") 數(shù)據(jù)科學(xué)經(jīng)典算法 KNN 已被嫌慢,ANN 比它快 380 倍
數(shù)據(jù)科學(xué)經(jīng)典算法 KNN 已被嫌慢,ANN 比它快 380 倍
數(shù)據(jù)科學(xué)經(jīng)典算法 KNN 已被嫌慢,ANN 比它快 380 倍。
在模式識別領(lǐng)域中,K - 近鄰算法(K-Nearest Neighbor, KNN)是一種用于分類和回歸的非參數(shù)統(tǒng)計方法。K - 近鄰算法非常簡單而有效,它的模型表示就是整個訓(xùn)練數(shù)據(jù)集。就原理而言,對新數(shù)據(jù)點的預(yù)測結(jié)果是通過在整個訓(xùn)練集上搜索與該數(shù)據(jù)點最相似的 K 個實例(近鄰)并且總結(jié)這 K 個實例的輸出變量而得出的。KNN 可能需要大量的內(nèi)存或空間來存儲所有數(shù)據(jù),并且使用距離或接近程度的度量方法可能會在維度非常高的情況下(有許多輸入變量)崩潰,這可能會對算法在你的問題上的性能產(chǎn)生負面影響。這就是所謂的維數(shù)災(zāi)難。
近似最近鄰算法(Approximate Nearest Neighbor, ANN)則是一種通過犧牲精度來換取時間和空間的方式從大量樣本中獲取最近鄰的方法,并以其存儲空間少、查找效率高等優(yōu)點引起了人們的廣泛關(guān)注。
近日,一家技術(shù)公司的數(shù)據(jù)科學(xué)主管 Marie Stephen Leo 撰文對 KNN 與 ANN 進行了比較,結(jié)果表明,在搜索到最近鄰的相似度為 99.3% 的情況下,ANN 比 sklearn 上的 KNN 快了 380 倍。
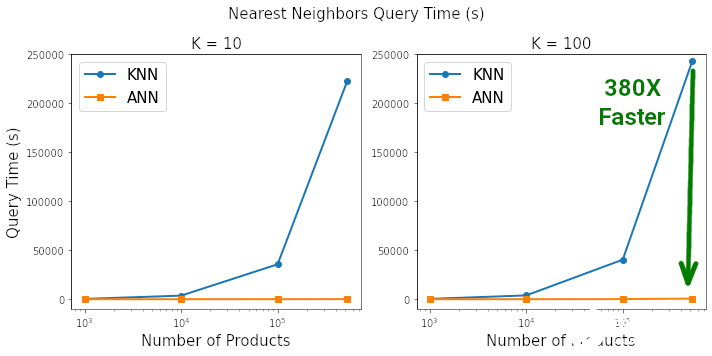
作者表示,幾乎每門數(shù)據(jù)科學(xué)課程中都會講授 KNN 算法,但它正在走向「淘汰」!
KNN 簡述
在機器學(xué)習(xí)社區(qū)中,找到給定項的「K」個相似項被稱為相似性搜索或最近鄰(NN)搜索。最廣為人知的 NN 搜索算法是 KNN 算法。在 KNN 中,給定諸如手機電商目錄之類的對象集合,則對于任何新的搜索查詢,我們都可以從整個目錄中找到少量(K 個)最近鄰。例如,在下面示例中,如果設(shè)置 K = 3,則每個「iPhone」的 3 個最近鄰是另一個「iPhone」。同樣,每個「Samsung」的 3 個最近鄰也都是「Samsung」。

KNN 存在的問題
盡管 KNN 擅長查找相似項,但它使用詳細的成對距離計算來查找鄰居。如果你的數(shù)據(jù)包含 1000 個項,如若找出新產(chǎn)品的 K=3 最近鄰,則算法需要對數(shù)據(jù)庫中所有其他產(chǎn)品執(zhí)行 1000 次新產(chǎn)品距離計算。這還不算太糟糕,但是想象一下,現(xiàn)實世界中的客戶對客戶(Customer-to-Customer,C2C)市場,其中的數(shù)據(jù)庫包含數(shù)百萬種產(chǎn)品,每天可能會上傳數(shù)千種新產(chǎn)品。將每個新產(chǎn)品與全部數(shù)百萬種產(chǎn)品進行比較是不劃算的,而且耗時良久,也就是說這種方法根本無法擴展。
解決方案
將最近鄰算法擴展至大規(guī)模數(shù)據(jù)的方法是徹底避開暴力距離計算,使用 ANN 算法。
近似最近距離算法(ANN)
嚴格地講,ANN 是一種在 NN 搜索過程中允許少量誤差的算法。但在實際的 C2C 市場中,真實的鄰居數(shù)量比被搜索的 K 近鄰數(shù)量要多。與暴力 KNN 相比,人工神經(jīng)網(wǎng)絡(luò)可以在短時間內(nèi)獲得卓越的準確性。ANN 算法有以下幾種:
Spotify 的 ANNOY
Google 的 ScaNN
Facebook 的 Faiss
HNSW
分層的可導(dǎo)航小世界(Hierarchical Navigable Small World, HNSW)
在 HNSW 中,作者描述了一種使用多層圖的 ANN 算法。在插入元素階段,通過指數(shù)衰減概率分布隨機選擇每個元素的最大層,逐步構(gòu)建 HNSW 圖。這確保 layer=0 時有很多元素能夠?qū)崿F(xiàn)精細搜索,而 layer=2 時支持粗放搜索的元素數(shù)量少了 e^-2。最近鄰搜索從最上層開始進行粗略搜索,然后逐步向下處理,直至最底層。使用貪心圖路徑算法遍歷圖,并找到所需鄰居數(shù)量。
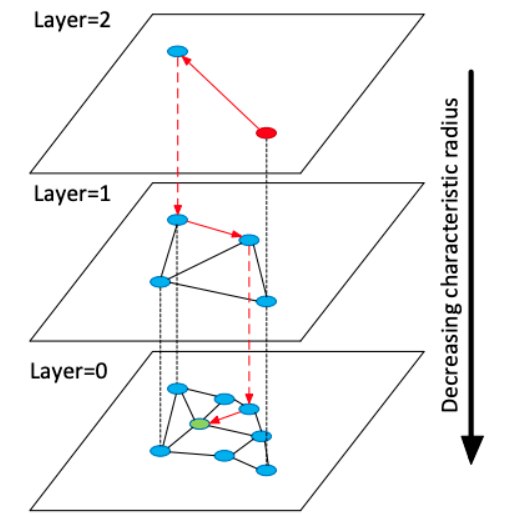
HNSW 圖結(jié)構(gòu)。最近鄰搜索從最頂層開始(粗放搜索),在最底層結(jié)束(精細搜索)。
HNSW Python 包
整個 HNSW 算法代碼已經(jīng)用帶有 Python 綁定的 C++ 實現(xiàn)了,用戶可以通過鍵入以下命令將其安裝在機器上:pip install hnswlib。安裝并導(dǎo)入軟件包之后,創(chuàng)建 HNSW 圖需要執(zhí)行一些步驟,這些步驟已經(jīng)被封裝到了以下函數(shù)中:
importhnswlib importnumpy asnpdef fit_hnsw_index(features, ef= 100, M= 16, save_index_file= False): # Convenience function to create HNSW graph # features : list of lists containing the embeddings # ef, M: parameters to tune the HNSW algorithm num_elements = len(features) labels_index = np.arange(num_elements) EMBEDDING_SIZE = len(features[ 0]) # Declaring index # possible space options are l2, cosine or ip p = hnswlib.Index(space= ‘l2’, dim=EMBEDDING_SIZE) # Initing index - the maximum number of elements should be known p.init_index(max_elements=num_elements, ef_construction=ef, M=M) # Element insertion int_labels = p.add_items(features, labels_index) # Controlling the recall by setting ef # ef should always be 》 k p.set_ef(ef) # If you want to save the graph to a file ifsave_index_file: p.save_index(save_index_file) returnp
創(chuàng)建 HNSW 索引后,查詢「K」個最近鄰就僅需以下這一行代碼:
ann_neighbor_indices, ann_distances = p.knn_query(features, k)
KNN 和 ANN 基準實驗
計劃
首先下載一個 500K + 行的大型數(shù)據(jù)集。然后將使用預(yù)訓(xùn)練 fasttext 句子向量將文本列轉(zhuǎn)換為 300d 嵌入向量。然后將在不同長度的輸入數(shù)據(jù) [1000. 10000, 100000, len(data)] 上訓(xùn)練 KNN 和 HNSW ANN 模型,以度量數(shù)據(jù)大小對速度的影響。最后將查詢兩個模型中的 K=10 和 K=100 時的最近鄰,以度量「K」對速度的影響。首先導(dǎo)入必要的包和模型。這需要一些時間,因為需要從網(wǎng)絡(luò)上下載 fasttext 模型。
# Imports # For input data pre-processing importjson importgzip importpandas aspd importnumpy asnp importmatplotlib.pyplot asplt importfasttext.util fasttext.util.download_model( ‘en’, if_exists= ‘ignore’) # English pre-trained model ft = fasttext.load_model( ‘cc.en.300.bin’) # For KNN vs ANN benchmarking fromdatetime importdatetime fromtqdm importtqdm fromsklearn.neighbors importNearestNeighbors importhnswlib
數(shù)據(jù)
使用亞[馬遜產(chǎn)品數(shù)據(jù)集],其中包含「手機及配件」類別中的 527000 種產(chǎn)品。然后運行以下代碼將其轉(zhuǎn)換為數(shù)據(jù)框架。記住僅需要產(chǎn)品 title 列,因為將使用它來搜索相似的產(chǎn)品。
# Data: http://deepyeti.ucsd.edu/jianmo/amazon/ data = [] withgzip.open( ‘meta_Cell_Phones_and_Accessories.json.gz’) asf: forl inf: data.append(json.loads(l.strip)) # Pre-Processing: https://colab.research.google.com/drive/1Zv6MARGQcrBbLHyjPVVMZVnRWsRnVMpV#scrollTo=LgWrDtZ94w89 # Convert list into pandas dataframe df = pd.DataFrame.from_dict( data) df.fillna( ‘’, inplace= True) # Filter unformatted rows df = df[~df.title.str.contains( ‘getTime’)] # Restrict to just ‘Cell Phones and Accessories’ df = df[df[ ‘main_cat’]== ‘Cell Phones & Accessories’] # Reset index df.reset_index(inplace= True, drop= True) # Only keep the title columns df = df[[ ‘title’]] # Check the df print(df.shape) df.head
如果全部都可以運行精細搜索,你將看到如下輸出:

亞馬遜產(chǎn)品數(shù)據(jù)集。
嵌入
要對文本數(shù)據(jù)進行相似性搜索,則必須首先將其轉(zhuǎn)換為數(shù)字向量。一種快速便捷的方法是使用經(jīng)過預(yù)訓(xùn)練的網(wǎng)絡(luò)嵌入層,例如 Facebook [FastText] 提供的嵌入層。由于希望所有行都具有相同的長度向量,而與 title 中的單詞數(shù)目無關(guān),所以將在 df 中的 title 列調(diào)用 get_sentence_vector 方法。
嵌入完成后,將 emb 列作為一個 list 輸入到 NN 算法中。理想情況下可以在此步驟之前進行一些文本清理預(yù)處理。同樣,使用微調(diào)的嵌入模型也是一個好主意。
# Title Embedding using FastText Sentence Embedding df[ ‘emb’] = df[ ‘title’].apply(ft.get_sentence_vector) # Extract out the embeddings column as a list of lists for input to our NN algos X = [item.tolist foritem indf[ ‘emb’].values]
基準
有了算法的輸入,下一步進行基準測試。具體而言,在搜索空間中的產(chǎn)品數(shù)量和正在搜索的 K 個最近鄰之間進行循環(huán)測試。在每次迭代中,除了記錄每種算法的耗時以外,還要檢查 pct_overlap,因為一定比例的 KNN 最近鄰也被挑選為 ANN 最近鄰。
注意整個測試在一臺全天候運行的 8 核、30GB RAM 機器上運行大約 6 天,這有些耗時。理想情況下,你可以通過多進程來加快運行速度,因為每次運行都相互獨立。
# Number of products for benchmark loop n_products = [ 1000, 10000, 100000, len(X)] # Number of neighbors for benchmark loop n_neighbors = [ 10, 100] # Dictionary to save metric results for each iteration metrics = { ‘products’:[], ‘k’:[], ‘knn_time’:[], ‘a(chǎn)nn_time’:[], ‘pct_overlap’:[]} forproducts intqdm(n_products): # “products” number of products included in the search space features = X[ :products] fork intqdm(n_neighbors): # “K” Nearest Neighbor search # KNN knn_start = datetime.now nbrs = NearestNeighbors(n_neighbors=k, metric= ‘euclidean’).fit(features) knn_distances, knn_neighbor_indices = nbrs.kneighbors(X) knn_end = datetime.now metrics[ ‘knn_time’].append((knn_end - knn_start).total_seconds) # HNSW ANN ann_start = datetime.now p = fit_hnsw_index(features, ef=k* 10) ann_neighbor_indices, ann_distances = p.knn_query(features, k) ann_end = datetime.now metrics[ ‘a(chǎn)nn_time’].append((ann_end - ann_start).total_seconds) # Average Percent Overlap in Nearest Neighbors across all “products” metrics[ ‘pct_overlap’].append(np.mean([len(np.intersect1d(knn_neighbor_indices[i], ann_neighbor_indices[i]))/k fori inrange(len(features))])) metrics[ ‘products’].append(products) metrics[ ‘k’].append(k) metrics_df = pd.DataFrame(metrics) metrics_df.to_csv( ‘metrics_df.csv’, index=False) metrics_df
運行結(jié)束時輸出如下所示。從表中已經(jīng)能夠看出,HNSW ANN 完全超越了 KNN。
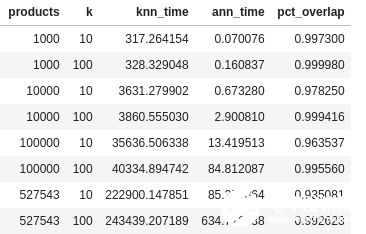
以表格形式呈現(xiàn)的結(jié)果。
結(jié)果
以圖表的形式查看基準測試的結(jié)果,以真正了解二者之間的差異,其中使用標準的 matplotlib 代碼來繪制這些圖表。這種差距是驚人的。根據(jù)查詢 K=10 和 K=100 最近鄰所需的時間,HNSW ANN 將 KNN 徹底淘汰。當搜索空間包含約 50 萬個產(chǎn)品時,在 ANN 上搜索 100 個最近鄰的速度是 KNN 的 380 倍,同時兩者搜索到最近鄰的相似度為 99.3%。
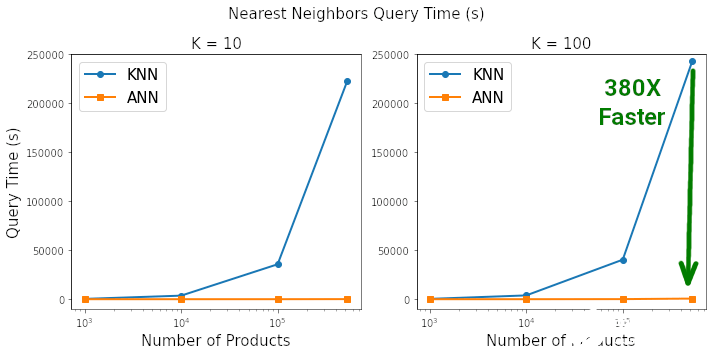
在搜索空間包含 500K 個元素,搜索空間中每個元素找到 K=100 最近鄰時,HNSW ANN 的速度比 Sklearn 的 KNN 快 380 倍。
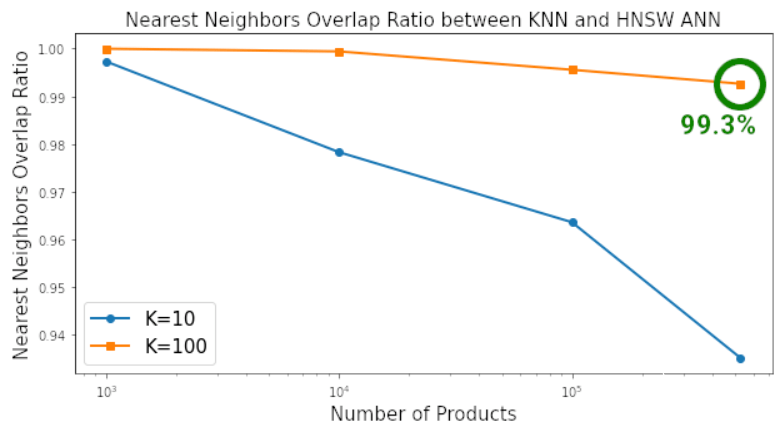
在搜索空間包含 500K 個元素,搜索空間中每個元素找到 K=100 最近鄰時,HNSW ANN 和 KNN 搜索到最近鄰的相似度為 99.3%。
基于以上結(jié)果,作者認為可以大膽地說:「KNN 已死」。
責(zé)任編輯:PSY
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7239瀏覽量
90969 -
算法
+關(guān)注
關(guān)注
23文章
4697瀏覽量
94693 -
KNN
+關(guān)注
關(guān)注
0文章
22瀏覽量
10951 -
ANN
+關(guān)注
關(guān)注
0文章
23瀏覽量
9325
發(fā)布評論請先 登錄
中科采象邀您共同研討高速數(shù)據(jù)采集在超快與X射線領(lǐng)域應(yīng)用

DD50-380S24G2N4 DD50-380S24G2N4

FA10-380S24F2N4 FA10-380S24F2N4
保障數(shù)據(jù)機房安全與穩(wěn)定性:三相380V變208V380V隔離變壓器
PID控制算法的C語言實現(xiàn):PID算法原理
ANN神經(jīng)網(wǎng)絡(luò)——器件建模

u-blox發(fā)布新型全波段GNSS天線ANN-MB2
科學(xué)家將拉曼光譜的測量速率提高100倍
【每天學(xué)點AI】KNN算法:簡單有效的機器學(xué)習(xí)分類器
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第4章-AI與生命科學(xué)讀后感
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第一章人工智能驅(qū)動的科學(xué)創(chuàng)新學(xué)習(xí)心得
opa380異常損壞,放大倍數(shù)衰減十到百倍,不可恢復(fù),為什么?
機器學(xué)習(xí)算法原理詳解
機器學(xué)習(xí)的經(jīng)典算法與應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論