 學習人工智能需要掌握什么技術
學習人工智能需要掌握什么技術

一提到人工智能,很多人都會想到不簡單,頭腦一般的人根本學不進去,格物斯坦表示:在學人工智能之前,要掌握多門相關的理論學科作為基礎,才能得心應手的去學,過程還是比較艱辛的,但一定要克服才行。
統計學。要深入理解機器學習,必須要有扎實的統計學基礎知識,這涉及到幾個方面:度量模型是否成功的各種方法(精確度、召回率、ROC曲線下面積等)。損失函數和評估指標的選擇是如何偏離模型的輸出的。如何理解過擬合和欠擬合,以及偏差/方差折衷。你對模型的結果有什么樣的信心。
機器學習理論。在訓練神經網絡的時候,實際上發生了什么?是什么使得某些任務可行,而其他任務不可行?要弄清楚這些問題,最好的方法不是深入研究理論知識,而是試著通過圖形和示例來了解機器學習。需要理解的概念范圍包括:不同的損失函數的工作原理是什么、為什么反向傳播是有用的、計算圖是什么。而對于如何建立一個功能模型,以及如何跟團隊里的其他人員進行有效地交流,這些都需要深入地理解。下面我給出了一些參考資料:
數據處理。如果你去問任何一個數據科學家他們的主要工作是什么,他們會告訴你,90%的工作是數據處理。這與應用AI同樣重要,因為模型的成功與否與數據的質量(和數量)強相關。數據工作包含多個方面,但可歸納為下面幾類:
數據采集(包括:找到好的數據源、準確度量數據的質量和分類、獲取和推斷標簽)數據預處理(缺失數據填補、特征工程、數據增強、數據規范化、交叉驗證分割)數據后處理(使模型的輸出可用、清理工作、處理特殊情況和異常值)
熟悉數據處理工作最好的方法是獲取一個數據集并試著使用它。有很多在線數據集,以及很多提供API的社交媒體和新聞媒體網站。基于上面提到的幾個步驟,我們可以這樣進行學習:獲取一個開源的數據集,并對其進行檢查。它有多大(點和特征的數量)?數據如何分布?是否存在缺失值或異常值?構建一個將原始數據轉換為可用數據的轉換流程。如何填補缺失值?如何正確處理異常值?如何規范化數據?能創造出更多的表現特征嗎?檢查轉換過的數據集。
對模型進行調試或調優。調試機器學習算法(無法收斂,或者得到的結果不合理)與調試普通代碼有著很大的區別。同時,要找出合適的架構和超參數則需要具備扎實的理論基礎和完備的基礎架構,以便對不同的配置進行徹底的測試。由于目前機器學習領域發展迅猛,而調試模型的方法也在不斷地發展。以下是從我們部署模型的討論和經驗中總結出來的“合理性檢查”列表,這些條目也以某種方式反映了許多軟件工程師熟悉的KISS原理。
從一個已經被證明可以使用類似數據集的簡單模型開始,以盡快獲得基線版本。經典的統計學習模型(線性回歸、最近鄰居等)或者簡單的啟發式算法或規則通常能幫你解決80%的問題,并且能更快地實現需求。剛開始的時候,要用最簡單的方式來解決問題(請參閱谷歌的機器學習規則的前幾點)。如果你決定訓練一個更復雜的模型以改進基線版本,那么可以用數據集的一個很小的子集來進行訓練并達到過擬合。這能夠確保這個模型至少還有學習的能力。不斷地對模型進行迭代,直到對5%的數據量過擬合。
一旦開始用更多的數據進行訓練,那么超參數就開始發揮更大的作用了。你需要理解這些參數涉及到的理論,這樣才能找到合理的值。請采用有針對性的方法對模型進行調優。簡要地記錄下你曾經使用的所有配置及其結果。在理想情況下,可以使用自動超參數搜索策略。最開始的時候,使用隨機搜索就足夠了。你的開發能力越強,則這些步驟實現起來就越快,反之亦然。
軟件工程。許多的應用機器學習允許你充分發揮自己在軟件工程方面的技能,雖然有時也會有一點小改變。這些技能包括:測試流水線的各個方面(數據的預處理和增強、輸入輸出的整理、模型推理時間)。基于模塊化和可重用的原則來構建代碼。訓練過程中的不同點對模型進行備份(設置檢查點)。配置一個分布式的基礎架構,這樣能更加有效地進行訓練、超參數搜索或者推演。
綜上所述,少年們要學好人工智能之前,知識面和動手能力方面要比平常人更出類拔萃才行,現代高科技社會需要的是優秀的奇才,而不是平庸的勞動者。
責任編輯:YYX
-
人工智能
+關注
關注
1806文章
49008瀏覽量
249321 -
機器學習
+關注
關注
66文章
8501瀏覽量
134583
發布評論請先 登錄
最新人工智能硬件培訓AI 基礎入門學習課程參考2025版(大模型篇)
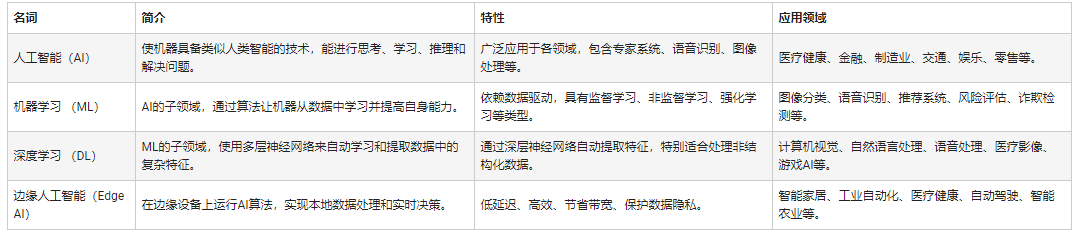
人工智能和機器學習以及Edge AI的概念與應用
人工智能發展需要新的芯片技術

嵌入式和人工智能究竟是什么關系?
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論