函數來在Tensors上進行運算。像numpy arrays一樣,PyTorch Tensors也不是為深度學習、計算圖、梯度而生;他們是一個科學計算的通用工具。
PyTorch Tensors可以利用GPU來加速數值計算。為了能在GPU上跑Tensor,我們只需要將它轉到新的數據類型。
我們使用PyTorch Tensors來擬合2層的網絡。與上面的numpy例子一樣,我們需要手動執行網絡上的前向和反向過程。
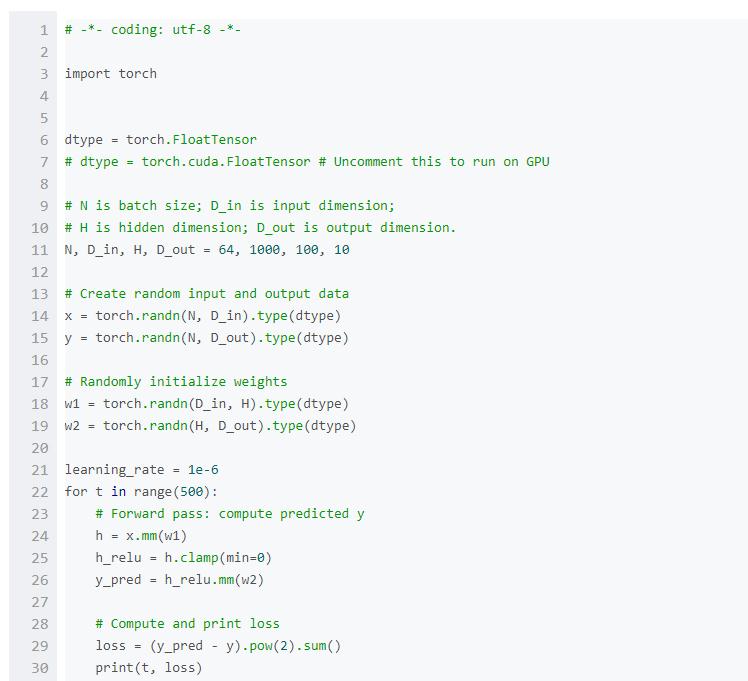
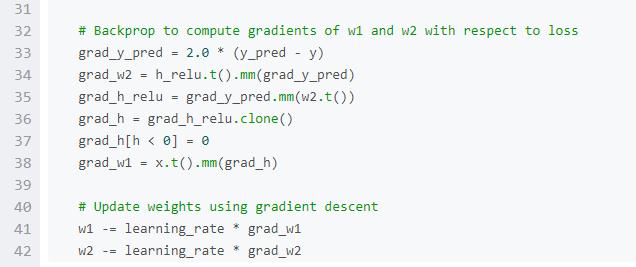
Autograd(自動梯度)
PyTorch:Variables and autograd (變量和自動梯度)
在上面的例子中,我們必須手動執行網絡的前向和反向通道。對于一個兩層的小網絡來說,手動反向執行不是什么大事,但是對于大型網絡來說,就非常費勁了。
幸運的是,我們可以使用自動微分來自動計算神經網絡的反向通道。PyTorch的autograd 包就提供了此項功能。當使用autograd的時候,你的網絡的前向通道定義一個計算圖(computational graph),圖中的節點(node)是Tensors,邊(edge)將會是根據輸入Tensor來產生輸出Tensor的函數。這個圖的反向傳播將會允許你很輕松地去計算梯度。
這個聽起來復雜,但是實際操作非常簡單。我們把PyTorch Tensors打包到Variable 對象中,一個Variable代表一個計算圖中的節點。如果x是一個Variable,那么x. data 就是一個Tensor 。并且x.grad是另一個Variable,該Variable保持了x相對于某個標量值得梯度。
PyTorch的Variable具有與PyTorch Tensors相同的API。差不多所有適用于Tensor的運算都能適用于Variables。區別在于,使用Variables定義一個計算圖,令我們可以自動計算梯度。
下面我們使用PyTorch 的Variables和自動梯度來執行我們的兩層的神經網絡。我們不再需要手動執行網絡的反向通道了。


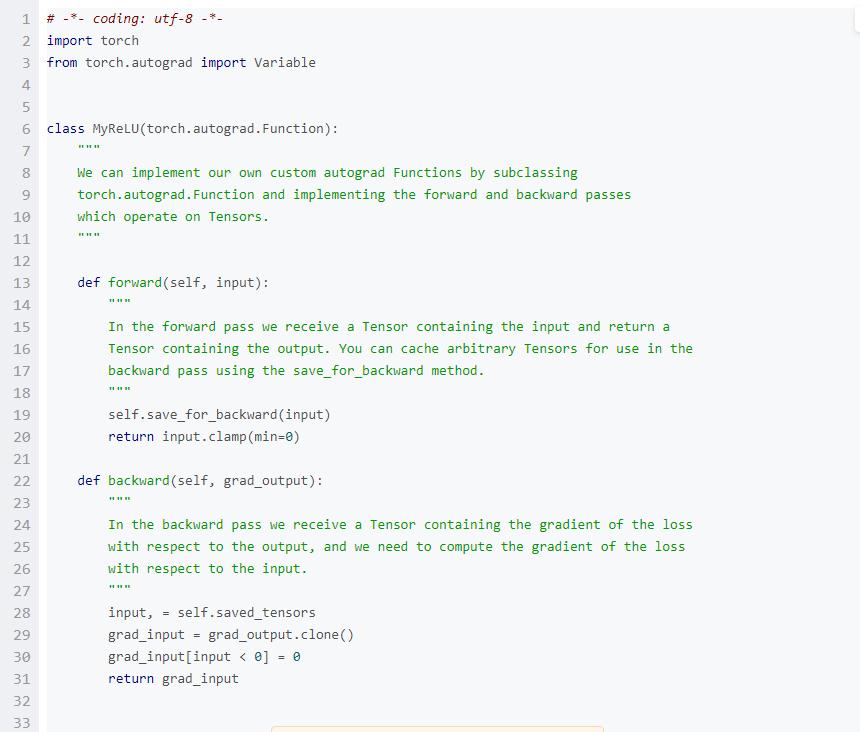
PyTorch : Defining new autograd functions(定義新的自動梯度函數)
在底層,每一個原始的自動梯度運算符實際上是兩個在Tensor上運行的函數。其中,forward函數計算從輸入Tensors獲得的輸出Tensors。而backward函數接收輸出Tensors相對于某個標量值的梯度,并且計算輸入Tensors相對于該相同標量值的梯度。
在PyTorch中,我們可以很容易地定義自己的自動梯度運算符。具體來講,就是先定義torch.autograd.Function的子類,然后實現forward和backward函數。之后我們就可以使用這個新的自動梯度運算符了。使用該運算符的方式是創建一個實例,并且像一個函數一樣去調用它,傳遞包含輸入數據的Variables。
在這個例子中,我們定義自己的定制自動梯度函數來執行ReLU非線性,然后使用它執行我們的兩層網絡。


TensorFlow: Static Graphs(靜態圖)
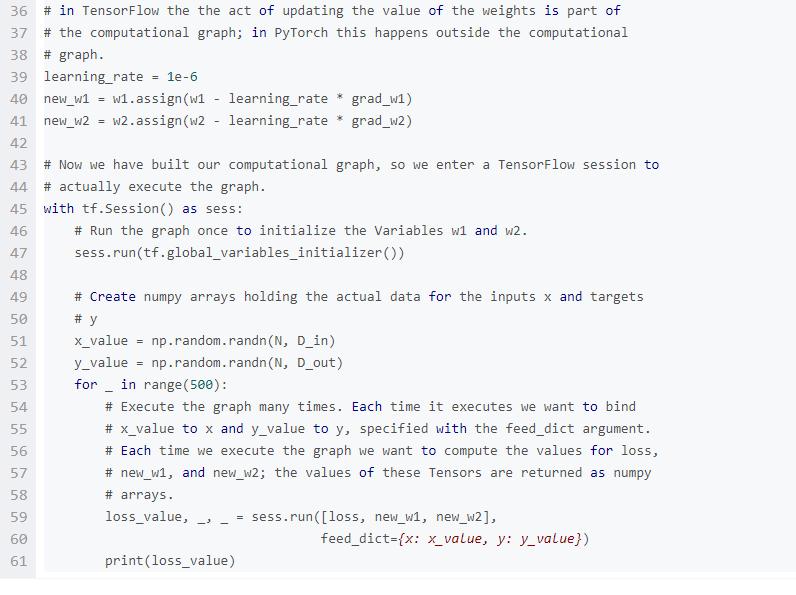
PyTorch自動梯度看起來非常像TensorFlow:在兩個框架中,我們都定義計算圖,使用自動微分來計算梯度。兩者最大的不同就是TensorFlow的計算圖是靜態的,而PyTorch使用動態的計算圖。
在TensorFlow中,我們定義計算圖一次,然后重復執行這個相同的圖,可能會提供不同的輸入數據。而在PyTorch中,每一個前向通道定義一個新的計算圖。
靜態圖的好處在于你可以預先對圖進行優化。例如,一個框架可能要融合一些圖運算來提升效率,或者產生一個策略來將圖分布到多個GPU或機器上。如果你重復使用相同的圖,前期優化的消耗就會被分攤開,因為相同的圖在多次重復運行。
靜態圖和動態圖的一個不同之處是控制流。對于一些模型,我們希望對每個數據點執行不同的計算。例如,一個遞歸神經網絡可能對于每個數據點執行不同的時間步數,這個展開(unrolling)可以作為一個循環來實現。對于一個靜態圖,循環結構要作為圖的一部分。因此,TensorFlow提供了運算符(例如tf .scan)來把循環嵌入到圖當中。對于動態圖來說,情況更加簡單:既然我們為每個例子即時創建圖,我們可以使用正常的解釋流控制來為每個輸入執行不同的計算。
為了與上面的PyTorch自動梯度實例做對比,我們使用TensorFlow來擬合一個簡單的2層網絡。

計算圖和自動梯度是非常強大的范式,可用于定義復雜的運算符和自動求導數。然而,對于一個大型的網絡來說,原始的自動梯度有點太低級別了。
在建立神經網絡的時候,我們經常把計算安排在層(layers)中。某些層有可學習的參數,將會在學習中進行優化。
在TensorFlow中,Keras,TensorFlow-Slim和TFLearn這些包提供了原始計算圖之上的高級抽象,這對于構建神經網絡大有裨益。
在PyTorch中, nn包服務于相同的目的。nn包定義了一系列Modules,大體上相當于神經網絡的層。一個Module接收輸入Variables,計算輸出Variables,但是也可以保持一個內部狀態,例如包含了可學習參數的Variables。nn 包還定義了一系列在訓練神經網絡時常用的損失函數。
在下面例子中,我們使用nn包來實現我們的兩層神經網絡。


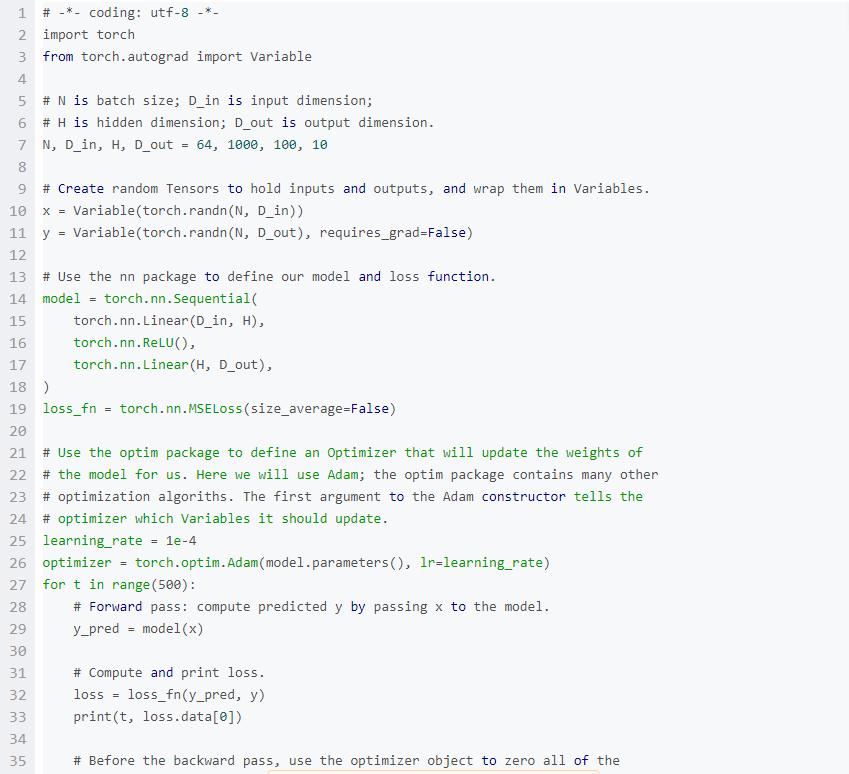
目前,我們已經通過手動改變持有可學習參數的Variables的 .data成員來更新模型的權重。對于簡單的優化算法(例如隨機梯度下降)來說這不是一個大的負擔,但是實際上我們經常使用更加復雜的優化器來訓練神經網絡,例如AdaGrad, RMSProp, Adam等。
PyTorch的optim包將優化算法進行抽象,并提供了常用的優化算法的實現。
下面這個例子,我們將會使用 nn包來定義模型,使用optim包提供的Adam算法來優化這個模型。

有時候,需要設定比現有模塊序列更加復雜的模型。這時,你可以通過生成一個nn.Module的子類來定義一個forward。該forward可以使用其他的modules或者其他的自動梯度運算來接收輸入Variables,產生輸出Variables。
在這個例子中,我們實現兩層神經網絡作為一個定制的Module子類。


我們實現一個非常奇怪的模型來作為動態圖和權重分享的例子。這個模型是一個全連接的ReLU網絡。每一個前向通道選擇一個1至4之間的隨機數,在很多隱含層中使用。多次使用相同的權重來計算最內層的隱含層。
這個模型我們使用正常的Python流控制來實現循環。在定義前向通道時,通過多次重復使用相同的Module來實現權重分享。
我們實現這個模型作為一個Module的子類。


總結
本文介紹了PyTorch中的重點模塊和使用,對于開展之后的實戰練習非常重要。所以,我們需要認真練習一下本文的所有模塊。最好手敲代碼走一遍。
責任編輯:xj
-
深度學習
+關注
關注
73文章
5554瀏覽量
122449 -
pytorch
+關注
關注
2文章
809瀏覽量
13754
發布評論請先 登錄






 工商網監
工商網監
評論