 打通IO棧:一次編譯服務器性能優化實戰
打通IO棧:一次編譯服務器性能優化實戰
背景
隨著企業SDK在多條產品線的廣泛使用,隨著SDK開發人員的增長,每日往SDK提交的補丁量與日俱增,自動化提交代碼檢查的壓力已經明顯超過了通用服務器的負載。于是向公司申請了一臺專用服務器,用于SDK構建檢查。
$ cat /proc/cpuinfo | grep ^proccessor | wc -l48$ free -h total used free shared buffers cachedMem: 47G 45G 1.6G 20M 7.7G 25G-/+ buffers/cache: 12G 35GSwap: 0B 0B 0B$ df文件系統 容量 已用 可用 已用% 掛載點....../dev/sda1 98G 14G 81G 15% //dev/vda1 2.9T 1.8T 986G 65% /home
這是KVM虛擬的服務器,提供了CPU 48線程,實際可用47G內存,磁盤空間約達到3TB。
由于獨享服務器所有資源,設置了十來個worker并行編譯,從提交補丁到發送編譯結果的速度杠杠的。但是在補丁提交非常多的時候,速度瞬間就慢了下去,一次提交觸發的編譯甚至要1個多小時。通過top看到CPU負載并不高,難道是IO瓶頸?找IT要到了root權限,干起來!
由于認知的局限性,如有考慮不周的地方,希望一起交流學習
整體認識IO棧
如果有完整的IO棧的認識,無疑有助于更細膩的優化IO。循著IO棧從上往下的順序,我們逐層分析可優化的地方。
在網上有Linux完整的IO棧結構圖,但太過完整反而不容易理解。按我的認識,簡化過后的IO棧應該是下圖的模樣。
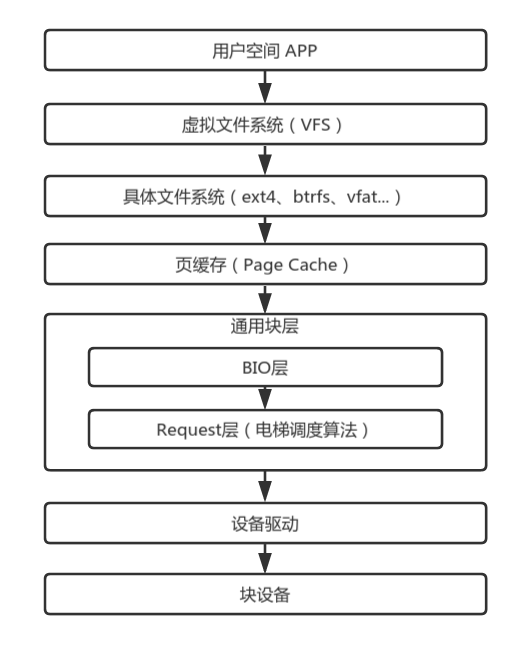
用戶空間:除了用戶自己的APP之外,也隱含了所有的庫,例如常見的C庫。我們常用的IO函數,例如open()/read()/write()是系統調用,由內核直接提供功能實現,而fopen()/fread()/fwrite()則是C庫實現的函數,通過封裝系統調用實現更高級的功能。
虛擬文件系統:屏蔽具體文件系統的差異,向用戶空間提供統一的入口。具體的文件系統通過register_filesystem()向虛擬文件系統注冊掛載鉤子,在用戶掛載具體的文件系統時,通過回調掛載鉤子實現文件系統的初始化。虛擬文件系統提供了inode來記錄文件的元數據,dentry記錄了目錄項。對用戶空間,虛擬文件系統注冊了系統調用,例如SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)注冊了open()的系統調用。
具體的文件系統:文件系統要實現存儲空間的管理,換句話說,其規劃了哪些空間存儲了哪些文件的數據,就像一個個收納盒,A文件保存在這個塊,B文件則放在哪個塊。不同的管理策略以及其提供的不同功能,造就了各式各樣的文件系統。除了類似于vfat、ext4、btrfs等常見的塊設備文件系統之外,還有sysfs、procfs、pstorefs、tempfs等構建在內存上的文件系統,也有yaffs,ubifs等構建在Flash上的文件系統。
頁緩存:可以簡單理解為一片存儲著磁盤數據的內存,不過其內部是以頁為管理單元,常見的頁大小是4K。這片內存的大小不是固定的,每有一筆新的數據,則申請一個新的內存頁。由于內存的性能遠大于磁盤,為了提高IO性能,我們就可以把IO數據緩存在內存,這樣就可以在內存中獲取要的數據,不需要經過磁盤讀寫的漫長的等待。申請內存來緩存數據簡單,如何管理所有的頁緩存以及如何及時回收緩存頁才是精髓。
通用塊層:通用塊層也可以細分為bio層和request層。頁緩存以頁為管理單位,而bio則記錄了磁盤塊與頁之間的關系,一個磁盤塊可以關聯到多個不同的內存頁中,通過submit_bio()提交bio到request層。一個request可以理解為多個bio的集合,把多個地址連續的bio合并成一個request。多個request經過IO調度算法的合并和排序,有序地往下層提交IO請求。
設備驅動與塊設備:不同塊設備有不同的使用協議,而特定的設備驅動則是實現了特定設備需要的協議以正常驅使設備。對塊設備而言,塊設備驅動需要把request解析成一個個設備操作指令,在協議的規范下與塊設備通信來交換數據。
形象點來說,發起一次IO讀請求的過程是怎么樣的呢?
用戶空間通過虛擬文件系統提供的統一的IO系統調用,從用戶態切到內核態。虛擬文件系統通過調用具體文件系統注冊的回調,把需求傳遞到具體的文件系統中。緊接著具體的文件系統根據自己的管理邏輯,換算到具體的磁盤塊地址,從頁緩存尋找塊設備的緩存數據。讀操作一般是同步的,如果在頁緩存沒有緩存數據,則向通用塊層發起一次磁盤讀。通用塊層合并和排序所有進程產生的的IO請求,經過設備驅動從塊設備讀取真正的數據。最后是逐層返回。讀取的數據既拷貝到用戶空間的buffer中,也會在頁緩存中保留一份副本,以便下次快速訪問。
如果頁緩存沒命中,同步讀會一路通到塊設備,而對于 異步寫,則是把數據放到頁緩存后返回,由內核回刷進程在合適時候回刷到塊設備。
根據這個流程,考慮到我沒要到KVM host的權限,我只能著手從Guest端的IO棧做優化,具體包括以下幾個方面:
交換分區(swap)
文件系統(ext4)
頁緩存(Page Cache)
Request層(IO調度算法)
由于源碼以及編譯的臨時文件都不大但數量極其多,對隨機IO的要求非常高。要提高隨機IO的性能,在不改變硬件的情況下,需要緩存更多數據,以實現合并更多的IO請求。
咨詢ITer得知,服務器都有備用電源,能確保不會掉電停機。出于這樣的情況,我們可以盡可能優化速度,而不用擔心掉電導致數據丟失問題。
總的來說,優化的核心思路是盡可能多的使用內存緩存數據,盡可能減小不必要的開銷,例如文件系統為了保證數據一致性使用日志造成的開銷。
交換分區
交換分區的存在,可以讓內核在內存壓力大時,把內核認為一些不常用的內存置換到交換分區,以此騰出更多的內存給系統。在物理內存容量不足且運行吃內存的應用時,交換分區的作用效果是非常明顯的。
然而本次優化的服務器反而不應該使用交換分區。為什么呢?服務器總內存達到47G,且服務器除了Jenkins slave進程外沒有大量吃內存的進程。從內存的使用情況來看,絕大部分內存都是被cache/buffer占用,是可丟棄的文件緩存,因此內存是充足的,不需要通過交換分區擴大虛擬內存。
# free -h total used free shared buffers cached Mem: 47G 45G 1.6G 21M 18G 16G -/+ buffers/cache: 10G 36G
交換分區也是磁盤的空間,從交換分區置入置出數據可也是要占用IO資源的,與本次IO優化目的相悖,因此在此服務器中,需要取消swap分區。
查看系統狀態發現,此服務器并沒使能swap。
# cat /proc/swapsFilename Type Size Used Priority#
文件系統
用戶發起一次讀寫,經過了虛擬文件系統(VFS)后,交給了實際的文件系統。
首先查詢分區掛載情況:
# mount.../dev/sda1 on on / type ext4 (rw)/dev/vda1 on /home type ext4 (rw)...
此服務器主要有兩個塊設備,分別是sda和vda。sda是常見的 SCSI/IDE 設備,我們個人PC上如果使用的機械硬盤,往往就會是sda設備節點。vda是virtio磁盤設備。由于本服務器是 KVM 提供的虛擬機,不管是sda還是vda,其實都是虛擬設備,差別在于前者是完全虛擬化的塊設備,后者是半虛擬化的塊設備。從網上找到的資料來看,使用半虛擬化的設備,可以實現Host與Guest更高效的協作,從而實現更高的性能。在此例子中,sda作為根文件系統使用,vda則是用于存儲用戶數據,在編譯時,主要看得是vda分區的IO情況。
vda使用ext4文件系統。ext4是目前常見的Linux上使用的穩定的文件系統,查看其超級塊信息:
# dumpe2fs /dev/vda1...Filesystem features: has_journal dir_index ......Inode count: 196608000Block count: 786431991Free inodes: 145220571Block size: 4096...
我猜測ITer使用的默認參數格式化的分區,為其分配了塊大小為4K,inode數量達到19660萬個且使能了日志。
塊大小設為4K無可厚非,適用于當前源文件偏小的情況,也沒必要為了更緊湊的空間降低塊大小。空閑 inode 達到 14522萬,空閑占比達到 73.86%。當前 74% 的空間使用率,inode只使用了26.14%。一個inode占256B,那么10000萬個inode占用23.84G。inode 實在太多了,造成大量的空間浪費。可惜,inode數量在格式化時指定,后期無法修改,當前也不能簡單粗暴地重新格式化。
我們能做什么呢?我們可以從日志和掛載參數著手優化
日志是為了保證掉電時文件系統的一致性,(ordered日志模式下)通過把元數據寫入到日志塊,在寫入數據后再修改元數據。如果此時掉電,通過日志記錄可以回滾文件系統到上一個一致性的狀態,即保證元數據與數據是匹配的。然而上文有說,此服務器有備用電源,不需要擔心掉電,因此完全可以把日志取消掉。
# tune2fs -O ^has_journal /dev/vda1tune2fs 1.42.9 (4-Feb-2014)The has_journal feature may only be cleared when the filesystem isunmounted or mounted read-only.
可惜失敗了。由于時刻有任務在執行,不太好直接umount或者-o remount,ro,無法在掛載時取消日志。既然取消不了,咱們就讓日志最少損耗,就需要修改掛載參數了。
ext4掛載參數: data
ext4有3種日志模式,分別是ordered,writeback,journal。他們的差別網上有很多資料,我簡單介紹下:
jorunal:把元數據與數據一并寫入到日志塊。性能差不多折半,因為數據寫了兩次,但最安全
writeback: 把元數據寫入日志塊,數據不寫入日志塊,但不保證數據先落盤。性能最高,但由于不保證元數據與數據的順序,也是掉電最不安全的
ordered:與writeback相似,但會保證數據先落盤,再是元數據。折中性能以保證足夠的安全,這是大多數PC上推薦的默認的模式
在不需要擔心掉電的服務器環境,我們完全可以使用writeback的日志模式,以獲取最高的性能。
# mount -o remount,rw,data=writeback /homemount: /home not mounted or bad option# dmesg[235737.532630] EXT4-fs (vda1): Cannot change data mode on remount
沮喪,又是不能動態改,干脆寫入到/etc/config,只能寄希望于下次重啟了。
# cat /etc/fstabUUID=... /home ext4 defaults,rw,data=writeback...
ext4掛載參數:noatime
Linux上對每個文件都記錄了3個時間戳
| atime | access time | 訪問時間,就是最近一次讀的時間 |
| mtime | data modified time | 數據修改時間,就是內容最后一次改動時間 |
| ctime | status change time | 文件狀態(元數據)的改變時間,比如權限,所有者等 |
| 時間戳 | 全稱 | 含義 |
|---|
我們編譯執行的Make可以根據修改時間來判斷是否要重新編譯,而atime記錄的訪問時間其實在很多場景下都是多余的。所以,noatime應運而生。不記錄atime可以大量減少讀造成的元數據寫入量,而元數據的寫入往往產生大量的隨機IO。
# mount -o ...noatime... /home
ext4掛載參數:nobarrier
這主要是決定在日志代碼中是否使用寫屏障(write barrier),對日志提交進行正確的磁盤排序,使易失性磁盤寫緩存可以安全使用,但會帶來一些性能損失。從功能來看,跟writeback和ordered日志模式非常相似。沒研究過這方面的源碼,說不定就是一回事。不管怎么樣,禁用寫屏障毫無疑問能提高寫性能。
# mount -o ...nobarrier... /home
ext4掛載參數:delalloc
delalloc是delayed allocation的縮寫,如果使能,則ext4會延緩申請數據塊直至超時。為什么要延緩申請呢?在inode中采用多級索引的方式記錄了文件數據所在的數據塊編號,如果出現大文件,則會采用extent區段的形式,分配一片連續的塊,inode中只需要記錄開始塊號與長度即可,不需要索引記錄所有的塊。這除了減輕inode的壓力之外,連續的塊可以把隨機寫改為順序寫,加快寫性能。連續的塊也符合局部性原理,在預讀時可以加大命中概率,進而加快讀性能。
# mount -o ...delalloc... /home
ext4掛載參數:inode_readahead_blks
ext4從inode表中預讀的indoe block最大數量。訪問文件必須經過inode獲取文件信息、數據塊地址。如果需要訪問的inode都在內存中命中,就不需要從磁盤中讀取,毫無疑問能提高讀性能。其默認值是32,表示最大預讀32 × block_size即 64K 的inode數據,在內存充足的情況下,我們毫無疑問可以進一步擴大,讓其預讀更多。
# mount -o ...inode_readahead_blks=4096... /home
ext4掛載參數:journal_async_commit
commit塊可以不等待descriptor塊,直接往磁盤寫。這會加快日志的速度。
# mount -o ...journal_async_commit... /home
ext4掛載參數:commit
ext4一次緩存多少秒的數據。默認值是5,表示如果此時掉電,你最多丟失5s的數據量。設置更大的數據,就可以緩存更多的數據,相對的掉電也有可能丟失更多的數據。在此服務器不怕掉電的情況,把數值加大可以提高性能。
# mount -o ...commit=1000... /home
ext4掛載參數匯總
最終在不能umount情況下,我執行的調整掛載參數的命令為:
mount-oremount,rw,noatime,nobarrier,delalloc,inode_readahead_blks=4096,journal_async_commit,commit=1800/home此外,在/etc/fstab中也對應修改過來,避免重啟后優化丟失
# cat /etc/fstabUUID=... /home ext4 defaults,rw,noatime,nobarrier,delalloc,inode_readahead_blks=4096,journal_async_commit,commit=1800,data=writeback 0 0...
頁緩存
頁緩存在FS與通用塊層之間,其實也可以歸到通用塊層中。為了提高IO性能,減少真實的從磁盤讀寫的次數,Linux內核設計了一層內存緩存,把磁盤數據緩存到內存中。由于內存以4K大小的頁為單位管理,磁盤數據也以頁為單位緩存,因此也稱為頁緩存。在每個緩存頁中,都包含了部分磁盤信息的副本。
如果因為之前讀寫過或者被預讀加載進來,要讀取數據剛好在緩存中命中,就可以直接從緩存中讀取,不需要深入到磁盤。不管是同步寫還是異步寫,都會把數據copy到緩存,差別在于異步寫只是copy且把頁標識臟后直接返回,而同步寫還會調用類似fsync()的操作等待回寫,詳細可以看內核函數generic_file_write_iter()。異步寫產生的臟數據會在“合適”的時候被內核工作隊列writeback進程回刷。
那么,什么時候是合適的時候呢?最多能緩存多少數據呢?對此次優化的服務器而言,毫無疑問延遲回刷可以在頻繁的刪改文件中減少寫磁盤次數,緩存更多的數據可以更容易合并隨機IO請求,有助于提升性能。
在/proc/sys/vm中有以下文件與回刷臟數據密切相關:
| dirty_background_ratio | 觸發回刷的臟數據占可用內存的百分比 | 0 |
| dirty_background_bytes | 觸發回刷的臟數據量 | 10 |
| dirty_bytes | 觸發同步寫的臟數據量 | 0 |
| dirty_ratio | 觸發同步寫的臟數據占可用內存的百分比 | 20 |
| dirty_expire_centisecs | 臟數據超時回刷時間(單位:1/100s) | 3000 |
| dirty_writeback_centisecs | 回刷進程定時喚醒時間(單位:1/100s) | 500 |
| 配置文件 | 功能 | 默認值 |
|---|
對上述的配置文件,有幾點要補充的:
XXX_ratio 和 XXX_bytes 是同一個配置屬性的不同計算方法,優先級 XXX_bytes > XXX_ratio
可用內存并不是系統所有內存,而是free pages + reclaimable pages
臟數據超時表示內存中數據標識臟一定時間后,下次回刷進程工作時就必須回刷
回刷進程既會定時喚醒,也會在臟數據過多時被動喚醒。
dirty_background_XXX與dirty_XXX的差別在于前者只是喚醒回刷進程,此時應用依然可以異步寫數據到Cache,當臟數據比例繼續增加,觸發dirty_XXX的條件,不再支持應用異步寫。
更完整的功能介紹,可以看內核文檔Documentation/sysctl/vm.txt,也可看我寫的一篇總結博客《Linux 臟數據回刷參數與調優》
對當前的案例而言,我的配置如下:
dirty_background_ratio = 60dirty_ratio = 80dirty_writeback_centisecs = 6000dirty_expire_centisecs = 12000
這樣的配置有以下特點:
當臟數據達到可用內存的60%時喚醒回刷進程
當臟數據達到可用內存的80%時,應用每一筆數據都必須同步等待
每隔60s喚醒一次回刷進程
內存中臟數據存在時間超過120s則在下一次喚醒時回刷
當然,為了避免重啟后丟失優化結果,我們在/etc/sysctl.conf中寫入:
# cat /etc/sysctl.conf...vm.dirty_background_ratio = 60vm.dirty_ratio = 80vm.dirty_expire_centisecs = 12000vm.dirty_writeback_centisecs = 6000
Request層
在異步寫的場景中,當臟頁達到一定比例,就需要通過通用塊層把頁緩存里的數據回刷到磁盤中。bio層記錄了磁盤塊與內存頁之間的關系,在request層把多個物理塊連續的bio合并成一個request,然后根據特定的IO調度算法對系統內所有進程產生的IO請求進行合并、排序。那么都有什么IO調度算法呢?
網上檢索IO調度算法,大量的資料都在描述Deadline,CFQ,NOOP這3種調度算法,卻沒有備注這只是單隊列上適用的調度算法。在最新的代碼上(我分析的代碼版本為 5.7.0),已經完全切換到multi-queue的新架構上了,支持的IO調度算法就成了mq-deadline,BFQ,Kyber,none。
關于不同IO調度算法的優劣,網上有非常多的資料,本文不再累述。
在《Linux-storage-stack-diagram_v4.10》對 Block Layer 的描述可以形象闡述單隊列與多隊列的差異。
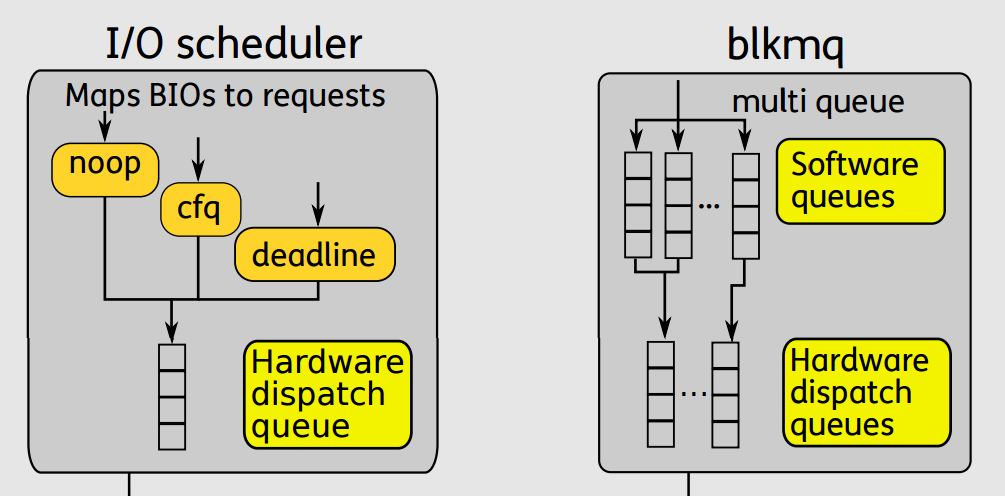
單隊列的架構,一個塊設備只有一個全局隊列,所有請求都要往這個隊列里面塞,這在多核高并發的情況下,尤其像服務器動則32個核的情況下,為了保證互斥而加的鎖就導致了非常大的開銷。此外,如果磁盤支持多隊列并行處理,單隊列的模型不能充分發揮其優越的性能。
多隊列的架構下,創建了Software queues和Hardware dispatch queues兩級隊列。Software queues是每個CPU core一個隊列,且在其中實現IO調度。由于每個CPU一個單獨隊列,因此不存在鎖競爭問題。Hardware Dispatch Queues的數量跟硬件情況有關,每個磁盤一個隊列,如果磁盤支持并行N個隊列,則也會創建N個隊列。在IO請求從Software queues提交到Hardware Dispatch Queues的過程中是需要加鎖的。理論上,多隊列的架構的效率最差也只是跟單隊列架構持平。
咱們回到當前待優化的服務器,當前使用的是什么IO調度器呢?
# cat /sys/block/vda/queue/schedulernone# cat /sys/block/sda/queue/schedulernoop [deadline] cfq
這服務器的內核版本是
# uname -r3.13.0-170-generic
查看Linux內核git提交記錄,發現在 3.13.0 的內核版本上還沒有實現適用于多隊列的IO調度算法,且此時還沒完全切到多隊列架構,因此使用單隊列的 sda 設備依然存在傳統的noop,deadline和cfq調度算法,而使用多隊列的 vda 設備(virtio)的IO調度算法只有none。為了使用mq-deadline調度算法把內核升級的風險似乎很大。因此IO調度算法方面沒太多可優化的。
但Request層優化只能這樣了?既然IO調度算法無法優化,我們是否可以修改queue相關的參數?例如加大Request隊列的長度,加大預讀的數據量。
在/sys/block/vda/queue中有兩個可寫的文件nr_requests和read_ahead_kb,前者是配置塊層最大可以申請的request數量,后者是預讀最大的數據量。默認情況下,
nr_request = 128read_ahead_kb = 128
我擴大為
nr_request = 1024read_ahead_kb = 512
優化效果
優化后,在滿負荷的情況下,查看內存使用情況:
# cat /proc/meminfoMemTotal: 49459060 kBMemFree: 1233512 kBBuffers: 12643752 kBCached: 21447280 kBActive: 19860928 kBInactive: 16930904 kBActive(anon): 2704008 kBInactive(anon): 19004 kBActive(file): 17156920 kBInactive(file): 16911900 kB...Dirty: 7437540 kBWriteback: 1456 kB
可以看到,文件相關內存(Active(file) + Inactive(file) )達到了32.49GB,臟數據達到7.09GB。臟數據量比預期要少,遠沒達到dirty_background_ratio和dirty_ratio設置的閾值。因此,如果需要緩存更多的寫數據,只能延長定時喚醒回刷的時間dirty_writeback_centisecs。這個服務器主要用于編譯SDK,讀的需求遠大于寫,因此緩存更多的臟數據沒太大意義。
我還發現Buffers達到了12G,應該是ext4的inode占用了大量的緩存。如上分析的,此服務器的ext4有大量富余的inode,在緩存的元數據里,無效的inode不知道占比多少。減少inode數量,提高inode利用率,說不定可以提高inode預讀的命中率。
優化后,一次使能8個SDK并行編譯,走完一次完整的編譯流程(包括更新代碼,抓取提交,編譯內核,編譯SDK等),在沒有進入錯誤處理流程的情況下,用時大概13分鐘。
這次的優化就到這里結束了,等后期使用過程如果還有問題再做調整。
-
數據
+關注
關注
8文章
7246瀏覽量
91103 -
服務器
+關注
關注
13文章
9716瀏覽量
87353
原文標題:打通IO棧:一次編譯服務器性能優化實戰
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

RakSmart服務器成本優化策略
存儲服務器怎么搭建?RAKsmart實戰指南
DeepSeek企業級部署實戰指南:以Raksmart企業服務器為例
Supermicro高性能服務器量產供貨,優化多重工作負載
NTP服務器的性能優化方法
λ-IO:存儲計算下的IO棧設計






 工商網監
工商網監
評論