 Git 底層知識:詳細分析對象查詢流程和算法
Git 底層知識:詳細分析對象查詢流程和算法
本文將系統分享 Git 底層知識:對象生命周期變化,底層數據結構,數據包文件結構,數據包文件索引,以及詳細分析對象查詢流程和算法。
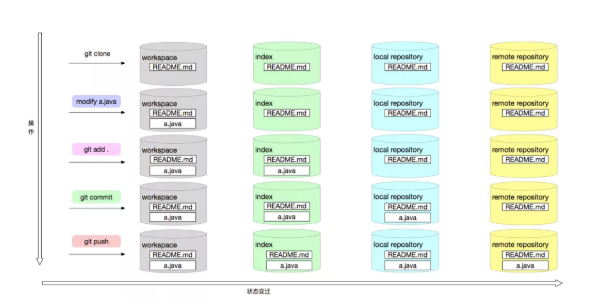
狀態模型

上圖描述了 git 對象的在不同的生命周期中不同的存儲位置,通過不同的 git 命令改變 git 對象的存儲生命周期。
工作區 (workspace)
就是我們當前工作空間,也就是我們當前能在本地文件夾下面看到的文件結構。初始化工作空間或者工作空間 clean 的時候,文件內容和 index 暫存區是一致的,隨著修改,工作區文件在沒有 add 到暫存區時候,工作區將和暫存區是不一致的。
暫存區 (index)
老版本概念也叫 Cache 區,就是文件暫時存放的地方,所有暫時存放在暫存區中的文件將隨著一個 commit 一起提交到 local repository 此時 local repository 里面文件將完全被暫存區所取代。暫存區是 git 架構設計中非常重要和難理解的一部分。
本地倉庫 (local repository)
git 是分布式版本控制系統,和其他版本控制系統不同的是他可以完全去中心化工作,你可以不用和中央服務器 (remote server) 進行通信,在本地即可進行全部離線操作,包括 log,history,commit,diff 等等。完成離線操作最核心是因為 git 有一個幾乎和遠程一樣的本地倉庫,所有本地離線操作都可以在本地完成,等需要的時候再和遠程服務進行交互。
遠程倉庫 (remote repository)
中心化倉庫,所有人共享,本地倉庫會需要和遠程倉庫進行交互,也就能將其他所有人內容更新到本地倉庫把自己內容上傳分享給其他人。結構大體和本地倉庫一樣。
文件在不同的操作下可能處于不同的 git 生命周期,下面看看一個文件變化的例子。
文件變化
對象模型
倉庫結構
git 分布式的一個重要體現是 git 在本地是有一個完整的 git 倉庫也就是 .git 文件目錄,通過這個倉庫,git 就可以完全離線化操作。在這個本地化的倉庫中存儲了 git 所有的模型對象。下面是 git 倉庫的 tree 和相關說明:

git 主要有四個對象,分別是 Blob,Tree, Commit, Tag 他們都用 SHA-1 進行命名。
你可以用 git cat-file -t 查看每個 SHA-1 的類型,用 git cat-file -p 查看每個對象的內容和簡單的數據結構。git cat-file 是 git 的瑞士軍刀,是底層核心命令。
Blob 對象
只用于存儲單個文件內容,一般都是二進制的數據文件,不包含任何其他文件信息,比如不包含文件名和其他元數據。
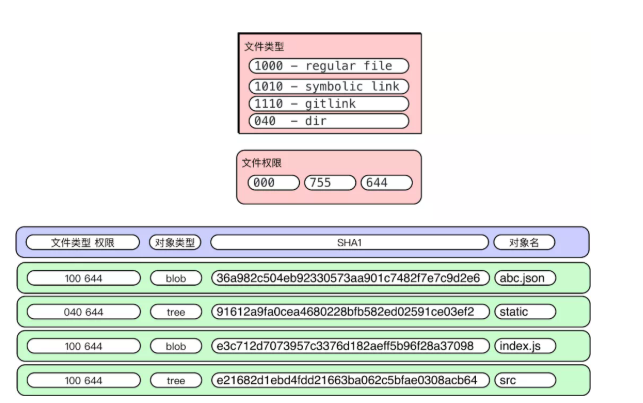
Tree 對象
對應文件系統的目錄結構,里面主要有:子目錄 (tree),文件列表 (blob),文件類型以及一些數據文件權限模型等。
如下圖輸出:

詳細解釋如下:
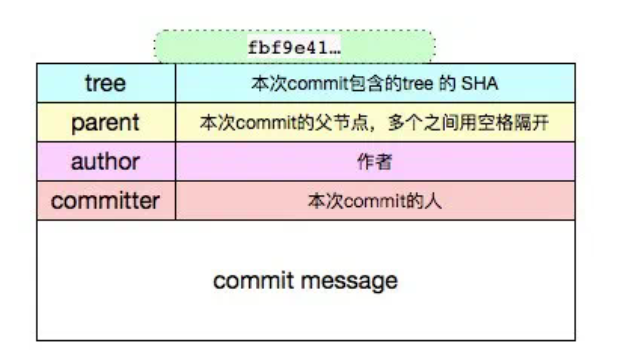
Commit 對象
是一次修改的集合,當前所有修改的文件的一個集合,可以類比一批操作的“事務”。是修改過的文件集的一個快照,隨著一次 commit 操作,修改過的文件將會被提交到 local repository 中。通過 commit 對象,在版本化中可以檢索出每次修改內容,是版本化的基石。
→ git cat-file -t fbf9e415f77008b780b40805a9bb996b37a6ad2ccommit→ git cat-file -p fbf9e415f77008b780b40805a9bb996b37a6ad2ctree bd31831c26409eac7a79609592919e9dcd1a76f2parent d62cf8ef977082319d8d8a0cf5150dfa1573c2b7author xxx 1502331401 +0800committer xxx 1502331401 +0800修復增量bug
詳細解釋如下:
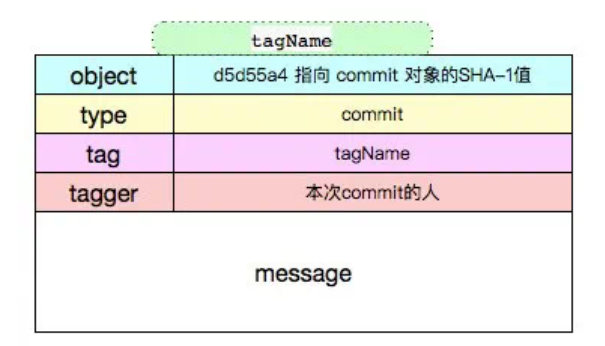
Tag 對象
tag 是一個“固化的分支”,一旦打上 tag 之后,這個 tag 代表的內容將永遠不可變,因為 tag 只會關聯當時版本庫中最后一個 commit 對象。
分支的話,隨著不斷的提交,內容會不斷的改變,因為分支指向的最后一個 commit 不斷改變。所以一般應用或者軟件版本的發布一般用 tag。
git 的 Tag 類型有兩種:
1 lightweight (輕量級)
創建方式:
git tag tagName
這種方式創建的 Tag,git 底層不會創建一個真正意義上的 tag 對象,而是直接指向一個 commit 對象,此時如果使用 git cat-file -t tagName 會返回一個 commit。
→ git cat-file -t v4commit→ git cat-file -p v4tree ceab4f96440655b0ff1a783316c95450fa1fb436parent 7f23c9ca70ce64fc58e8c7507c990c6c6a201d3dauthor 與水 1506224164 +0800committer 與水 1506224164 +0800
rawtest2
2 annotated (含附注)
創建方式:
git tag -a tagName -m‘’
這種方式創建的標簽,git 底層會創建一個 tag 對象,tag 對象會包含相關的 commit 信息和 tagger 等額外信息,此時如果使用 git cat-file -t tagname會返回一個 tag。
→ git cat-file -t v3tag→ git cat-file -p v3object d5d55a49c337d36e16dd4b05bfca3816d8bf6de8 //commit 對象SHA-1type committag v3tagger xxx 1506230900 +0800
與水測試標注型tag
總結:所有對象模型之間的關系大致如下:
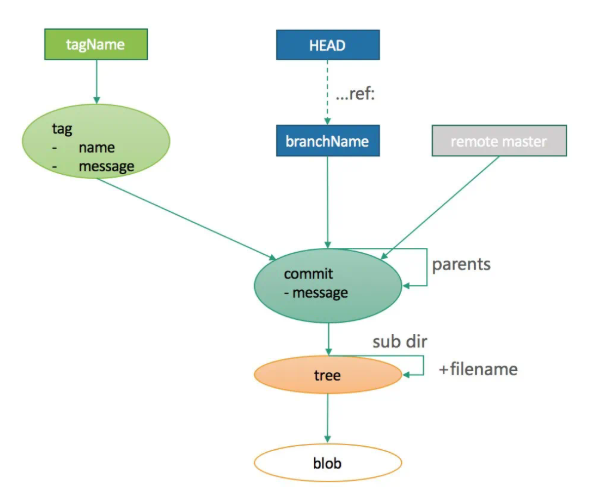
存儲模型
概念
git 區別與其他 vcs 系統的一個最主要原因之一是:git 對文件版本管理和其他 vcs 系統對文件版本的實現理念完成不一樣。這也就是 git 版本管理為什么如此強大的最核心的地方。
Svn 等其他的 VCS 對文件版本的理念是以文件為水平維度,記錄每個文件在每個版本下的 delta 改變。
Git 對文件版本的管理理念卻是以每次提交為一次快照,提交時對所有文件做一次全量快照,然后存儲快照引用。
Git 在存儲層,如果文件數據沒有改變的文件,Git 只是存儲指向源文件的一個引用,并不會直接多次存儲文件,這一點可以在 pack 文件中看見。
如下圖所示:
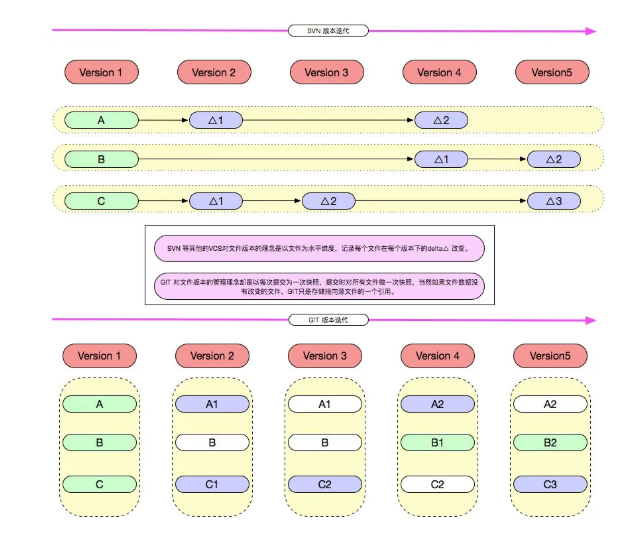
存儲
隨著需求和功能的不斷復雜,git 版本的不斷更新,但是主要的存儲模型還是大致不變。如下圖所示:
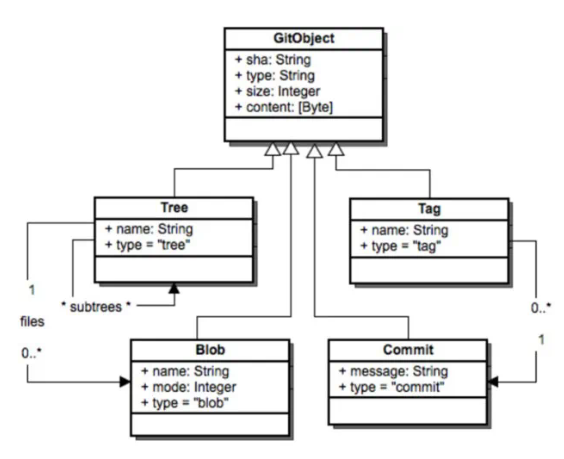
檢索模型
→ cd .git/objects/→ ls03 28 7f ce d0 d5 e6 f9 info pack
git 的對象有兩種:
一種是松散對象,就是在如上 .git/objects 的文件夾 03 28 7f ce d0 d5 e6 f9等,這些文件夾只有 2 個字符開頭,其實就是每個文件 SHA-1 值的前 2 個字母,最多有 #OXFF 256 個文件夾。
一種是打包壓縮對象,打包壓縮之后的對象主要存在的是 pack 文件中,主要用于文件在網絡上傳輸,減少網絡消耗。
為了節省存儲空間,可以手動觸發打包壓縮操作 (git gc),將松散對象打包成 pack 文件對象。也可以將 pack 文件解壓縮成松散對象 (git unpack-objects)
→ cd pack→ lspack-efbf3149604d24e6ea427b025da0c59245b2c2ea.idx pack-efbf3149604d24e6ea427b025da0c59245b2c2ea.pack
為了加快 pack 文件的檢索效率,git 基于 pack 文件會生成相應的索引 idx 文件。
pack 文件
pack 文件設計非常精密和巧妙,本著降低文件大小,減少文件傳輸,降低網絡開銷和安全傳輸的原則設計的。
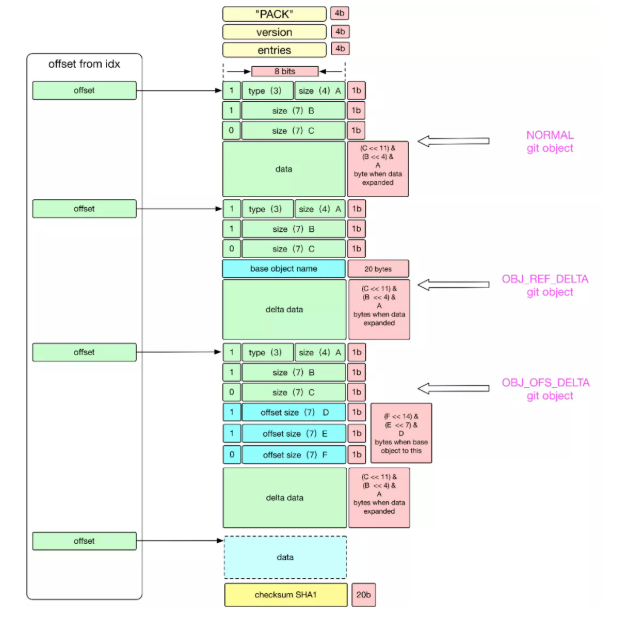
pack 文件設計的概圖如下:
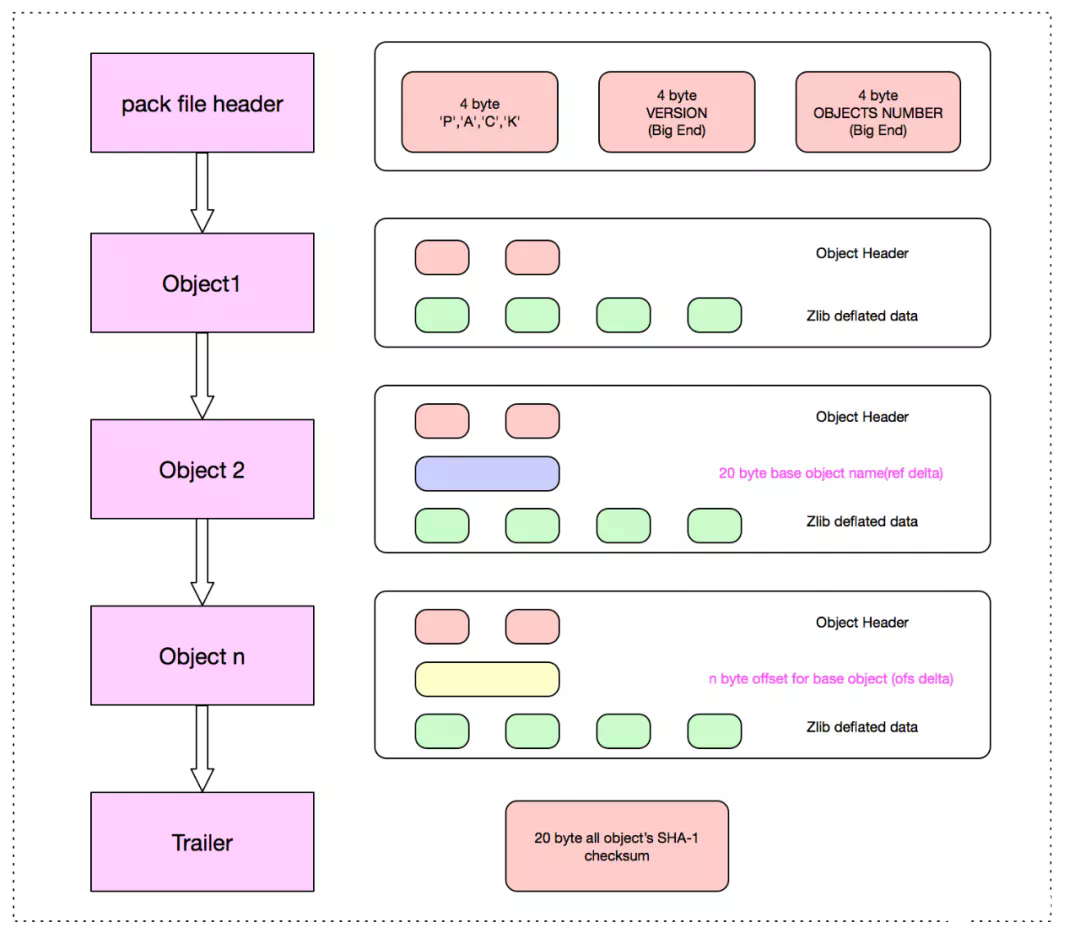
pack 文件主要有三部分組成,Header, Body, Trailer
Header 部分主要 4-byte “PACK”, 4-byte “版本號”, 4-byte “Object 條目數”。
Body 部分主要是一個個 Git 對象依次存儲,存儲位置在 idx 索引文件中記錄改對象在 pack 文件中的偏移量 offset。
Trailer 部分主要是所有 Objects 的名 (SHA-1)的校驗和,為了安全可靠的文件傳輸。
下面我們看具體的 pack 文件:
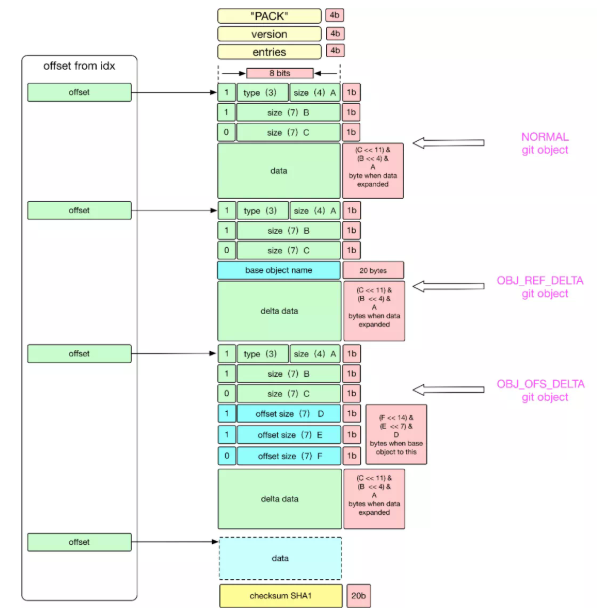
從上圖可知:通過 idx 索引文件在 pack 文件中定位到對象之后,對象的結構主要 Header 和 Data 兩部分。
1 Header 部分
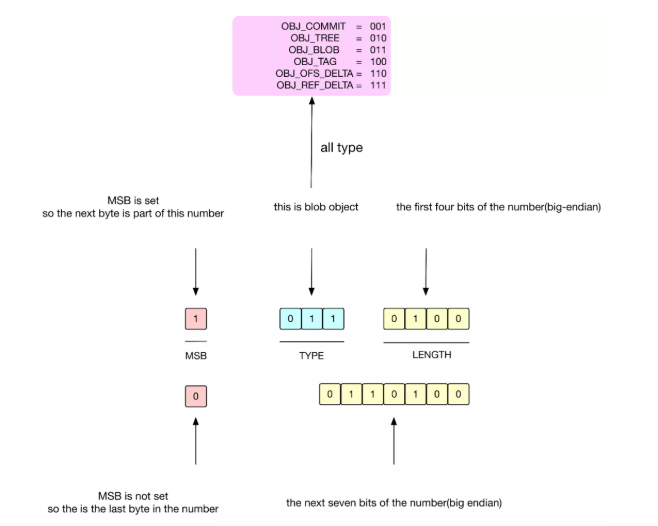
Header 中首 8-bits:1-bit 是 MSB,接著的 3-bits 表示的是當前對象類型,主要有 6種存儲類型,接著的 4-bits 是用于表示該 Object 展開的 (length) 大小的一部分,只是一部分,完整的大小取決于MSB和接下來的多個 bits,完整算法如下:
如果 8-bits 中第一位是 1,表示下一個字節還是 header 的一部分,用于表示該對象展開的大小。
如果 8-bits 中第一位是 0,表示從下一個字節開始,將是數據 Data 文件。
如果對象類型是 OBJ_OFS_DELTA 類型, 表示的是 Delta 存儲,當前 git 對象只是存儲了增量部分,對于基本的部分將由接下來的可變長度的字節數用于表示 base object 的距離當前對象的偏移量,接下來的可變字節也是用 1-bit MSB 表示下一個字節是否是可變長度的組成部分。對偏移量取負數,就可知 base 對象在當前對象的前面多少字節。
如果對象類型是 OBJ_REF_DELTA 類型,表示的是 Delta 存儲,當前 git 對象只是存儲了增量部分,對于基本的部分,用 20-bytes 存儲 Base Object 的 SHA-1 。
2 Data 部分
是經過 Zlib 壓縮過的數據。可能是全部數據,也有可能是 Delta 數據,具體看 Header 部分的存儲類型,如果是 OBJ_OFS_DELTA 或者 OBJ_REF_DELTA 此處存儲的就是增量 (Delta) 數據,此時如果要取得全量數據的話,需要遞歸的找到最 Base Object,然后 apply delta 數據,在 base object 基礎上進行 apply delta 數據也是非常精妙的,此文暫不做介紹。
從上面可以很清晰知道 pack 文件格式,我們再從本地倉庫中一探究竟:
不是增量 delta 格式:
SHA-1 type size size-in-packfile offset-in-packfile
增量 delta 格式:
如 399334856af4ca4b49c0008a25b6a9f524e40350(SHA-1) 表示對象的 base object SHA-1 是 cb5a93c4cf9c0ee5b7153a3a35a4fac7a7584804,base 對象最大深度 (depth) 為 1,如果cb5a93c4cf9c0ee5b7153a3a35a4fac7a7584804 還有引用對象,則改變 depth 為 2。
pack Header 中最后 4-bytes 用于表示的 pack 文件中 objects 的數量,最多 2 的 32 次方個對象,所以一些大的工程中有多個 pack 文件和多個 idx 文件。
文件的 size (文件解壓縮后大小) 有什么用呢,這個是為了方便我們進行解壓的時候,設置流的大小,也就是方便知道流有多大。這里 size 不是說明下一個文件的偏移量,偏移量都是來自索引文件,見下面 idx:
index 文件
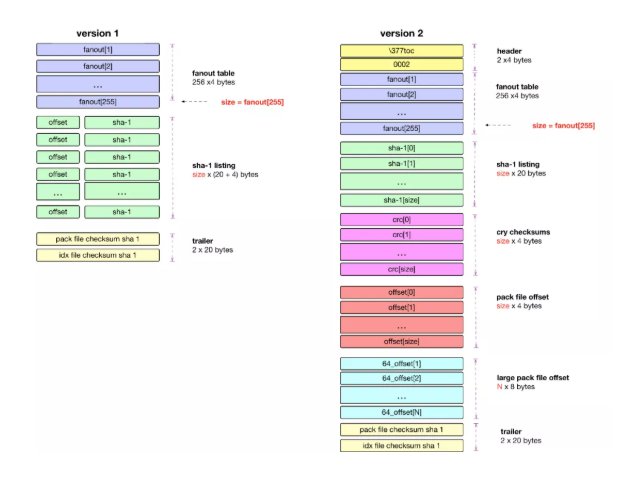
由于 version1 比較簡單,下面用 version2 為例子:
分層模式:Header,Fanout,SHA,CRC,Offset,Big File Offset,Trailer。
Header 層
version2 的 Header 部分總共有 8-bytes,version 1 的 header 部分是沒有的,前 4-bytes 總是 255, 116, 79, 99 因為這個也是版本 1 的開頭四個字節,后面 4-bytes 用于表示的是版本號,在當前就是 version 2。
Fanout 層
fanout 層是 git 的亮點設計,也叫 Fanout Table(扇表)。fanout 數組中存儲的是相關對象的數目,數組下標是對應 16 進制數。fanout 最后一個存儲的是整個 pack 文件中所有對象的總數量。Fanout Table 是整個 git 檢索的核心,通過它我們可以快速進行查詢,用于定位 SHA 層的數組起始 - 終止下標,定位好 SHA 層范圍之后,就可以對 SHA 層進行二分查找了,而不用對所有對象進行二分查找。
fanout 總共 256 個,剛好是十六進制的 #0xFF。fanout 數組用 SHA 的前面 2 個字符作為下標(對應 .git/objects 中的松散文件目錄名,將 16 進制的目錄名轉換 10 進制數字),里面值就是用這兩個字符開頭的文件數量,而且是逐層累加的,后面的數組數量是包含前面數組的數據的個數的一個累加。
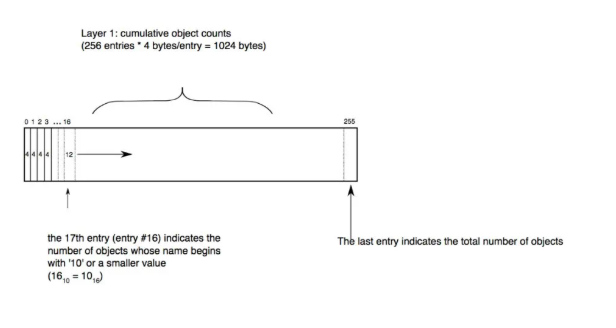
舉例如下:
1)如果數組下標為 0,且 Fanout[0] = 10 代表著 #0x00 開頭的 SHA-1 值的總數為 10 個。
2) 如果數組下標為 1,且 Fanout[1] = 15 代表著小于 #0x01 開頭的 SHA-1 值的總數為 15 個,從 Fanout[0] = 10 知 Fanout[1] = (15-10)
為什么 git 設計上 Fanout[n] 會累加 Fanout[n-1] 的數量?這個主要是為了快速確定 SHA 層檢索的初始位置,而不用每次去把前面所有 fanout[。.n-1] 數量進行累加。
SHA 層
是所有對象的 SHA-1 的排序,按照名稱排序,按照名稱進行排序是為了用二分搜索進行查找。每個 SHA-1 值占 20-bytes。
CRC 層
由于文件打包主要解決網絡傳輸問題,網絡傳輸的時候必須通過 crc 進行校驗,避免傳輸過程中的文件損壞。CRC 數組對應的是每個對象的 CRC 校驗和。
Offset 層
是由 4 byte 字節所組成,表示的是每個 SHA-1 文件的偏移量,但是如果文件大于 2G 之后,4 byte 字節將無法表示,此時將:
4 byte 中的第一 bit 就是 MSB,如果是 1 表示的是文件的偏移量是放在第 6 層去存儲,此時剩下的 31-bits 將表示文件在 Big File Offset 中的偏移量,也就是圖中的,通過 Big File Offset 層 就可以知道對象在 pack 中的 offset。
4 byte 中的第一 bit 就是 MSB,如果是 0 31-bits 表示的存儲對象在 packfile 中的文件偏移量,此時不涉及 Big File Offset 層
Big File Offset 層
用于存儲大于 2G 的文件的偏移量。如果文件大于 2G,可以通過 offset 層最后 31 bits 決定在 big file offset 中的位置,big file offset 通過 8 bytes 來表示對象在 pack 文件中的位置,理論上可以表示 2 的 64 次方文件大小。
Trailer 層
包含的是 packfile checksum 和關聯的 idx 的 checksum。
索引流程
從上面的分層知道 git 設計的巧妙。git 索引文件偏移量的查詢流程如下:
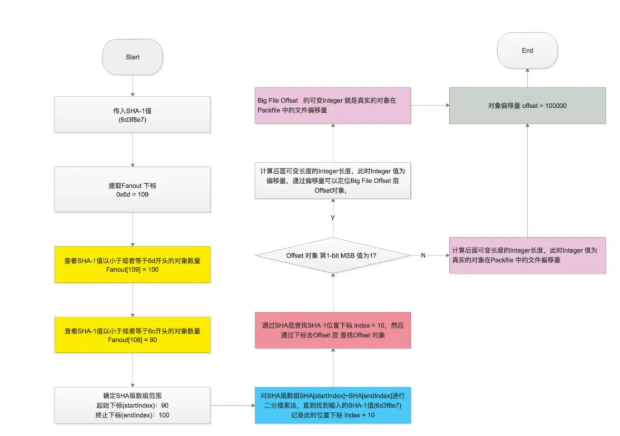
查詢算法
通過 idx 文件查詢 SHA-1 對應的偏移量:
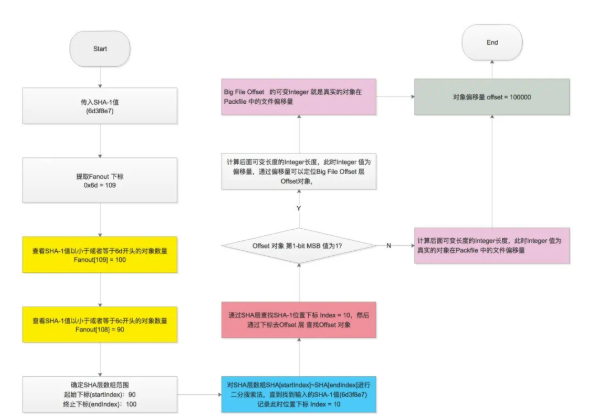
在 pack 文件中通過偏移量找到對象:
如果是普通的存儲類型。定位到的對象就是用 Zlib 壓縮之后的對象,直接解壓縮即可。
如果是 Delta 類型需要 遞歸查出 Delta 的 Base 對象,然后再把 delta data 應用到 base object 上(可參考 git-apply-delta)。
git 大多資料主要介紹是 git 使用,很少系統去講解底層數據結構和原理。本文通過多個開源代碼入手,結合 git 文檔,參考相關 git 開發者或相關研究文章,git 郵件列表等。
編輯:hfy
-
數據結構
+關注
關注
3文章
573瀏覽量
40596 -
Git
+關注
關注
0文章
203瀏覽量
16110
發布評論請先 登錄
OBOO鷗柏丨AI數字人觸摸屏查詢觸控人臉識別語音交互一體機上市

伺服電機測試流程分析
20個經典模擬電路及詳細分析答案
SVPWM的原理及法則推導和控制算法詳解
機房托管費詳細分析
數控加工工藝流程詳解
光柵的偏振分析
adss光纜顏色詳細分析
美國站群vps云服務器缺點詳細分析
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+內容簡介
淺談無刷電機的工作流程
如何分析美國站群服務器的成本效益?

NMOS LDO原理概括 NMOS LDO原理詳細分析






 工商網監
工商網監
評論