 Python爬蟲入門知識:解析數據篇
Python爬蟲入門知識:解析數據篇
首先,讓我們回顧一下入門Python爬蟲的四個步驟吧:
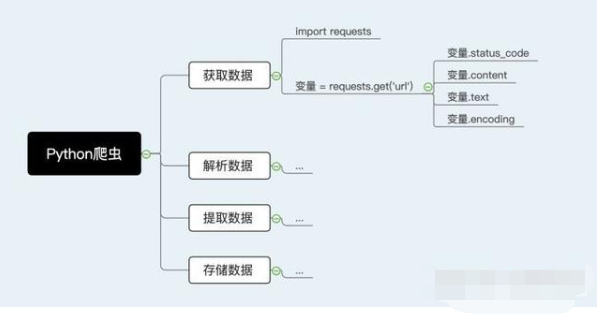
而解析數據,其用途就是在爬蟲過程中將服務器返回的HTML源代碼轉換為我們能讀懂的格式。那么,接下來就正式進入到解析數據篇的內容啦。
Part 1:了解HTML
HTML(Hyper Text Markup Language)為超文本標記語言。簡單來講,就是一種用于構建網頁的編程語言。其主要組成部分為網頁頭(《head》元素)與網頁體(《body》元素)。一般情況下,網頁頭部分會定義HTML文檔的編碼以及網頁的標題。而網頁體部分則決定著一個網頁中的正文內容。

在一個HTML文檔內,我們可以看到許多被《》括住的內容,它們被稱作一個標簽。標簽通常是成對出現的。比如網頁頭部分的代碼中含有《head》以及《/head》,網頁體部分的代碼中含有《body》以及《/body》。
在了解過HTML的基本信息之后,下一步我們就可以去解析這些數據了。
Part 2:下載BeautifulSoup庫
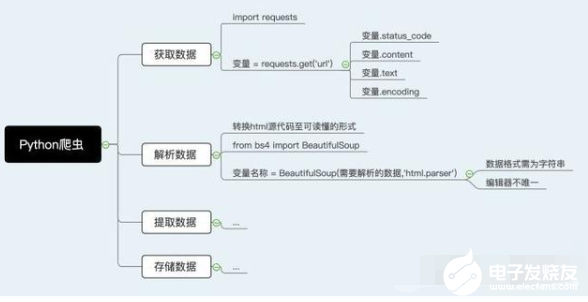
在解析與提取數據的過程中,我們會用到一個強大的工具,即BeautifulSoup庫。由于BeautifulSoup不屬于Python標準庫,因此需要單獨進行下載。Mac用戶需打開終端,輸入代碼pip install BeautifulSoup4。Windows用戶需運行CMD,輸入代碼pip install BeautifulSoup4。下載完成后,在編輯器內輸入以下代碼即可實現BeautifulSoup庫的調用。

Part 3:運用BeautifulSoup解析數據
具體用法:變量名稱 = BeautifulSoup(需要解析的數據,‘html.parser’)
備注:1. BeautifulSoup()內的第一個參數,即需要解析的數據,類型必須為字符串,否則運行時系統會報錯。2. ‘html.parser’為Python內置庫中的一個解析器。它的運行速度較快,使用方法也比較簡單。但是它并不是唯一的解析器,大家可以使用其它的解析器進行操作,但是具體用法可能會略有不同。

總結:
-
數據
+關注
關注
8文章
7233瀏覽量
90866 -
網絡爬蟲
+關注
關注
1文章
52瀏覽量
8863 -
python
+關注
關注
56文章
4822瀏覽量
85996
發布評論請先 登錄
【「零基礎開發AI Agent」閱讀體驗】總體預覽及入門篇
python入門圣經-高清電子書(建議下載)
?如何在虛擬環境中使用 Python,提升你的開發體驗~

零基礎入門:如何在樹莓派上編寫和運行Python程序?





 工商網監
工商網監
評論