 關于哈希表沖突解決策略解析
關于哈希表沖突解決策略解析
哈希是一種通過對數據進行壓縮, 從而提高效率的一種解決方法,但由于哈希函數有限,數據增大等緣故,哈希沖突成為數據有效壓縮的一個難題。本文主要介紹哈希沖突、解決方案,以及各種哈希沖突的解決策略上的優缺點。
一、哈希表概述
哈希表的哈希函數輸入一個鍵,并向返回一個哈希表的索引。可能的鍵的集合很大,但是哈希函數值的集合只是表的大小。
哈希函數的其他用途包括密碼系統、消息摘要系統、數字簽名系統,為了使這些應用程序按預期工作,沖突的概率必須非常低,因此需要一個具有非常大的可能值集合的散列函數。
密碼系統:給定用戶密碼,操作系統計算其散列,并將其與存儲在文件中的該用戶的散列進行比較。(不要讓密碼很容易被猜出散列到相同的值)。
消息摘要系統:給定重要消息,計算其散列,并將其與消息本身分開發布。希望檢查消息有效性的讀者也可以使用相同的算法計算其散列,并與發布的散列進行比較。(不要希望偽造消息很容易,仍然得到相同的散列)。
這些應用的流行哈希函數算法有:
md5 : 2^128個值(找一個沖突鍵,需要哈希大約2 ^ 64個值)
sha-1:2^160個值(找一個沖突鍵,需要大約2^80個值)
二、哈希沖突
來看一個簡單的實例吧,假設采用hash函數:H(K) = K mod M,插入這些值:217、701、19、30、145
H(K) = 217 % 7 = 0
H(K) = 701 % 7 = 1
H(K) = 19 % 7 = 2
H(K) = 30 % 7 = 2
H(K) = 145 % 7 = 5
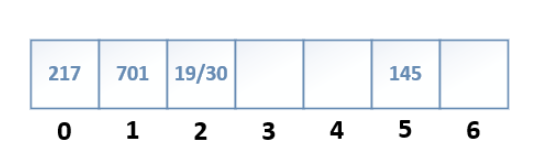
上面實例很明顯 19 和 30 就發生沖突了。
三、沖突解決策略
除非您要進行“完美的散列”,否則必須具有沖突解決策略,才能處理表中的沖突。
同時,該策略必須允許查找,插入和刪除正確運行的操作!
沖突解決技術可以分為兩類:開散列方法( open hashing,也稱為拉鏈法,separate chaining )和閉散列方法( closed hashing,也稱為開地址方法,open addressing )。這兩種方法的不同之處在于:開散列法把發生沖突的關鍵碼存儲在散列表主表之外,而閉散列法把發生沖突的關鍵碼存儲在表中另一個槽內。
下面介紹業內比較流行的hash沖突解決策略:
線性探測(Linear probing)
雙重哈希(Double hashing)
隨機散列(Random hashing)
分離鏈接(Separate chaining)上面線性探測、雙重哈希、隨機散列都是閉散列法,而分離鏈接則是開散列法。
1、線性探測(Linear probing)
插入一個值
使用散列函數H(K)在大小為M的表中插入密鑰K時:
設置 indx = H(K)
如果表位置indx已經包含密鑰,則無需插入它。Over
否則,如果表位置indx為空,則在其中插入鍵。Over
其他碰撞。設置 indx =(indx + 1)mod M.
如果 indx == H(K),則表已滿!就只能做哈希表的擴容了因此,線性探測基本上是在發生碰撞時對空槽進行線性搜索。
優點:易于實施;總是找到一個位置(如果有);當表不是很滿時,平均情況下的性能非常好。
缺點:表的相鄰插槽中會形成“集群”或“集群”鍵;當這些簇填滿整個陣列的大部分時,性能會嚴重下降,因為探針序列執行的工作實際上是對大部分陣列的窮舉搜索。
簡單例子
如哈希表大小M = 7, 哈希函數:H(K) = K mod M。插入這些值:701, 145, 217, 19, 13, 749
H(K) = 701 % 7 = 1
H(K) = 145 % 7 = 5
H(K) = 217 % 7 = 0
H(K) = 19 % 7 = 2
H(K) = 13 % 7 = 1(沖突) --》 2(已經有值) --》 3(插入位置3)
H(K) = 749 % 7 = 2(沖突) --》 3(已經有值) --》 4(插入位置4)
可見,如果哈希表如果不是很大,隨著數據插入,沖突也會組件發生,探針遍歷次數將會逐漸變低,檢索過程也就成為窮舉。
檢索一個值
如果使用線性探測將鍵插入表中,則線性探測將找到它們!
當使用散列函數 H(K)在大小為N的表中搜索鍵K時:
設置 indx = H(K)
如果表位置indx包含鍵,則返回FOUND。
否則,如果表位置 indx 為空,則返回NOT FOUND。
否則設置 indx =(indx + 1)modM。
如果 indx == H(K),則返回NOT FOUND。就只能做哈希表的擴容了問題:如何從使用線性探測的表中刪除鍵?
能否進行“延遲刪除”,而只是將已刪除密鑰的插槽標記為空?
很明顯,在線性探測很難做到,如果把位置置為空,那么如果后面的值也是哈希沖突,線性探測插入,則再也無法遍歷這些值了。
2、雙重哈希(Double hashing)
線性探測沖突解決方案會導致表中出現簇,因為如果兩個鍵發生碰撞,則探測到的下一個位置對于這兩個鍵都是相同的。
雙重哈希的思想:使偏移到下一個探測到的位置取決于鍵值,因此對于不同的鍵可以不同。
需要引入第二個哈希函數 H 2(K),用作探測序列中的偏移量(將線性探測視為 H 2(K)== 1 的雙重哈希)。
對于大小為 M 的哈希表,H 2(K)的值應在 1到M-1 的范圍內;如果M為質數,則一個常見選擇是 H2(K)= 1 +((K / M)mod(M-1))。
然后,用于雙哈希的插入算法為:
設置 indx = H(K); offset = H 2(K)
如果表位置indx已經包含密鑰,則無需插入它。Over
否則,如果表位置 indx 為空,則在其中插入鍵。Over
其他碰撞。設置 indx =(indx + offset)mod M.
如果 indx == H(K),則表已滿!就只能做哈希表的擴容了
哈希表為質數情況,雙重hash在實踐中非常有效
雙重 Hash 也見:https://blog.csdn.net/chenxuegui1234/article/details/103454285
3、隨機散列(Random hashing)
與雙重哈希一樣,隨機哈希通過使探測序列取決于密鑰來避免聚類。
使用隨機散列時,探測序列是由密鑰播種的偽隨機數生成器的輸出生成的(可能與另一個種子組件一起使用,該組件對于每個鍵都是相同的,但是對于不同的表是不同的)。
然后,用于隨機哈希的插入算法為:
創建以 K 為種子的 RNG。設置indx = RNG.next() mod M。
如果表位置 indx 已經包含密鑰,則無需插入它。Over
否則,如果表位置 indx 為空,則在其中插入鍵。Over
其他碰撞。設置 indx = RNG.next() mod M.
如果已探測所有M個位置,則放棄。就只能做哈希表的擴容了。
隨機散列很容易分析,但是由于隨機數生成的“費用”,它并不經常使用。雙重哈希在實踐中還是經常被使用。
4、分離鏈接(Separate chaining)
在具有哈希函數 H(K)的表中插入鍵K時
設置 indx = H(K)
將關鍵字插入到以 indx 為標題的鏈接列表中。(首先搜索列表,以避免重復。)
在具有哈希函數H(K)的表中搜索鍵K時
設置 indx = H(K)
使用線性搜索在以 indx 為標題的鏈表中搜索關鍵字。
使用哈希函數 H(K)刪除表中的鍵K時
設置 indx = H(K)
刪除鏈接列表中以 indx 為標題的鍵
優點:隨著條目數量的增加,平均案例性能保持良好。甚至超過M;刪除比開放地址更容易實現。
缺點:需要動態數據,除數據外還需要存儲指針,本地性較差,導致緩存性能較差。
很明顯,Java7 的 HashMap 就是一種分裂鏈接的實現方式。
分離鏈哈希分析
請記住表的填充程度的負載系數度量:α = N / M。
其中M是表格的大小,并且 N 是表中已插入的鍵數。
通過單獨的鏈接,可以使 α》 1 給定負載因子α,我們想知道在最佳,平均和最差情況下的時間成本。
成功找到
新鍵插入和查找失敗(這些相同),最好的情況是O(1),最壞的情況是O(N)。讓我們分析平均情況
分裂鏈接的平均成本
假設負載系數為 α = N / M 的表
在M個鏈接列表中總共分配了N個項目(其中一些可能為空),因此每個鏈接列表的平均項目數為:
如果查找/插入失敗,則必須窮舉搜索表中的鏈表之一,并且表中鏈表的平均長度為α。因此,使用單獨鏈接進行插入或不成功查找的比較平均次數為
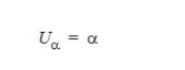
成功查找后,將搜索包含目標密鑰的鏈接列表。除目標密鑰外,該列表中平均還有(N-1)/ M個密鑰;在找到目標之前,將平均搜索其中一半。因此,使用單獨鏈接成功找到的比較平均次數為
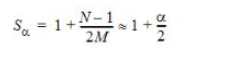
當α《1時,它們分別小于1和1.5。并且即使當α超過1時,它們仍然是O(1),與N無關。
四、開散列方法 VS 閉散列方法
如果將鍵保留為哈希表本身中的條目,則可以使用線性探測,雙重和隨機哈希。.. 這樣做稱為“開放式尋址”,也稱為“封閉式哈希”。
另一個想法:哈希表中的條目只是指向鏈表(“鏈”)頭部的指針;鏈接列表的元素包含鍵。.. 這稱為“單獨鏈接”,也稱為“開放式哈希”。
通過單獨的鏈接,沖突解決變得容易:只要在其鏈表中插入一個鍵,就可以將其插入(為此,可以使用比鏈表更高級的數據結構;但是正如我們將看到的,鏈表在一般情況下效果很好)。
讓下面我們看一下這些策略的時間成本。
開放式地址哈希分析
分析哈希表“查找”或“插入”性能時,一個有用的參數是負載系數 α = N / M。
其中 M 是表格的大小,并且 N 是表中已插入的鍵數負載系數是表滿度的一種度量。
給定負載因子 α ,我們想知道在最佳,平均和最差情況下的時間成本。
成功找到
對所有鍵,最好的情況是O(1),最壞的情況是O(N),新鍵插入和查找失敗(這些相同),所以讓我們分析平均情況。
我們將給出隨機哈希和線性探測的結果。實際上,雙重哈希類似于隨機哈希;
平均不成功的查找/插入成本
假定負載系數為α= N / M的表。考慮隨機散列,因此聚類不是問題。每個探針位置是隨機且獨立生成的對于每個探針,找到空位置的可能性為(1-α)。查找空位置將停止查找或插入,這是一個伯努利過程,成功概率為(1-α)。該過程的預期一階到達時間為 1 /(1-α)。所以:
使用隨機哈希進行插入或不成功查找的探針的平均數量為
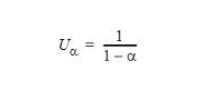
使用線性探測時,探頭的位置不是獨立的。團簇形成,當負載系數高時會導致較長的探針序列。可以證明,用于線性探測的插入或未成功發現的探針的平均數量約為
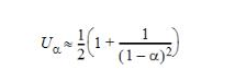
當 α 接近1時,這些平均案例時間成本很差,僅受M限制;但當 α 等于或小于7.75(與M無關)時,效果還不錯(分別為4和8.5)
平均成功查找成本
假定負載系數為 α= N / M 的表。考慮隨機散列,因此聚類不是問題。每個探針位置是隨機且獨立生成的。
對于表中的鍵,成功找到它所需的探針數等于將其插入表中時所采用的探針數。每個新密鑰的插入都會增加負載系數,從0開始到α。
因此,通過隨機散列成功發現的探測器的平均數量為
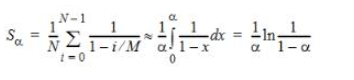
通過線性探測,會形成簇,從而導致更長的探針序列。可以證明,通過線性探測成功發現的平均探針數為
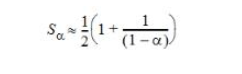
當α接近1時,這些平均案例時間成本很差,僅受M限制;但當α等于或小于7.75時好(分別為1.8和2.5),與M無關。
編輯:hfy
-
哈希函數
+關注
關注
0文章
43瀏覽量
9569 -
哈希表
+關注
關注
0文章
9瀏覽量
4941
發布評論請先 登錄
序列化哈希表到文件
基于多維整數空間的安全策略沖突檢測與消解
智能安全防護軟件策略構件的設計與實現
基于硬件的千萬級哈希流表查找架構

哈希表是什么?哈希表數據結構詳細資料分析
哈希表是什么?為什么需要使用哈希表
基于C++哈希表解決沖突






 工商網監
工商網監
評論