 百度端對端語音識別專利揭秘
百度端對端語音識別專利揭秘
百度公司提出的端對端神經網絡模型來進行語音識別,成功的代替了手工工程化部件的流水線操作,這讓整個語音識別技術更加便捷,而使用神經網絡來抽取輸入端的特征信息相當于人功抽取特征則更加全面。
集微網消息,近年來,語音識別技術得到了迅猛的發展,這得益于人工智能的快速發展,其中最為主要的學業界的各大神經網絡的出現,包括基礎的序列神經網絡模型RNN、LSTM和GRU。語音識別技術也已經進入到各行各業中,如工業、家電、通信和汽車電子等。于是,對于語音識別技術的要求也將更加嚴格了,更傾向于走向準確化和便捷化。
以往,構建語音識別模型主要是使用HMM的序列模型,再使用手工工程化部件來實現整個流水線操作,并且對于不同的語言的語音需要重新構建模型的結果特征。對此,國內語音識別技術第一梯隊公司百度便提出了使用端對端的神經網絡模型來進行語音識別工作,該專利為“端對端語音識別”(專利號:CN107408111A)。
首先,小編在這先介紹一下神經網絡端對端的學習方式。對于語音識別來說,端到端深度學習做的是,訓練一個深度神經網絡,輸入就是一段音頻,輸出直接是聽寫文本。其中這里的端表示輸入源數據端,另外一端是神經網絡處理的結果也就是我們最終需要的目標。這種訓練學習的方式能應對多種語言的語音識別的場景構建,因為僅僅是需要改變輸入端和輸出端,深度神經網絡的結構并不需要根據語言的語音不同而改變。
專利中提出的端對端的深度學習模型的架構圖如圖1所示。該架構包括訓練以攝取語譜并生成文本的遞歸神經網絡模型。首先,使用一個或更多個卷積層對語譜進行特征提取,緊接著,使用一個或多個遞歸層(雙向GRU神經網絡)對語譜的特征進行時序建模。最后再使用全連接層將遞歸層獲取的語譜信息進行全連接作為CTC(鏈結式時間分類算法:重點解決輸入數據與給定標簽的對齊問題)的輸入,經過Softmax計算輸出各個文本標簽的概率。
圖1端對端深度學習模型架構圖
經過上述端對端深度學習模型構建后,專利中還給出了端對端深度學習模型的訓練方法,如圖2所示。
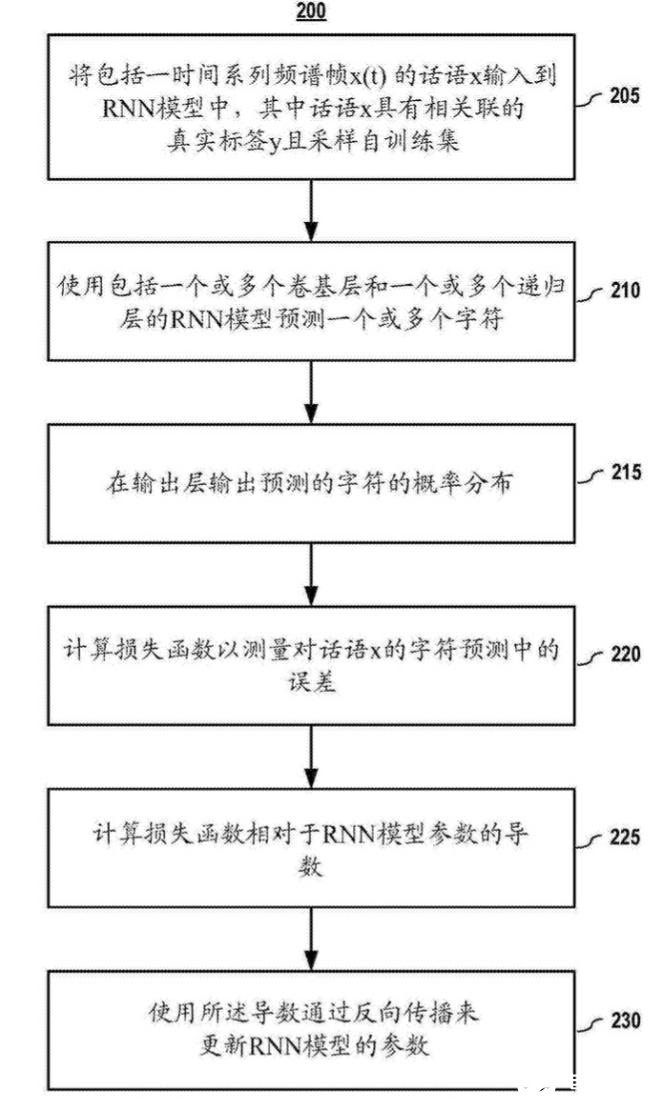
圖2 端對端深度學習模型訓練方法圖
首先需要為模型設置好,輸入端和輸出端,對于語音識別技術來說,輸入端為一時間序列頻譜幀的話語X,輸出端是與話語X具有相關聯的真實標簽Y。
構建深度神經網絡模型(包括一個或多個卷積層和一個或多個遞歸層的模型)用來預測一個或多個字符也就是我們輸出端的標簽。
根據網絡模型的輸出端的標簽的概率分布與真實標簽的誤差計算損失函數,提供損失函數推出標簽預測的誤差,再使用梯度反向傳播算法更新模型參數。從而達到網絡模型學習的目的。
百度公司提出的端對端神經網絡模型來進行語音識別,成功的代替了手工工程化部件的流水線操作,這讓整個語音識別技術更加便捷,而使用神經網絡來抽取輸入端的特征信息相當于人功抽取特征則更加全面,這讓整個語音識別技術更加準確。從這兩方面來看,端對端的神經網絡模型確實是讓語音識別技術走向了便捷化,準確化。
-
百度
+關注
關注
9文章
2325瀏覽量
91804 -
語音識別
+關注
關注
39文章
1773瀏覽量
113894
發布評論請先 登錄
上汽大眾與百度地圖達成戰略合作

百度文心大模型4月1日起全面免費開放
百度百科啟動“繁星計劃”
ElfBoard開源項目|百度智能云平臺的人臉識別項目






 工商網監
工商網監
評論