 深度學習從社交媒體中為你發掘最美穿搭
深度學習從社交媒體中為你發掘最美穿搭

穿衣搭配不僅反映個人的審美同時也與出席的場合、文化傳統息息相關。在一個時尚場景中,通常會包含三個要素:場合、個體和衣著。這些時尚信息和知識對于衣著推薦搭配等應用十分重要。而當今高度發展的社交媒體為時尚知識提供了豐富的資源,從朋友圈到微博從推特到Ins,人們在不同場合的穿搭圖像、文字和多媒體信息構成了龐大的信息資源。
來自新加坡國立大學的研究人員們利用深度學習集成多種方法來從社交媒體中抽取時尚三要素,以實現時尚知識的自動化抽取和學習,同時還構建了以用戶為中心時尚知識抽取數據集FashionKE。
時尚時尚最時尚
隨著生活水平的不斷提高,人們的時尚需求不斷增加,對于不同場合的衣著搭配也有著更為精細化的需求。面對這個萬億級的時尚市場,如何將機器學習與深度學習更有效的應用于時尚知識的學習、穿搭推薦甚至是知識級別的構建是科技巨頭和研究人員們的研究熱點。
目前對于時尚知識級別的研究工作還比較有限,如何有效的穿衣搭配涉及到場景、主體和衣著三個關鍵因素。在日常生活有很多固定的經驗和模式幫助人們進行有效的穿搭,但研究人員希望將這些模式總結成更為凝練的知識以指導不同的人在對應的場合進行最適宜的穿搭。在這一過程中,需要面對的第一個問題就是,從哪里去獲取這些知識呢?如何獲取這些知識呢?新加坡國立大學的研究人員給出了自己的答案。
他們將目光放到了各大社交媒體平臺,從中進行以用戶為中心的自動化時尚知識抽取,來幫助實現這一目標。為什么呢?社交媒體的龐大用戶規模保證了多模態數據的豐富和質量,不僅包含了世界各地、各個場景中用戶的照片,同時也包含了包括性別在內的個人屬性,而且還緊跟時尚潮流更新迅速。但有些利用這些數據還面臨著一系列挑戰。
首先時尚知識的抽取很大程度上決定于時尚概念和屬性抽取器的表現,包括對于場景、衣著和飾品的識別檢測。雖然現在在學術界有很多研究成果,但大多集中于簡單干凈的背景上,而現實中面對的卻是豐富多樣的自然場景,使得屬性檢測變得十分困難。第一個需要解決的挑戰就是需要實現自然場景和背景的時尚概念和屬性檢測。
其次社交媒體雖然豐富,但基本上缺乏時尚概念的標注,但這對時尚知識的構建十分重要。時尚知識自動獲取的質量極大地依賴于語義級的時尚概念學習。手工標記如此龐大的數據是不現實的,而現存的電子商務數據主要集中于衣著屬性,缺乏人物和場景屬性的標注。 如何解決這兩個問題成為了實現知識抽取的關鍵。
時尚知識自動化抽取
為了解決這兩個問題,研究人員提出了一種基于弱標記數據的時尚概念聯合檢測方法。這種基于上下文的時尚概念學習模塊可以有效捕捉不同時尚概念間的聯系和相關性,通過場景、衣著分類和屬性來輔助時尚知識抽取。其中弱標記數據則有效應對了缺乏標記數據的困擾,在標記遷移矩陣幫助下,通過機器標記數據和干凈數據的結合可有效控制學習過程中的噪聲。
這一研究的目標在于從社交媒體中抽取用戶為中心的時尚知識數據,得到場景對應穿著的結構化數據為下游任務提供應用基礎。
研究人員將時尚知識定義為個體、衣著和場合三元組合K={P,C,O},其中個體包括了人的屬性:性別、年齡、身材;服裝則包括了衣著的屬性和分類,用于定義特定類型的服飾,例如:一條深藍色的露肩長裙;場景則包含了各種主體出席的場合、包括舞會、約會、會議、聚會等等及其相關的時間地點元數據。
研究人員的任務就是要從某個po出的社交媒體信息{V(圖像),T(文字),M(元數據)}中抽取出上面的信息構成時尚知識{P,C.Q}。這一任務自然包含了三個子任務:人體屬性檢測、衣著分類和屬性檢測、場景檢測。
人體檢測框架目前很成熟,所以研究人員致力于后兩個子任務的開發,從社交媒體數據中聯合檢測出主體所處的場景和服裝分類屬性。
為了有效檢測場景及其主體的衣著分類屬性,研究人員設計了一套統一的框架來獲取其屬性及相關性。這套基于上下文時尚概念的學習模型包含了兩個雙邊回歸神經網絡來捕捉場景、衣著間的聯系。
對于某篇包含圖像V和文字T社交媒體來說,這一模型首先將衣著檢測模型檢測圖像中一系列的服飾區域。隨后針對圖像預測出對應的場景標簽,針對每個服裝區域預測出對應的服裝類別和屬性標簽。為了有效的預測出這三者之間的相關性,研究人員利用基于上下文的方式來從中得到不同屬性間的關系以便抽取知識。為了有效抽取知識,需要對服裝分類、場景和服裝屬性的表示進行學習。
分類表達。模型的第一步是學習服裝區域的上下文表示用于分類預測和整幅圖像的場景預測。研究人員首先利用與訓練的CNN來抽取全圖和每個服裝區域的特征表示,隨后利用雙邊LSTM來編碼所有服裝區域間的相關性,并最終得到服裝區域的分類表達。
場景表達。為了更好的表達整幅圖像,研究人員將第一步中整幅圖像的CNN特征、上一步Bi-LSTM的最后隱含狀態及TextCNN抽取文字描述特征結合為新的特征,來實現場景表達學習;
屬性表達。最后,由于每種服裝有包括顏色、長短、外形等多個不同特征,所以需要屬性預測模塊來預測屬性。研究人員利用多分支的結構來對不同種類的服飾進行屬性預測,每個分支輸出層的神經元數量代表了對應的屬性數目。
隨后為了捕捉不同服飾屬性和服飾分類間的依賴關系,研究人員使用了第二個雙邊LSTM來編碼屬性和分類間的依賴關系,并最終通過全連接轉換為屬性表達。最終通過標準的分類器將得到場景、服裝分類和屬性的預測分數。
為了對這一模型進行訓練,研究人員構建自己的數據集FashionKE,其中包含了80629張圖像,可以容易辨認出時尚知識的三要素。同時對每張圖片進行了場景標注(十種主要場景);而針對服裝屬性和分類標注,由于社交媒體數據過于龐大,對于每一個圖像和文字數據進行多種屬性的手工標注是不現實的。只有30%的數據進行了人工核對,其他數據都利用時尚標簽工具進行機器標注。
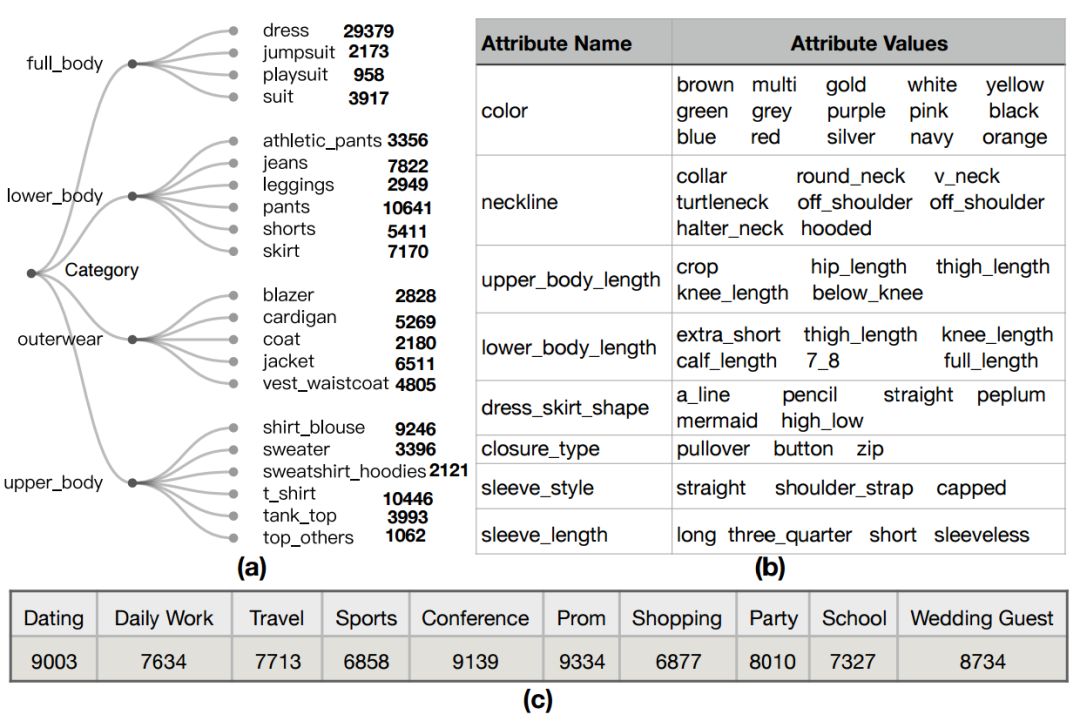
機器標注的數據很廉價,但是卻包含很多的噪聲,使得模型的訓練容易出現過擬合。為了充分利用機器標注的數據和少量人類標記數據,研究人員引入了弱標記建模的方法來處理機器標記數據中的噪聲。其基本思想是在模型中添加一個標簽校正層,在預測層后利用估計出的標簽轉換矩陣來實現,使得預測與弱標記的數據分布相匹配。這一轉換矩陣將通過與主干任務協同訓練的線性層來得到。
實驗和結果
研究人員在實驗中發現新提出的框架和策略有效的實現了時尚概念的預測。通過與DARN、FashionNet和EITree的比較本文的方法在多個指標上都超過了先前的方法。
一方面,由于本方法充分使用了機器標注的模型并通過弱標記建模模塊抑制了標注噪聲的影響,從而得到了額外的增益。這一模型將場景、服裝分類和屬性間的依賴性和相關性進行了考量,為時尚概念的識別提供了額外辨別能力。這些依賴性和相關性表明時尚知識的存在以及對于相關應用的積極作用。
另一方面,這一方法還通過文字信息進一步提升了性能,特別是在場景分類中很多社交媒體的問題信息包含了豐富的場景信息,有助于時尚信息的抽取。
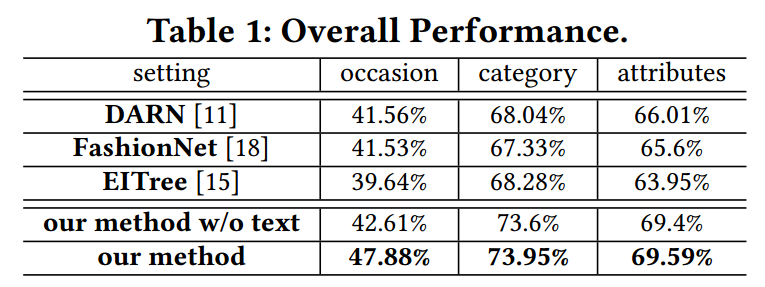
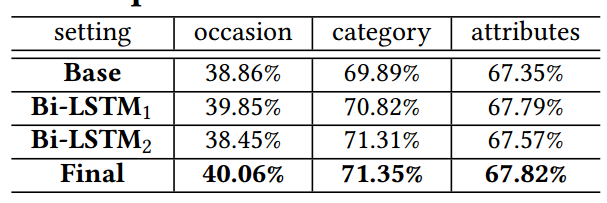
此外通過消融性分析,研究人員發現第一個Bi-LSTM通過學習出不同服裝區域間的相關性來提升了分類性能,并通過將隱含層的加入來替身了場景預測性能;第二個Bi-LSTM則通過不同屬性表達和分類表達間的依賴性建模來提升性能;同時兩個LSTM間的協同作用也將顯著加強模型知識抽取能力。
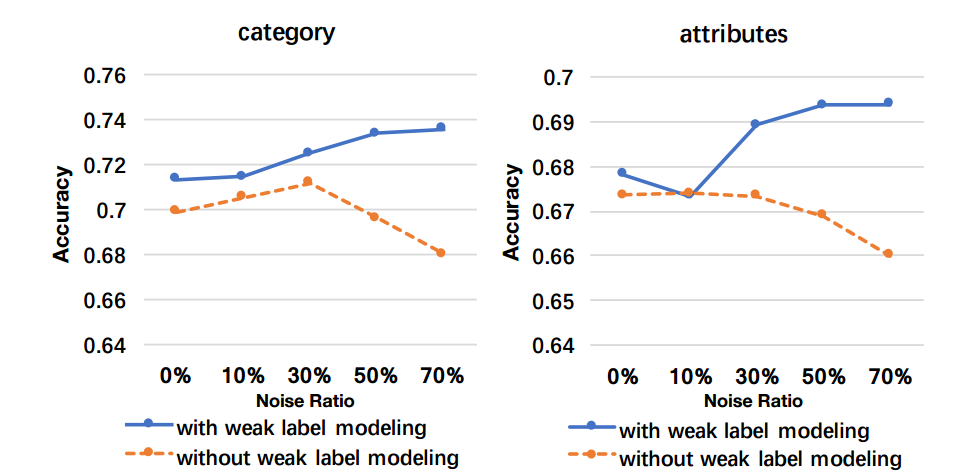
最后通過不同比例的噪聲數據對模型訓練也顯示出弱標記建模對于知識抽取能力的提升。
最后研究人員們還展示了基于這一模型在不同領域的應用。
從時尚概念抽取時尚知識,圖中展示了一部分結構化的時尚知識
不同場景下人們的穿著服飾分析,包括國家、場合和季節都有著明顯的區分。
時尚知識分析,包含了不同季節和不同地區不同場合的穿著。
下圖還顯示了不同場合中最流行的服飾,包括了其中縱軸是男性女性對應的十種場景、橫軸是對應的流行穿著。可以看到會議中男性傾向于穿著夾克外套、舞會中女性則喜愛各種連衣裙。
同時研究人員們還分析了不同屬性和分類間的相關性,圖中的節點大小代表了服飾的數量,邊的寬度代表了相關性的強弱。可以看到牛仔褲和襯衫T恤都是大家的最愛搭配。而不同屬性間的相關性中可以看到長款衣服還是主流,長袖長褲是主流搭配。
在未來研究人員們還將探索包括時尚穿搭推薦的不同領域的應用,并對更加細粒度的知識進行抽取,同時加入不同的視覺概念來實現包括交叉模態檢索和人體檢索等更多的檢索任務。
-
模塊
+關注
關注
7文章
2788瀏覽量
50357 -
神經網絡
+關注
關注
42文章
4814瀏覽量
103574 -
深度學習
+關注
關注
73文章
5561瀏覽量
122791
原文標題:對面的女孩看過來,深度學習從社交媒體中為你發掘最美穿搭
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
嵌入式AI技術之深度學習:數據樣本預處理過程中使用合適的特征變換對深度學習的意義
軍事應用中深度學習的挑戰與機遇
銅排搭接面是否需要滿搭
AI自動化生產:深度學習在質量控制中的應用







 工商網監
工商網監
評論