 詳談分布式系統的定義及屬性
詳談分布式系統的定義及屬性
分布式系統經常讓人覺得云山霧罩,主要是因為相關知識點比較零散不成體系。但別擔心,我很清楚這個有點尷尬的情況。我自學分布式計算的時候,就有很多次完全摸不著頭腦。現在,經歷過很多次嘗試和死磕之后,我終于有信心可以跟大家分享一下有關分布式系統的基礎知識了。
我還想討論一下區塊鏈技術給分布式相關的學術界和工業界已然帶來的深遠影響。區塊鏈促使工程師和科學家們重新審視和反思那些在分布式計算領域已經根深蒂固的范式。也許在對這個領域的研究發展推動作用上,沒有什么比區塊鏈技術更強有力的了。
分布式系統肯定不能算新技術了。科學家和工程師們過去數十年中一直在研究這個課題。那么區塊鏈跟分布式系統有什么關系呢?簡單地說,如果沒有分布式系統,也就不可能有區塊鏈帶來的技術貢獻。
本質上,一條區塊鏈就是一種新型的分布式系統。區塊鏈自起源于比特幣以來就一直對分布式計算領域持續產生影響。所以想真正搞明白區塊鏈的運行原理,深入理解分布式系統的原理就至關重要。
但不幸的是,大部分關于分布式計算的文獻資料,要么太晦澀艱深,要么散布在不計其數的學術論文中。更麻煩的是,分布式系統為了滿足不同的需求,可能有多達上百種不同的架構。要把這些都歸納成一個統一且易于理解的框架的確很困難。
因為這個領域涉及知識點太廣,我必須很專注在我力所能及可以講明白的部分。而且我需要一些概括性的描述以便對系統復雜性進行簡化。請注意,我不會幫你成為這個領域的專家。但我會幫你快速入門分布式系統及其共識機制。
讀完這篇長文之后,你應該會對以下內容有更深刻的認識:
什么是分布式系統,
分布式系統的特性,
分布式系統中的共識意味著什么,
基礎共識算法(比如 DLS 和 PBFT)以及
為什么中本聰共識非常重要。
嗯,不作過多解釋了,快上車。
什么是分布式系統?
一個分布式系統包括一組相互獨立的進程(比如計算機),它們互相傳遞消息并進行協作以完成一個共同的任務(比如解決一個計算問題)。
簡單的說,一個分布式系統就是一組計算機,它們互相協作以完成一個共同的任務。雖然組成分布式系統的進程是相互獨立的,但整個系統對于終端用戶而言可以看成只是一臺計算機。
像我之前提到的,分布式系統可以有上百種架構。比如,一臺普通的計算機也可以看成是一個分布式系統:中央處理器,內存,輸入輸出都是獨立的進程,互相協作以完成共同的任務。
又比如飛機,下圖中的不同組件協同工作,載你從A點飛到B點:
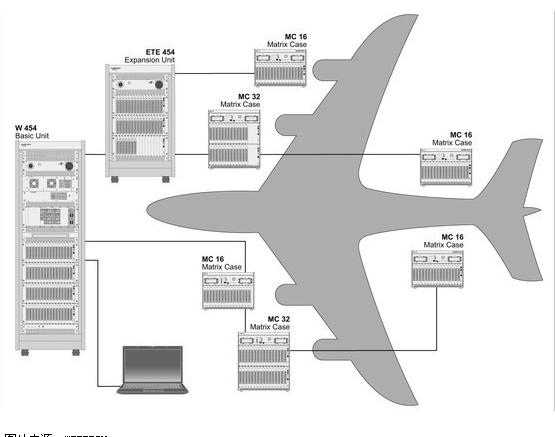
-圖片來源:WEETECH -
在這篇文章中,我們將重點看看那些由空間上隔離的計算機組成的分布式系統。
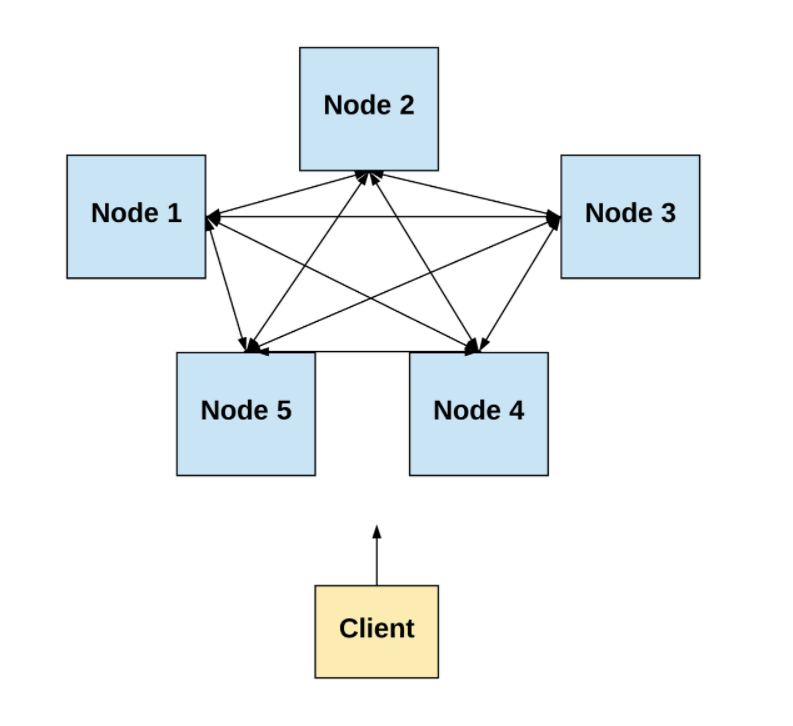
-作者制圖-
請注意:我可能會使用若干術語表達與“”進程”相同的含義:“節點”(node、peer),“計算機”(computer),“組件”(component)。在這篇文章里它們都是同義詞。類似地,“網絡”(network)和“系統”(system)在本文中也是同義詞。
分布式系統的特性
每個分布式系統都有一組特性,如下:
A) 并發性
進程在系統中是并發運行的,即同一時刻有多個事件發生。換句話說,任一時刻,系統中每個節點的事件執行都是相互獨立的。
這就需要協作。
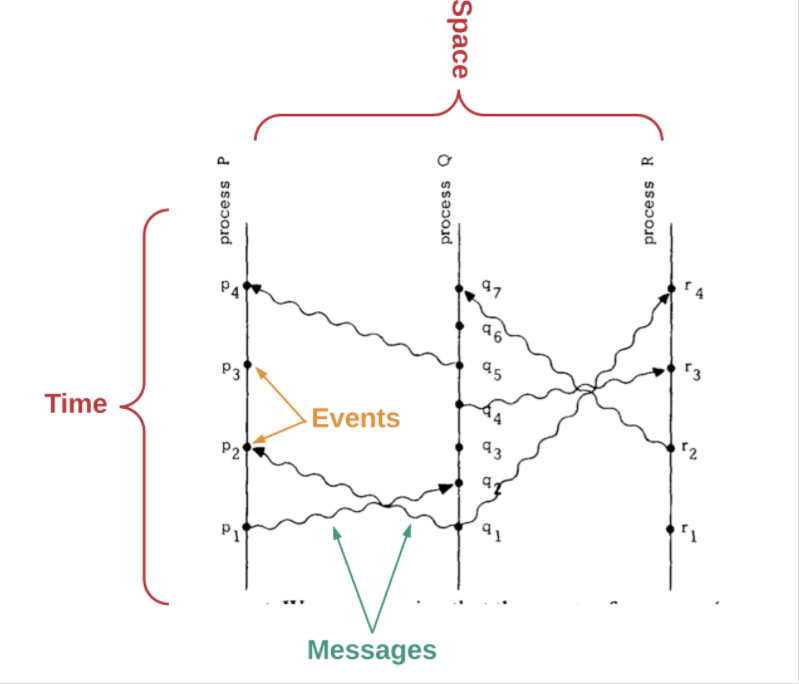
-分布式系統中的時間,時鐘和事件排序,來自 Lamport, L (1978)-
B) 全局時鐘的缺失
分布式系統要能運轉,我們就需要一個確定事件排序的方法。但是,由于分布式系統中的計算機是空間上隔離且并發運行的,有時候很難說清楚兩個事件中哪個先發生。換句話說,對于系統中所有計算機而言,沒有一個統一的全局時鐘來決定事件發生的順序。
Leslie Lamport 在他的論文《分布式系統中的時間,時鐘和事件排序》里,展示了如何通過以下事實來決定事件的先后順序:
消息總是先發送,而后被接收。
每臺計算機都有事件的排序。
通過確定事件之間的相對順序(哪個先發生,哪個后發生),我們就可以得到關于系統中事件的一個局部排序(partial ordering)。Lamport 的論文描述了一種算法,要求每臺計算機都監聽其它計算機。這樣,所有事件就可以根據這個局部排序得到全局排序。
但是,如果完全基于每個獨立計算機監聽到的事件進行排序,有可能會碰到這種情況:得出的排序與外部用戶的觀察不一致。所以,論文提到該算法仍然無法完全排除異常情況。最后,Lamport 討論了如何通過適當地同步物理時鐘避免上述異常。
但是,等一下——這里有個很重要的前提:協調獨立的時鐘并使之同步是一個非常復雜的計算機科學問題。即使你一開始把一堆時鐘調成同步的狀態,一段時間后它們的計時也會開始產生偏差。這被稱作“時鐘偏移”,是一種時鐘計時頻率發生細微差別的現象。
實質上,Lamport 的論文證明了:在由空間上隔離的一組計算機組成的分布式系統中,時間和事件排序是導致系統可能出錯的障礙根源。
C) 單點可能出錯
理解分布式系統的一個關鍵點在于認識到,分布式系統中的組件是會出錯的。這也是分布式系統被稱作“容錯分布式計算”的原因。不出錯的系統是不可能存在的。現實當中的系統總是暴露在許多可能的錯誤和故障風險之下,這些故障包括程序崩潰;消息丟失、實真、重放;網絡隔離導致的消息延遲或丟幀;甚至是進程完全失控、惡意發送消息。
錯誤可以被大致分為三類:
崩潰錯誤:組件沒有預警就停止工作(比如計算機崩潰了)。
遺漏錯誤:組件發了一個消息但沒有被別的節點收到(比如這條消息丟包了)。
拜占庭錯誤:組件不按既定規則工作。這種類型的錯誤在可控環境中不會發生(比如谷歌和亞馬遜的數據中心),因為一般認為那種環境中系統里不會發生惡意行為。與之相反,拜占庭錯誤會發生在所謂的“敵對環境”中。簡單來說,當一組去中心化的獨立參與者作為節點加入某個分布式網絡后,這些參與者可以完全不按既定規則行動,也就是說它們可以惡意地更改消息、攔截消息或者根本不發送任何消息。
了解上述概念后,那分布式系統的目標就可以定義為:為一個存在可能出錯組件的系統設計協議,期望該系統仍然能完成組件的共同任務并對用戶提供可用的服務。
考慮到所有的系統都可能會出錯,那我們建立一個分布式系統的核心考量就是,它是否可以在部分組件發生異常(無論是因為非惡意的行為比如崩潰-出錯或者遺漏錯誤,還是因為惡意行為比如拜占庭錯誤)的情況下繼續工作。
粗略地說,建立分布式系統有兩種可考慮的模式:
1) 簡單容錯
在一個簡單容錯系統中,我們假設系統中所有組件都會處于以下兩種狀態中的一個:要么嚴格遵循協議工作,要么不遵循。這種類型的系統可以處理節點下線或者宕機的情況。但是它沒法處理不按既定規則工作或者惡意工作的節點。
2A) 拜占庭容錯
簡單容錯系統在非可控環境中用處不大。在一個節點由獨立參與者控制,且通過無需權限的開放互聯網進行通信的去中心化網絡里,我們需要考慮到,網絡中可能出現惡意節點(或者說“拜占庭式”節點)。因此,在拜占庭容錯系統中,我們假設節點可能會宕機或者作惡。
2B) BAR容錯
盡管大多數現實系統都被設計成可以容忍拜占庭錯誤,有些專家認為,這些設計太過寬泛,并沒有考慮到所謂的“利己性”出錯,即節點可能因為出于合理的自身利益而采取惡意行為。換句話說,根據不同的激勵,節點可能誠實,也可能不誠實。所以如果激勵足夠多,甚至可能大部分節點都會不誠實。
更正式的定義一下,這就是 BAR 模式-同時考慮了拜占庭出錯和利己性出錯的情況。BAR 模式假設系統中有下列三種參與者:
拜占庭:這種節點是惡意的并且就是試圖讓你玩完。
利他:始終遵循系統協議的誠實節點。
利己:這類節點只在遵循協議有利于自身時才會遵循。
D) 消息傳遞
如我前述,分布式系統總的計算機通過互相之間的“消息傳遞”來溝通和協作。消息可以通過任何一種消息協議傳遞,比如 HTTP 或者 RPC,亦或是為特定系統實現的一套定制協議。有兩種消息傳遞的環境:
1) 同步
在同步系統中,我們假定消息會在一個固定且已知的時間范圍內接收到。
同步消息傳遞在概念上更簡單,因為用戶會有一個時間上的保證:當他們發送某條消息后,接收方會在一定時間內收到它。這就使得用戶可以為他們的協議設置一個消息傳遞的耗時上限。
但是,這種假設在現實生活當中的分布式系統中不切實際:因為組件計算機們可能會崩潰,或者下線,而且消息也可能丟包,重復,延時或者沒有按照發送順序被接收。
2) 異步
在異步消息傳遞系統中,我們假定系統可能導致某條消息一直被延誤,導致消息重放,或者亂序發送消息。換句話說,在這種環境下,消息傳遞的預期耗時是沒有上限的。
-
分布式
+關注
關注
1文章
977瀏覽量
75155 -
分布式系統
+關注
關注
0文章
147瀏覽量
19525 -
區塊鏈
+關注
關注
112文章
15565瀏覽量
107883
發布評論請先 登錄






 工商網監
工商網監
評論