") 從不同方面圍繞立場檢測領域進行研究
從不同方面圍繞立場檢測領域進行研究
引言
從自然語言文本中自動提取語義信息是許多實際應用領域中的重要研究問題。尤其是在最近通過社交媒體網(wǎng)站,新聞門戶網(wǎng)站和論壇等渠道在線發(fā)布內(nèi)容之后;大量相關的科學出版物揭示了諸如情感分析,嘲諷/爭議/真實性/謠言/假新聞檢測以及論據(jù)挖掘等問題的解決方案的影響和意義越來越大。

立場檢測作為情感分類任務中的一個子任務,在上述領域中都起著舉足輕重的作用,并且在不同的場景設置中任務的定義方式也不同,其中最常見的定義是將文本生產(chǎn)者的立場朝著目標自動分類為以下三個類別之一:{支持,反對,中立}。
本次DISC小編分享的三篇ACL2020論文將從不同方面圍繞立場檢測領域進行研究,包括新任務、新數(shù)據(jù)集、以及加入外部知識的新模型等。
文章概覽
網(wǎng)絡論辯中的一致性預測——立場極性與強度檢測(Agreement Prediction of Arguments in Cyber Argumentation for Detecting Stance Polarity and Intensity)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.509.pdf
在在線辯論中,用戶對彼此的論點和想法表達不同程度的同意/反對。通常,同意/反對的語義隱含在文本中,必須經(jīng)過預測才能分析集體意見。現(xiàn)有的立場檢測方法可以預測帖子對主題或帖子的立場的極性,但不考慮該立場的強度。我們在判斷兩段對話的關系中引入了一個新的研究問題,即立場極性和強度預測。這個問題具有挑戰(zhàn)性,因為立場強度上的差異通常很細微,需要細致的語言理解。在網(wǎng)絡辯論數(shù)據(jù)中心的研究表明,將立場極性和強度數(shù)據(jù)都納入在線辯論中可以帶來更好的討論分析。
走出“回聲室”:檢測反對辯論發(fā)言(Out of the Echo Chamber: Detecting Countering Debate Speeches)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.633.pdf
隨著從傳統(tǒng)新聞媒體向社交媒體和類似場所的轉(zhuǎn)變,讀者更傾向于被困在“回音室”中,并且可能成為假新聞和虛假信息的犧牲品,缺乏容易獲得不同意見的渠道。因此,作者提出了檢測反對立場發(fā)言的任務,具體來說,是給定一段辯論文本(長文本),從當前的大語料庫中找到與其意見相反的辯論文本(長文本)。操作層面上,作者在文中遵循論辯領域的規(guī)范標準構建了3685篇辯論長文本作為該任務的數(shù)據(jù)集,并進行了人工以及機器模型的實驗,結(jié)果顯示該任務設置合理且極具挑戰(zhàn)性。
使用可遷移的語義-情感知識增強跨領域立場檢測(Enhancing Cross-target Stance Detection with Transferable Semantic-Emotion Knowledge)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.291.pdf
當有足夠的帶標簽的訓練數(shù)據(jù)可用時,立場檢測任務中人們已經(jīng)取得了巨大的成功。但是,注釋足夠的數(shù)據(jù)會占用大量人力,這為將立場分類器推廣到具有新目標的數(shù)據(jù)建立了很大的障礙。在本文中,作者提出了一種用于跨目標立場檢測的語義-情感知識轉(zhuǎn)移(SEKT)模型,該模型使用外部知識(語義和情感詞典)作為橋梁來實現(xiàn)跨不同目標的知識轉(zhuǎn)移。在大型現(xiàn)實數(shù)據(jù)集上進行的大量實驗結(jié)果證明,SEKT模型相對于最新的基線方法具有優(yōu)越性。
數(shù)據(jù)概覽
對于立場檢測任務,不同的應用場景中的任務設置會存在一定的差異,例如在最傳統(tǒng)的設置中,立場檢測被定義為給定兩段文本,我們需要判斷出兩段文本之間的支持/反對關系;在另一些場景中可能定義為給定文本和某一主題,判斷它們之間的語義關系等等,上述提到的三篇論文所使用到的數(shù)據(jù)集分別如下所示:
ICAS: 上述第一篇文章中所構建的新數(shù)據(jù)集。數(shù)據(jù)來源自作者所搭建的智能網(wǎng)絡論辯系統(tǒng)(intelligent cyber argumentation system, ICAS)中2017年秋季至2019年春季所積累的數(shù)據(jù),數(shù)據(jù)結(jié)構包含用戶回復時輸入文本以及他們對于自己所產(chǎn)生的回復的立場極性/強度的打分。
IBM Debater - Recorded Debating Dataset - Release #5: 第二篇論文中所構建的新數(shù)據(jù)集,作者采用(Mirkin et. al., 2018)所提出的辯論文本生成規(guī)范,通過聘請專業(yè)辯論人員進行給定主題、立場的口頭陳述,再通過語音轉(zhuǎn)文本技術生成對應的辯論文本,最終得到了3684條辯論長文本。
SemEval-2016 Task 6: 第三篇論文中所使用的數(shù)據(jù)集,來自于SemEval2016年的第六個任務,共包含在4個話題上的4870條推特文本,每條推特文本都包含在一個話題上的立場標簽。
論文
1

動機
強度是立場關系的重要方面,這一維度的信息可以幫助我們對于用戶之間的回復進行更為深入的分析;
先前的立場檢測方法大多僅判斷立場的極性(同意/不同意/中立),但極少數(shù)考慮立場的強度(強,弱等)。
在研究立場強度的前人工作中,對于立場強度判別建模為更細粒度的分類問題(如:強烈同意/同意/中立/反對/強烈反對)并進行更為詳細的標注,但發(fā)現(xiàn)這樣的分類數(shù)據(jù)在使得模型在原來的三分類問題的任務中出現(xiàn)了明顯的性能下降。
創(chuàng)新點
從上述動機出發(fā),作者提出了給論點編碼的新方式:一致值編碼。
一致值編碼(取值范圍為[-1.0,+1.0])由兩個因子構成:
符號(+/-/0),分別對應立場極性(支持/反對/中立)
振幅(取值范圍[0,1.0]),對應上文中所提到的立場強度(0代表無強度/中立;1.0代表完全支持/完全反對)
立場的一致值=符號*振幅
數(shù)據(jù)集
作者搭建了智能網(wǎng)絡論辯系統(tǒng)(intelligent cyber argumentation system, ICAS),并邀請研究生在該平臺上進行論辯互動,并為自己的回復進行一致值的標注(一致值的標注以0.2為最小間隔),如下圖所示:
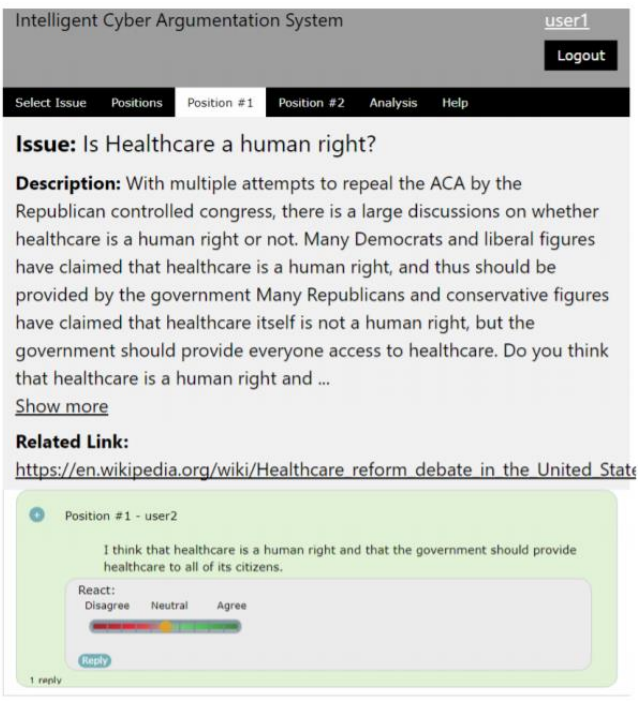
作者收集了從2017年秋季至2019年春季所記錄的所有文本、一致值標注的數(shù)據(jù),共計從904位用戶中得到了22606條論點數(shù)據(jù)。
模型
作者應用了SemEval 2016 Twitter 立場檢測任務中表現(xiàn)最好的五個模型,進行了相應改動(注:由于原本的立場檢測任務為分類任務,而上文提到的強度判別為回歸任務,故在本任務中需要將這些模型最后的分類層進行改為輸出[-1.0,+1.0]的實值)應用到了上文所描述的新數(shù)據(jù)集中,模型分別如下所示:
Ridge-M以及Ridge-S
這兩個回歸模型基于1-3gram的詞特征、2-5gram的字符特征等文本特征表示(Ridge-S模型還加入了詞嵌入特征),并將其輸入SVM模型從而得到在立場上的分類標簽(在此任務中SVM被替換成了Ridge回歸模型)。
該模型利用語言特征、主題特征、詞嵌入特征以及一些詞法特征(共2855維),并將其輸入至一個SVM分類器、一個隨機森林分類器、一個樸素貝葉斯模型進行多數(shù)投票從而得到最后的分類結(jié)果(在此任務中三個模型被替換為SVR、隨機森林回歸器以及Ridge回歸模型)。
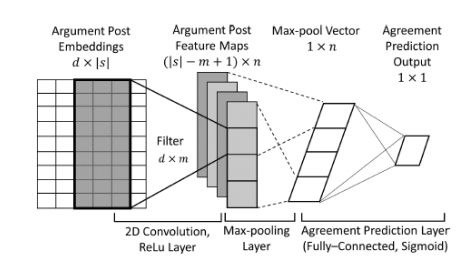
pkudblab-PIP
該模型如下圖所示,是一個卷積神經(jīng)網(wǎng)絡模型,通過將輸入句子的詞向量依次送入2D卷積層、最大池化層、全連接稠密層從而得到最終的標簽分類(該任務中輸出層替換為sigmoid層,從而輸出實值一致值)。
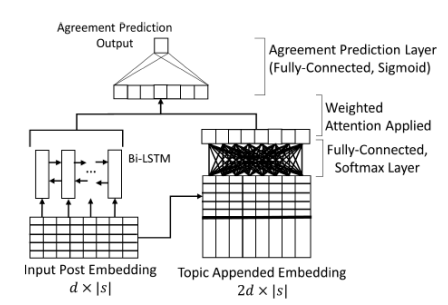
T-PAN-PIP
該模型如下圖所示,是一個基于遞歸神經(jīng)網(wǎng)絡的模型。該模型通過將輸入句子的詞向量依次送入BiLSTM以及注意力層,從而得到最終的標簽分類(該任務中輸出替換為sigmoid層,從而輸出實值一致值)。
實驗
該論文的實驗主要從兩方面進行:
上述五個在立場極性檢測中表現(xiàn)最好的模型在新任務新數(shù)據(jù)集上的表現(xiàn):
如圖所示,五個模型在新數(shù)據(jù)集上的RMSE(均方誤差根)分布在0.596~0.718之間,作者稱這個表現(xiàn)與原任務上的效果接近。其中SVR-RF-R整合模型的RMSE指標最低,取得了最好的效果。

所提出的新任務是否提升了模型在原任務上的表現(xiàn):
注意到當前新任務的標簽以及預測都是一個取值范圍為[-1.0,+1.0]的實數(shù)值,為了與傳統(tǒng)的立場極性檢測作比較,作者將新任務的一致值標簽以及預測都取其符號,于是新任務又被轉(zhuǎn)化成了分類問題。最終,作者將僅預測極性任務的模型性能與上述預測一致值的模型在極性標簽上的性能做對比(如下圖所示),發(fā)現(xiàn)了大多數(shù)模型(4個)在經(jīng)過了一致值預測任務的訓練后,在立場極性的判斷上都比原分類任務的模型表現(xiàn)更好,從而得出了新任務單就立場極性的判斷上也能提升模型的性能,是一個合理的任務。

2

動機
缺乏對特定觀點提出異議的相反觀點的了解,可能導致我們的決策最終基于片面或者存在偏見的信息。
具體操作上,該任務定義為:給定輸入文本和語料庫,請從該語料庫中檢索一個包含與輸入文本中提出的論點相駁斥的反文本。
數(shù)據(jù)集
數(shù)據(jù)集構建
本篇文章作者采用(Mirkin et. al., 2018)所提出的辯論文本生成規(guī)范,通過聘請專業(yè)辯論人員進行給定主題、立場的口頭陳述,再通過語音轉(zhuǎn)文本技術生成對應的辯論文本,具體的數(shù)據(jù)集生成過程如下:
錄制支持論題的演講
專業(yè)辯手給定一系列論題(motion)以及相關的背景資料(從Wikipedia等在線資源網(wǎng)站上獲得)
每位辯手每次被給予十分鐘的準備時間
準備時間結(jié)束后每位辯手每次錄制一段長度為四分鐘的的辯論演講(用于支持給定論題)
將上述得到的演講錄音通過語音轉(zhuǎn)文字技術轉(zhuǎn)換為文本
錄制反對論題的演講
專業(yè)辯手給定一系列論題(motion)、一篇由上述過程生成的支持論題的演講稿以及相關的背景資料(從Wikipedia等在線資源網(wǎng)站上獲得)
每位辯手每次被給予十分鐘的準備時間
準備時間結(jié)束后每位辯手每次錄制一段長度為四分鐘的的辯論演講(用于反對給定的支持演講稿)
將上述得到的演講錄音通過語音轉(zhuǎn)文字技術轉(zhuǎn)換為文本
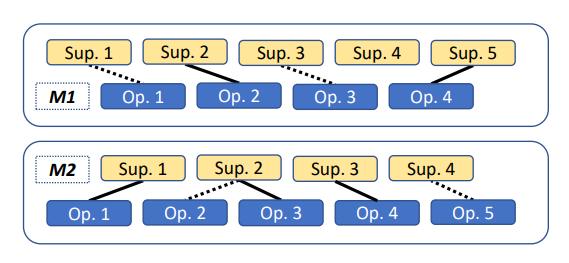
上述過程中所涉及的論題、論點之間的關系如下圖所示(其中、為兩個不同的論題,表示支持論題的演講,表示反對這些支持演講的演講,實線和虛線分別表示顯式反對與隱式反對):
數(shù)據(jù)集分析
共包含460個不同論題
總共錄制了1797段支持論題的演講
總共錄制了1887段反對這些支持演講的演講
348篇為顯式反駁
1389篇為隱式反駁
150篇為直接反對給定議題的演講,并不駁斥任何一篇支持議題的演講
實驗
人工表現(xiàn)
在收集到上述數(shù)據(jù)集之后,作者先進行了人工表現(xiàn)的實驗。作者共組織了兩場實驗,第一場參與者為進行過多次數(shù)據(jù)標注任務的標注專家,第二場參與者為隨機招募的實驗者。
對于每一段支持論題的演講,組織方都會給出3~5段反對演講,其中有一段是正確的駁斥所給定的支持言論,剩余則為同一論題下與支持言論不構成駁斥關系的錯誤選項,受試者需要從給定的候選文本給出自己認為的正確答案,當無法確定時,需要他們隨機猜一個答案并說明情況。人工實驗的結(jié)果如下表所示(A表示人工試驗的準確率,R表示隨機猜的準確率;Ex表示標注專家的結(jié)果,Cr表示隨機招募的受試者的結(jié)果):

由上表我們可以得出如下幾個結(jié)論:
人工表現(xiàn)遠超隨機猜測的準確率,說明這個任務是可行的;
標注專家結(jié)果比受試者有明顯提升;
隱式駁斥的文本相比顯示駁斥文本更難選擇正確。
模型表現(xiàn)
在進行完人工實驗之后,作者采用了較多的語言模型來進行自動化實驗,實驗結(jié)果如下表所示:
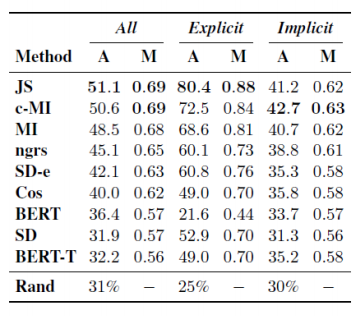
其中值得一提的是BERT的表現(xiàn)差強人意,在眾多基于特征的方法中處于下游,甚至與隨機猜的準確率相近,這是因為根據(jù)之前的方式所生成的數(shù)據(jù)集長度遠超BERT的最大長度512,因此作者不得不對原文以及候選項都進行截斷,但仍然未能得到使人滿意的結(jié)果,這也從另一方面體現(xiàn)出當前對于長文本的處理方法仍存在較大的局限性。
3

動機&貢獻
當前階段盡管立場檢測任務已經(jīng)有了長足發(fā)展,但跨領域的的目標立場檢測(指訓練集和數(shù)據(jù)集在領域上存在差異)進展較小。
本文從語義相關和情感相關的詞匯表中構建語義情感知識圖(SE圖),并通過應用圖卷積網(wǎng)絡(GCN)對上述的情感知識圖進行表示學習,并將傳統(tǒng)的BiLSTM進行了改進,使其可以更好地使用上述SE圖所帶來的外部知識。
實驗結(jié)果顯示,通過上述方式的處理,模型在跨領域的目標立場檢測任務上取得了SOTA的表現(xiàn)。
數(shù)據(jù)集
本篇文章所采用的數(shù)據(jù)集來自于SemEval2016年的第六個任務,共包含在4個話題,包括Donald Trump (DT), Hillary Clinton (HC), Legalization of Abortion (LA), 和Feminist Movement (FM)上的4870條推特文本,每條推特文本都包含在一個話題上的立場標簽。作者還向其中加入了一個新的話題,Trade Policy (TP),其包含了1245條推特文本。之后作者將這五個話題按照其語義分為了兩組:婦女權利(FM, LA)以及美國政治(DT,HC,TP)。由此,作者構造出了八組跨領域的目標立場檢測任務 ( DT→HC, HC→DT, FM→LA, LA→FM, TP→HC, HC→TP, TP→DT, DT→TP)。(左箭頭表示從源領域到目標領域)
模型
作者所提出的模型SEKT整體架構如下圖所示,其主要由兩部分構成:SE圖以及知識增強的BiLSTM:

語義-情感知識圖(SE圖)構建
將SenticNet中的同義/近義詞兩兩之間連邊
將EmoLex中每個詞及其對應的可能的情感兩兩連邊
上述過程如下圖所示,注意這里我們構建的是包含詞和情感標簽的異質(zhì)網(wǎng)絡圖:
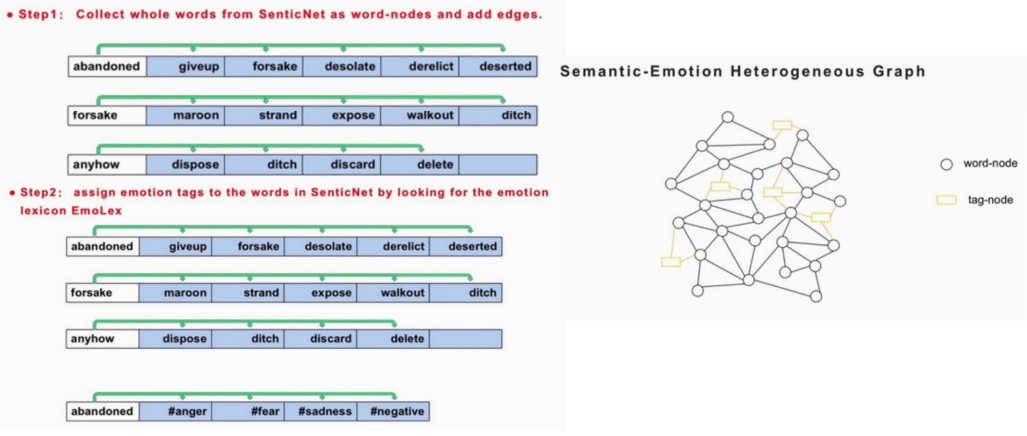
語義-情感知識圖表示
對于每個節(jié)點,我們從全知識圖中抽出一個的子圖(文中k取1)
接下來把傳到一個兩層GCN中
最后我們將傳入一個全連接層來得到圖的最終表示
知識增強的BiLSTM
該模塊結(jié)構如下圖所示:

上圖中左邊藍色部分為普通BiLSTM的結(jié)構組件,按如下公式更新狀態(tài):
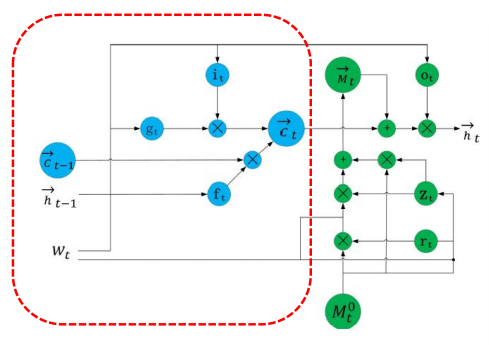
該模塊中右半部分為知識知曉的記憶模塊,按如下方式更新狀態(tài):
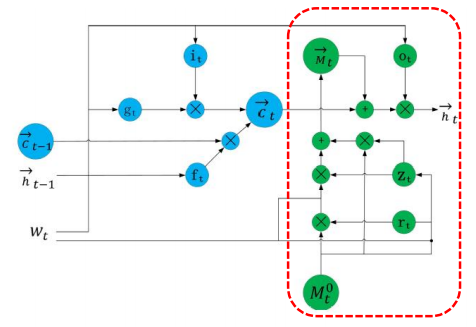
對于每一個詞,我們從SE圖中抽取出其對應的實體,并且獲得以其為中心的子圖表示。
最終,將所得到的目標表示以及句子表示再通過一個注意力層,便可得到句子在目標上的立場分類預測結(jié)果。
實驗
與基線模型相比
作者所提出的完整模型在SemEval 2016 任務6數(shù)據(jù)集上的表現(xiàn)如下圖所示:
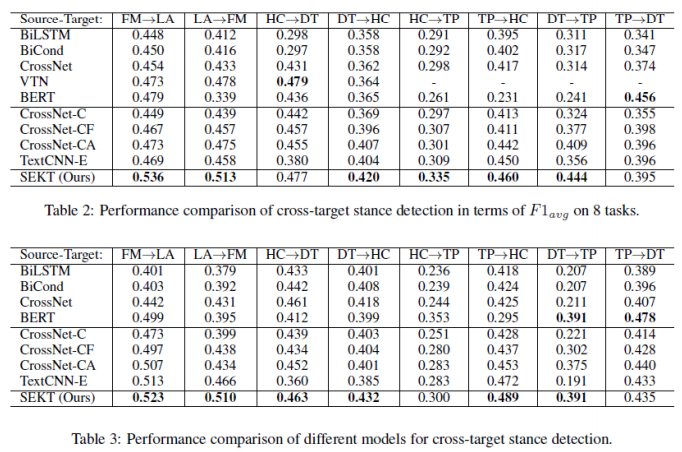
可以看出作者的SEKT模型在8個跨領域的目標立場檢測任務中的表現(xiàn)都超過了大多數(shù)基線模型,達到了SOTA的效果,說明作者這種通過加入語義詞典與情感詞典的外部知識模型,完成了領域遷移中對于關鍵詞的表示以及關系建模。
消融實驗
在驗證了完整模型的SOTA性能后,作者進一步進行了消融實驗,在上述8個任務中去掉SE圖建模以及將拓展的BiLSTM替換為傳統(tǒng)LSTM,分別進行性能對照,結(jié)果如下圖所示:

可以看出在大多數(shù)跨領域的目標立場檢測中,去掉SE圖表示或去掉對于BiLSTM的改進,都會使得模型性能下降0.02左右的指標,從而證明了這兩部分的重要性。(注:作者此處的消融實驗不僅僅是去掉了SE兩個詞典中的信息以及圖表示學習的信息,而是保留這些信息,但在模型層面去掉上述較為復雜的操作,因此在不影響輸入的信息量的情況下,但就模型設計方面證明了所提模型的優(yōu)越性)。
-
檢測
+關注
關注
5文章
4602瀏覽量
92527 -
數(shù)據(jù)集
+關注
關注
4文章
1222瀏覽量
25275 -
自然語言
+關注
關注
1文章
291瀏覽量
13603
原文標題:【論文分享】ACL 2020 立場檢測相關研究
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
高光譜成像相機:基于高光譜成像技術的玉米種子純度檢測研究
電機檢測快速安裝試驗臺軌跡研究
電源盒的日常應用有哪方面
安泰功率放大器在超聲領域研究中的應用

VirtualLab Fusion應用:光波導系統(tǒng)的性能研究
高校開展RK3588課題研究 只能人工標注練算法?

環(huán)境檢測艙:技術優(yōu)勢引領檢測檢驗領域革新
如何進行IP檢測

電壓放大器在鋼筋剝離損傷識別試驗中的應用
高壓放大器在壓電智能傳感技術的鋼結(jié)構監(jiān)測研究中的應用
目標檢測識別主要應用于哪些方面
新型材料在生物檢測方面的應用和前景






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論