") 結(jié)合阿里云上的EMR JindoFS優(yōu)化和實(shí)踐,數(shù)據(jù)湖怎么玩“加速”?
結(jié)合阿里云上的EMR JindoFS優(yōu)化和實(shí)踐,數(shù)據(jù)湖怎么玩“加速”?
湖加速即為數(shù)據(jù)湖加速,是指在數(shù)據(jù)湖架構(gòu)中,為了統(tǒng)一支持各種計(jì)算,對(duì)數(shù)據(jù)湖存儲(chǔ)提供適配支持,進(jìn)行優(yōu)化和緩存加速的中間層技術(shù)。那么為什么需要湖加速?數(shù)據(jù)湖如何實(shí)現(xiàn)“加速”?本文將從三個(gè)方面來(lái)介紹湖加速背后的原因,分享阿里云在湖加速上的實(shí)踐經(jīng)驗(yàn)和技術(shù)方案。
在開(kāi)源大數(shù)據(jù)領(lǐng)域,存儲(chǔ)/計(jì)算分離已經(jīng)成為共識(shí)和標(biāo)準(zhǔn)做法,數(shù)據(jù)湖架構(gòu)成為大數(shù)據(jù)平臺(tái)的首要選擇。基于這一范式,大數(shù)據(jù)架構(gòu)師需要考慮三件事情:
第一,選擇什么樣的存儲(chǔ)系統(tǒng)做數(shù)據(jù)湖(湖存儲(chǔ))? 第二,計(jì)算和存儲(chǔ)分離后,出現(xiàn)了性能瓶頸,計(jì)算如何加速和優(yōu)化(湖加速)? 第三,針對(duì)需要的計(jì)算場(chǎng)景,選擇什么樣的計(jì)算引擎(湖計(jì)算)?
湖存儲(chǔ)可以基于我們熟悉的HDFS,在公共云上也可以選擇對(duì)象存儲(chǔ),例如阿里云OSS。在公共云上,基于對(duì)象存儲(chǔ)構(gòu)建數(shù)據(jù)湖是目前業(yè)界最主流的做法,我們這里重點(diǎn)探討第二個(gè)問(wèn)題,結(jié)合阿里云上的EMR JindoFS優(yōu)化和實(shí)踐,看看數(shù)據(jù)湖怎么玩“加速”。
湖加速
在數(shù)據(jù)湖架構(gòu)里,湖存儲(chǔ)(HDFS,阿里云OSS)和湖計(jì)算(Spark,Presto)都比較清楚。那么什么是湖加速?大家不妨搜索一下…(基本沒(méi)有直接的答案)。湖加速是阿里云EMR同學(xué)在內(nèi)部提出來(lái)的,顧名思義,湖加速即為數(shù)據(jù)湖加速,是指在數(shù)據(jù)湖架構(gòu)中,為了統(tǒng)一支持各種計(jì)算,對(duì)數(shù)據(jù)湖存儲(chǔ)提供適配支持,進(jìn)行優(yōu)化和緩存加速的中間層技術(shù)。這里面出現(xiàn)較早的社區(qū)方案應(yīng)該是Alluxio,Hadoop社區(qū)有S3A Guard,AWS有EMRFS,都適配和支持AWS S3,Snowflake在計(jì)算側(cè)有SSD緩存,Databricks有DBIO/DBFS,阿里云有EMR JindoFS,大體都可以歸為此類技術(shù)。
那么為什么需要湖加速呢?這和數(shù)據(jù)湖架構(gòu)分層,以及相關(guān)技術(shù)演進(jìn)具有很大關(guān)系。接下來(lái),我們從三個(gè)方面的介紹來(lái)尋找答案。分別是:基礎(chǔ)版,要適配;標(biāo)配版,做緩存;高配版,深度定制。JindoFS同時(shí)涵蓋這三個(gè)層次,實(shí)現(xiàn)數(shù)據(jù)湖加速場(chǎng)景全覆蓋。
基礎(chǔ)版:適配對(duì)象存儲(chǔ)
以Hadoop為基礎(chǔ)的大數(shù)據(jù)和在AWS上以EC2/S3為代表的云計(jì)算,在它們發(fā)展的早期,更像是在平行的兩個(gè)世界。等到EMR產(chǎn)品出現(xiàn)后,怎么讓大數(shù)據(jù)計(jì)算(最初主要是MapReduce)對(duì)接S3,才成為一個(gè)真實(shí)的技術(shù)命題。對(duì)接S3、OSS對(duì)象存儲(chǔ),大數(shù)據(jù)首先就要適配對(duì)象接口。Hadoop生態(tài)的開(kāi)源大數(shù)據(jù)引擎,比如Hive和Spark,過(guò)去主要是支持HDFS,以Hadoop Compatible File System(HCFS)接口適配、并支持其他存儲(chǔ)系統(tǒng)。機(jī)器學(xué)習(xí)生態(tài)(Python)以POSIX接口和本地文件系統(tǒng)為主,像TensorFlow這種深度學(xué)習(xí)框架當(dāng)然也支持直接使用HDFS 接口。對(duì)象存儲(chǔ)產(chǎn)品提供REST API,在主要開(kāi)發(fā)語(yǔ)言上提供封裝好的SDK,但都是對(duì)象存儲(chǔ)語(yǔ)義的,因此上述這些流行的計(jì)算框架要用,必須加以適配,轉(zhuǎn)換成HCFS接口或者支持POSIX。這也是為什么隨著云計(jì)算的流行,適配和支持云上對(duì)象存儲(chǔ)產(chǎn)品成為Hadoop社區(qū)開(kāi)發(fā)的一個(gè)熱點(diǎn),比如S3A FileSytem。阿里云EMR團(tuán)隊(duì)則大力打造JindoFS,全面支持阿里云OSS并提供加速優(yōu)化。如何高效地適配,并不是設(shè)計(jì)模式上增加一層接口轉(zhuǎn)換那么簡(jiǎn)單,做好的話需要理解兩種系統(tǒng)(對(duì)象存儲(chǔ)和文件系統(tǒng))背后的重要差異。我們稍微展開(kāi)一下:
第一,海量規(guī)模。
對(duì)象存儲(chǔ)提供海量低成本存儲(chǔ),相比文件系統(tǒng)(比如HDFS),阿里云OSS更被用戶認(rèn)為可無(wú)限擴(kuò)展。同時(shí)隨著各種BI技術(shù)和AI技術(shù)的流行和普及,挖掘數(shù)據(jù)的價(jià)值變得切實(shí)可行,用戶便傾向于往數(shù)據(jù)湖(阿里云OSS)儲(chǔ)存越來(lái)越多不同類型的數(shù)據(jù),如圖像、語(yǔ)音、日志等等。這在適配層面帶來(lái)的挑戰(zhàn)就是,需要處理比傳統(tǒng)文件系統(tǒng)要大許多的數(shù)據(jù)量和文件數(shù)量。千萬(wàn)級(jí)文件數(shù)的超大目錄屢見(jiàn)不鮮,甚至包含大量的小文件,面對(duì)這種目錄,一般的適配操作就失靈了,不是OOM就是hang在那兒,根本就不可用。JindoFS一路走來(lái)積累了很多經(jīng)驗(yàn),我們對(duì)大目錄的listing操作和du/count這種統(tǒng)計(jì)操作從內(nèi)存使用和充分并發(fā)進(jìn)行了深度優(yōu)化,目前達(dá)到的效果是,千萬(wàn)文件數(shù)超大目錄,listing操作比社區(qū)版本快1倍,du/count快21%,整體表現(xiàn)更為穩(wěn)定可靠。
第二,文件和對(duì)象的映射關(guān)系。
對(duì)象存儲(chǔ)提供key到blob對(duì)象的映射,這個(gè)key的名字空間是扁平的,本身并不具備文件系統(tǒng)那樣的層次性,因此只能在適配層模擬文件/目錄這種層次結(jié)構(gòu)。正是因?yàn)橐磕M,而不是原生支持,一些關(guān)鍵的文件/目錄操作代價(jià)昂貴,這里面最為知名的就是rename了。文件rename或者mv操作,在文件系統(tǒng)里面只是需要把該文件的inode在目錄樹(shù)上挪動(dòng)下位置即可,一個(gè)原子操作;但是在對(duì)象存儲(chǔ)上,往往受限于內(nèi)部的實(shí)現(xiàn)方式和提供出來(lái)的標(biāo)準(zhǔn)接口,適配器一般需要先copy該對(duì)象到新位置,然后再把老對(duì)象delete掉,用兩個(gè)獨(dú)立的步驟和API調(diào)用。對(duì)目錄進(jìn)行rename操作則更為復(fù)雜,涉及到該目錄下的所有文件的rename,而每一個(gè)都是上述的copy+delete;如果目錄層次很深,這個(gè)rename操作還需要遞歸嵌套,涉及到數(shù)量巨大的客戶端調(diào)用次數(shù)。對(duì)象的copy通常跟它的size相關(guān),在很多產(chǎn)品上還是個(gè)慢活,可以說(shuō)是雪上加霜。阿里云OSS在這方面做了很多優(yōu)化,提供Fast Copy能力,JindoFS充分利用這些優(yōu)化支持,結(jié)合客戶端并發(fā),在百萬(wàn)級(jí)大目錄rename操作上,性能比社區(qū)版本接近快3X。
第三,一致性。
為了追求超大并發(fā),不少對(duì)象存儲(chǔ)產(chǎn)品提供的是最終一致性(S3),而不是文件系統(tǒng)常見(jiàn)的強(qiáng)一致性語(yǔ)義。這帶來(lái)的影響就是,舉個(gè)栗子,程序明明往一個(gè)目錄里面剛剛寫(xiě)好了10個(gè)文件,結(jié)果隨后去list,可能只是部分文件可見(jiàn)。這個(gè)不是性能問(wèn)題,而是正確性了,因此在適配層為了滿足大數(shù)據(jù)計(jì)算的需求,Hadoop社區(qū)在S3A適配上花了很大力氣處理應(yīng)對(duì)這種問(wèn)題,AWS自己也類似提供了EMRFS,支持ConsistentView。阿里云OSS提供了強(qiáng)一致性,JindoFS基于這一特性大大簡(jiǎn)化,用戶和計(jì)算框架使用起來(lái)也無(wú)須擔(dān)心類似的一致性和正確性問(wèn)題。
第四,原子性。
對(duì)象存儲(chǔ)自身沒(méi)有目錄概念,目錄是通過(guò)適配層模擬出來(lái)的。對(duì)一個(gè)目錄的操作就轉(zhuǎn)化為對(duì)該目錄下所有子目錄和文件的客戶端多次調(diào)用操作,因此即使是每次對(duì)象調(diào)用操作是原子的,但對(duì)于用戶來(lái)說(shuō),對(duì)這個(gè)目錄的操作并不能真正做到原子性。舉個(gè)例子,刪除目錄,對(duì)其中任何一個(gè)子目錄或文件的刪除操作失敗(包含重試),哪怕其他文件刪除都成功了,這個(gè)目錄刪除操作整體上還是失敗。這種情況下該怎么辦?通常只能留下一個(gè)處于中間失敗狀態(tài)的目錄。JindoFS在適配這些目錄操作(rename,copy,delete and etc)的時(shí)候,結(jié)合阿里云 OSS 的擴(kuò)展和優(yōu)化支持,在客戶端盡可能重試或者回滾,能夠很好地銜接數(shù)據(jù)湖各種計(jì)算,在pipeline 上下游之間保證正確處理。
第五,突破限制。
對(duì)象存儲(chǔ)產(chǎn)品是獨(dú)立演化發(fā)展的,少不了會(huì)有自己的一些獨(dú)門秘籍,這種特性要充分利用起來(lái)可能就得突破HCFS抽象接口的限制。這里重點(diǎn)談下對(duì)象存儲(chǔ)的高級(jí)特性Concurrent MultiPartUpload (CMPU),該特性允許程序按照分片并發(fā)上傳part的方式高效寫(xiě)入一個(gè)大對(duì)象,使用起來(lái)有兩個(gè)好處,一個(gè)是可以按照并發(fā)甚至是分布式的方式寫(xiě)入一個(gè)大對(duì)象,實(shí)現(xiàn)高吞吐,充分發(fā)揮對(duì)象存儲(chǔ)的優(yōu)勢(shì);另外一個(gè)是,所有parts都是先寫(xiě)入到一個(gè)staging區(qū)域的,直到complete的時(shí)候整個(gè)對(duì)象才在目標(biāo)位置出現(xiàn)。利用阿里云OSS這個(gè)高級(jí)特性,JindoFS開(kāi)發(fā)了一個(gè)針對(duì)MapReduce模型的Job Committer,用于Hadoop,Spark 和類似框架,其實(shí)現(xiàn)機(jī)制是各個(gè)任務(wù)先將計(jì)算結(jié)果按照part寫(xiě)入到臨時(shí)位置,然后作業(yè)commit的時(shí)候再complete這些結(jié)果對(duì)象到最終位置,實(shí)現(xiàn)無(wú)須rename的效果。我們?cè)贔linkfile sink connector支持上也同樣往計(jì)算層透出這方面的額外接口,利用這個(gè)特性支持了Exactly-Once的語(yǔ)義。
標(biāo)配版:緩存加速
數(shù)據(jù)湖架構(gòu)對(duì)大數(shù)據(jù)計(jì)算的另外一個(gè)影響是存/算分離。存儲(chǔ)和計(jì)算分離,使得存儲(chǔ)和計(jì)算在架構(gòu)上解耦,存儲(chǔ)朝著大容量低成本規(guī)模化供應(yīng),計(jì)算則向著彈性伸縮,豐富性和多樣化向前發(fā)展,在整體上有利于專業(yè)化分工和大家把技術(shù)做深,客戶價(jià)值也可以實(shí)現(xiàn)最大化。但是這種分離架構(gòu)帶來(lái)一個(gè)重要問(wèn)題就是,存儲(chǔ)帶寬的供應(yīng)在一些情況下可能會(huì)跟計(jì)算對(duì)存儲(chǔ)帶寬的需求不相適應(yīng)。計(jì)算要跨網(wǎng)絡(luò)訪問(wèn)存儲(chǔ),數(shù)據(jù)本地性消失,訪問(wèn)帶寬整體上會(huì)受限于這個(gè)網(wǎng)絡(luò);更重要的是,在數(shù)據(jù)湖理念下,多種計(jì)算,越來(lái)越多的計(jì)算要同時(shí)訪問(wèn)數(shù)據(jù),會(huì)競(jìng)爭(zhēng)這個(gè)帶寬,最終使得帶寬供需失衡。我們?cè)诖罅康膶?shí)踐中發(fā)現(xiàn),同一個(gè)OSS bucket,Hive/Spark數(shù)倉(cāng)要進(jìn)行ETL,Presto要交互式分析,機(jī)器學(xué)習(xí)也要抽取訓(xùn)練數(shù)據(jù),這個(gè)在數(shù)據(jù)湖時(shí)代之前不可想象,那個(gè)時(shí)候也許最多的就是MapReduce作業(yè)了。這些多樣化的計(jì)算,對(duì)數(shù)據(jù)訪問(wèn)性能和吞吐的需求卻不遑多讓甚至是變本加厲。常駐的集群希望完成更多的計(jì)算;彈性伸縮的集群則希望盡快完成作業(yè),把大量節(jié)點(diǎn)給釋放掉節(jié)省成本;像Presto這種交互式分析業(yè)務(wù)方希望是越快越好,穩(wěn)定亞秒級(jí)返回不受任何其他計(jì)算影響;而GPU訓(xùn)練程序則是期望數(shù)據(jù)完全本地化一樣的極大吞吐。像這種局面該如何破呢?無(wú)限地增加存儲(chǔ)側(cè)的吞吐是不現(xiàn)實(shí)的,因?yàn)檎w上受限于和計(jì)算集群之間的網(wǎng)絡(luò)。有效地保證豐富的計(jì)算對(duì)存儲(chǔ)帶寬的需求,業(yè)界早已給出的答案是計(jì)算側(cè)的緩存。Alluxio一直在做這方面的事情,JindoFS核心定位是數(shù)據(jù)湖加速層,其思路也同出一轍。下面是它在緩存場(chǎng)景上的架構(gòu)圖。
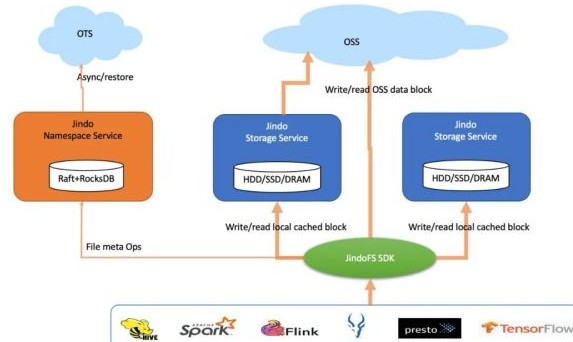
JindoFS在對(duì)阿里云OSS適配優(yōu)化的同時(shí),提供分布式緩存和計(jì)算加速,剛剛寫(xiě)出去的和重復(fù)訪問(wèn)的數(shù)據(jù)可以緩存在本地設(shè)備上,包括HDD,SSD和內(nèi)存,我們都分別專門優(yōu)化過(guò)。這種緩存加速是對(duì)用戶透明的,本身并不需要計(jì)算額外的感知和作業(yè)修改,在使用上只需要在OSS適配的基礎(chǔ)上打開(kāi)一個(gè)配置開(kāi)關(guān),開(kāi)啟數(shù)據(jù)緩存。疊加我們?cè)谶m配上的優(yōu)化,跟業(yè)界某開(kāi)源緩存方案相比,我們?cè)诙鄠€(gè)計(jì)算場(chǎng)景上都具有顯著的性能領(lǐng)先優(yōu)勢(shì)。基于磁盤緩存,受益于我們能夠更好地balance多塊磁盤負(fù)載和高效精細(xì)化的緩存塊管理,我們用TPC-DS 1TB進(jìn)行對(duì)比測(cè)試,SparkSQL性能快27%;Presto大幅領(lǐng)先93%;在HiveETL場(chǎng)景上,性能領(lǐng)先42%。JindoFS 的 FUSE支持完全采用 native 代碼開(kāi)發(fā)而沒(méi)有 JVM 的負(fù)擔(dān),基于SSD緩存,我們用TensorFlow程序通過(guò)JindoFuse來(lái)讀取JindoFS上緩存的OSS數(shù)據(jù)來(lái)做訓(xùn)練,相較該開(kāi)源方案性能快40%。
在數(shù)據(jù)湖架構(gòu)下在計(jì)算側(cè)部署緩存設(shè)備引入緩存,可以實(shí)現(xiàn)計(jì)算加速的好處,計(jì)算效率的提升則意味著更少的彈性計(jì)算資源使用和成本支出,但另一方面毋庸諱言也會(huì)給用戶帶來(lái)額外的緩存成本和負(fù)擔(dān)。如何衡量這個(gè)成本和收益,確定是否引入緩存,需要結(jié)合實(shí)際的計(jì)算場(chǎng)景進(jìn)行測(cè)試評(píng)估,不能一概而論。
高配版:深度定制,自己管理文件元數(shù)據(jù)
我們?cè)贘indoFS上優(yōu)化好OSS適配,把Jindo分布式緩存性能做到效能最大化,能滿足絕大多數(shù)大規(guī)模分析和機(jī)器學(xué)習(xí)訓(xùn)練這些計(jì)算。現(xiàn)有的JindoFS大量部署和使用表明,無(wú)論Hive/Spark/Impala這種數(shù)倉(cāng)作業(yè),Presto交互式分析,還是TensorFlow訓(xùn)練,我們都可以在計(jì)算側(cè)通過(guò)使用阿里云緩存定制機(jī)型,來(lái)達(dá)到多種計(jì)算高效訪問(wèn)OSS數(shù)據(jù)湖的吞吐要求。可是故事并沒(méi)有完,數(shù)據(jù)湖的架構(gòu)決定了計(jì)算上的開(kāi)放性和更加多樣性,上面這些計(jì)算可能是最主要的,但并不是全部,JindoFS在設(shè)計(jì)之初就希望實(shí)現(xiàn)一套部署,即能覆蓋各種主要場(chǎng)景。一個(gè)典型情況是,有不少用戶希望JindoFS能夠完全替代HDFS,而不只是Hive/Spark夠用就可以了,用戶也不希望在數(shù)據(jù)湖架構(gòu)下還要混合使用其他存儲(chǔ)系統(tǒng)。整理一下大概有下面幾種情況需要我們進(jìn)一步考慮。
第一、上面討論對(duì)象存儲(chǔ)適配的時(shí)候我們提到,一些文件/目錄操作的原子性需求在本質(zhì)上是解決不了的,比如文件的rename,目錄的copy,rename和delete。徹底解決這些問(wèn)題,完全滿足文件系統(tǒng)語(yǔ)義,根本上需要自己實(shí)現(xiàn)文件元數(shù)據(jù)管理,像HDFS NameNode那樣。
第二、HDFS有不少比較高級(jí)的特性和接口,比如支持truncate,append,concat,hsync,snapshot和Xattributes。像HBase依賴hsync/snapshot,F(xiàn)link依賴truncate。數(shù)據(jù)湖架構(gòu)的開(kāi)放性也決定了還會(huì)有更多的引擎要對(duì)接上來(lái),對(duì)這些高級(jí)接口有更多需求。
第三、HDFS重度用戶希望能夠平遷上云,或者在存儲(chǔ)方案選擇上進(jìn)行微調(diào),原有基于HDFS的應(yīng)用,運(yùn)維和治理仍然能夠繼續(xù)使用。在功能上提供Xattributes支持,文件權(quán)限支持,Ranger集成支持,甚至是auditlog支持;在性能上希望不低于HDFS,最好比HDFS還好,還不需要對(duì)NameNode調(diào)優(yōu)。為了也能夠享受到數(shù)據(jù)湖架構(gòu)帶來(lái)的各種好處,該如何幫助這類用戶基于OSS進(jìn)行架構(gòu)升級(jí)呢?
第四、為了突破S3這類對(duì)象存儲(chǔ)產(chǎn)品的局限,大數(shù)據(jù)業(yè)界也在針對(duì)數(shù)據(jù)湖深度定制新的數(shù)據(jù)存儲(chǔ)格式,比如Delta,Hudi,和Iceberg。如何兼容支持和有力優(yōu)化這類格式,也需要進(jìn)一步考慮。
基于這些因素,我們進(jìn)一步開(kāi)發(fā)和推出JindoFS block模式,在OSS對(duì)象存儲(chǔ)的基礎(chǔ)上針對(duì)大數(shù)據(jù)計(jì)算進(jìn)行深度定制,仍然提供標(biāo)準(zhǔn)的HCFS接口,因?yàn)槲覀儓?jiān)信,即使同樣走深度定制路線,遵循現(xiàn)有標(biāo)準(zhǔn)與使用習(xí)慣對(duì)用戶和計(jì)算引擎來(lái)說(shuō)更加容易推廣和使用,也更加符合湖加速的定位和使命。JindoFS block模式對(duì)標(biāo)HDFS,不同的是采取云原生的架構(gòu),依托云平臺(tái)我們做了大量簡(jiǎn)化,使得整個(gè)系統(tǒng)具有彈性,輕量和易于運(yùn)維的特點(diǎn)和優(yōu)勢(shì)。
如上圖示,是JindoFS在block模式下的系統(tǒng)架構(gòu),整體上重用了JindoFS緩存系統(tǒng)。在這種模式下,文件數(shù)據(jù)是分塊存放在OSS上,保證可靠和可用;同時(shí)借助于本地集群上的緩存?zhèn)浞荩梢詫?shí)現(xiàn)緩存加速。文件元數(shù)據(jù)異步寫(xiě)入到阿里云OTS數(shù)據(jù)庫(kù)防止本地誤操作,同時(shí)方便JindoFS集群重建恢復(fù);元數(shù)據(jù)在正常讀寫(xiě)時(shí)走本地RocksDB,內(nèi)存做LRU緩存,因此支撐的文件數(shù)在億級(jí);結(jié)合元數(shù)據(jù)服務(wù)的文件/目錄級(jí)別細(xì)粒度鎖實(shí)現(xiàn),JindoFS在大規(guī)模高并發(fā)作業(yè)高峰的時(shí)候表現(xiàn)比HDFS更穩(wěn)定,吞吐也更高。我們用HDFS NNBench做并發(fā)測(cè)試,對(duì)于最關(guān)鍵的open和create操作,JindoFS的IOPS比HDFS高60%。在千萬(wàn)級(jí)超大目錄測(cè)試上,文件listing操作比HDFS快130%;文件統(tǒng)計(jì)du/count操作比HDFS快1X。借助于分布式Raft協(xié)議,JindoFS支持HA和多namespaces,整體上部署和維護(hù)比HDFS簡(jiǎn)化太多。在IO吞吐上,因?yàn)槌吮镜卮疟P,還可以同時(shí)使用OSS帶寬來(lái)讀,因此在同樣的集群配置下用DFSIO實(shí)測(cè)下來(lái),讀吞吐JindoFS比HDFS快33%。
JindoFS在湖加速整體解決方案上進(jìn)一步支持block模式,為我們拓寬數(shù)據(jù)湖使用場(chǎng)景和支持更多的引擎帶來(lái)更大的想象空間。目前我們已經(jīng)支持不少客戶使用HBase,為了受益于這種存/算分離的架構(gòu)同時(shí)借助于本地管理的存儲(chǔ)設(shè)備進(jìn)行緩存加速,我們也在探索將更多的開(kāi)源引擎對(duì)接上來(lái)。比如像Kafka,Kudu甚至OLAP新貴ClickHouse,能不能讓這些引擎專注在它們的場(chǎng)景上,將它們從壞盤處理和如何伸縮這類事情上徹底解放出來(lái)。原本一些堅(jiān)持使用HDFS的客戶也被block模式這種輕運(yùn)維,有彈性,低成本和高性能的優(yōu)勢(shì)吸引,通過(guò)這種方式也轉(zhuǎn)到數(shù)據(jù)湖架構(gòu)上來(lái)。如同對(duì)OSS的適配支持和緩存模式,JindoFS這種新模式仍然提供完全兼容的HCFS和FUSE支持,大量的數(shù)據(jù)湖引擎在使用上并不需要增加額外的負(fù)擔(dān)。
總結(jié)
行文至此,我們做個(gè)回顧和總結(jié)。基于數(shù)據(jù)湖對(duì)大數(shù)據(jù)平臺(tái)進(jìn)行架構(gòu)升級(jí)是業(yè)界顯著趨勢(shì),數(shù)據(jù)湖架構(gòu)包括湖存儲(chǔ)、湖加速和湖分析,在阿里云上我們通過(guò) JindoFS 針對(duì)各種場(chǎng)景提供多種數(shù)據(jù)湖加速解決方案。阿里云推出的專門支持?jǐn)?shù)據(jù)湖管理的Data Lake Formation,可全面支持?jǐn)?shù)據(jù)湖。
責(zé)任編輯:pj
-
帶寬
+關(guān)注
關(guān)注
3文章
991瀏覽量
41775 -
阿里云
+關(guān)注
關(guān)注
3文章
1002瀏覽量
43860 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8949瀏覽量
139449
發(fā)布評(píng)論請(qǐng)先 登錄
阿里云是什么?企業(yè)不可不知的云端架構(gòu)服務(wù)!
阿里云代理優(yōu)惠上云指南——火傘云如何助力企業(yè)降本增效
先進(jìn)數(shù)通:阿里云多項(xiàng)合作與云上貴州供應(yīng)商身份確認(rèn)
華為云 Flexus X 加速 Redis 案例實(shí)踐與詳解
阿里云官網(wǎng)電腦版,阿里云電腦版的下載使用教程

2025阿里云代理政策:火傘云帶來(lái)專屬優(yōu)惠
華為云 FlexusX 實(shí)例下的 Kafka 集群部署實(shí)踐與性能優(yōu)化
阿里云代理有哪些?
Share Boom第12期:云終端2.0時(shí)代-無(wú)影隨行,且玩好贏沙龍圓滿落幕
云計(jì)算與邊緣計(jì)算的結(jié)合
云計(jì)算平臺(tái)的最佳實(shí)踐
阿里云設(shè)備的物模型數(shù)據(jù)里面始終沒(méi)有值是為什么?
阿里云關(guān)閉澳大利亞和印度數(shù)據(jù)中心
ESP32S3連接阿里云物聯(lián)網(wǎng)平臺(tái)LinkSDK報(bào)錯(cuò)怎么解決?
LPS完成戰(zhàn)略性收購(gòu) 增強(qiáng)數(shù)據(jù)實(shí)踐和營(yíng)銷云能力






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論