 關于加快CNN模型在計算資源受限的應用場景的速度的分析研究
關于加快CNN模型在計算資源受限的應用場景的速度的分析研究

自馭勢科技AI男子天團出道以來,大家都在求“不是博士的小伙伴韋濤的心理陰影面積”。
正確答案是,他的內心沒有陰影!他忙著給大家解讀一篇有意思的論文呢!
韋濤,畢業于北京大學軟件與微電子學院,處女座……
他用“樂觀,踏實,好奇心重”三個詞來形容自己。作為馭勢科技AI天團成員,除了顔值,還需要會寫代碼,會搞算法,會調板子,會調車子。如果問他,怎么給好基友介紹馭勢科技?韋濤說,這里是一個仰望星空,腳踏實地的地方。而青春,就意味著努力工作。
對于那些對AI感興趣的朋友,韋濤特別推薦《深度學習》“大花書”給大家。
能不能看懂,就看你的IQ了~

該論文主要通過利用Batchnorm Layer中的Scale參數來對模型中通道重要程度進行建模,并引入了L1正則項來對該通道權值進行稀疏化訓練,使得最終得到的模型可以更有效的實現通道剪枝,達到網絡稀疏化的目標。該論文的通道稀疏化的實現方式非常巧妙。
近些年來,CNN由于其出色的表現,漸漸成為了圖像領域中主流的算法框架。
在自動駕駛領域中,許多任務同樣可被抽象為圖像分類、圖像分割、目標檢測三個基礎問題,因此,CNN在自動駕駛領域中的應用也越來越廣泛。
CNN的表現如此突出主要是因為CNN模型有大量的可學習參數,使得CNN模型具備很強的學習能力和表達能力,然而,也正因為這些大量的參數使得在硬件平臺上部署CNN模型時有較大困難,尤其是在一些計算資源非常受限的平臺上,如移動設備、嵌入式設備等。
在自動駕駛場景中,視覺系統在整個車輛系統中一直扮演著一個十分重要的角色,在視覺算法實際投入應用時,不僅需要算法精度達到極高的指標,也對算法的實時性提出了較高的要求,與此同時,由于場景的特殊性,在自動駕駛場景中算法往往會被部署在一些計算能力較弱的嵌入式開發平臺上,因此,如何讓CNN模型在計算資源受限的應用場景中跑的更快成為了一個越來越重要的課題。
目前對CNN模型進行加速的方法很多,例如,從快速網絡結構設計的角度出發設計設計一些小而精的模型(squeezenet、mobilenet、enet等),從網絡壓縮角度出發對訓練好的網絡在保證精度不變或小幅下降的前提下進行壓縮剪枝(deep compression、channel-pruning等)等。
摘要
一直以來,由于受限于CNN模型的計算量,在各種實際應用場景中部署CNN模型一直都是個問題。本文提出了一種新型的網絡學習方法以達到如下的三個目標:(1)減少模型大小(2)減小運行時內存 (3)減少計算量。
為了實現上述目標,本文主要通過強制增加channel-level的參數并對該參數進行稀疏化訓練來實現。與其他的方法不同的是,本文的算法直接應用于訓練的環節中,以增加少量計算開銷的前提下實現了網絡的稀疏化訓練。
本文將該算法稱作network slimming,該算法的輸入是一個“寬大”的網絡,在訓練過程中,那些不重要的通道會隨著訓練權值逐漸降低,并通過后處理算法進行通道裁剪,最終得到一個沒有精度損失的“瘦小”的網絡。
本文在主流的CNN網絡結構上驗證了該方法,包括VGGNet, ResNet,DenseNet等,并在多個數據集上進行了驗證。對于VGGNet, 在經過多次network slimming以后,該模型達到了20倍的模型尺寸壓縮比以及5倍的模型計算量壓縮比。
引言
近些年來,CNN在多種視覺任務中已經變成了一種主流的方法,比如圖像分類,目標檢測以及圖像分割任務等。隨著大規模數據集、高端gpu以及新型網絡結構的出現,使得一些大模型的部署成為了可能。比如,imagenet比賽中的冠軍模型從AlexNet、VGGNet以及GoogLeNet再到ResNet,模型規模逐漸從8層演變成100層以上。
雖然這些大模型具備較強的表達能力,但是這些模型對計算資源的需求也更苛刻。例如像ResNet-152這樣的模型,由于需要大量的計算量,因此很難被部署在移動設備以及其他的IOT設備上。
上述提及的部署困難主要受限于如下的三個因素:
1.模型尺寸。CNN模型的強表達能力主要來源于他具有大量可學習的參數,而這些參數將和網絡的結構信息一起被保存在存儲介質上,當需要使用模型做inference時,再從硬盤上進行讀取。舉例來說,存儲一個典型的在 ImageNet上訓練好的模型需要大約300MB的空間,這對于嵌入式設備來說是一個非常大的開銷。
2.運行時內存的消耗。在inference過程中,即使batchsize =1,中間層的計算需要消耗遠大于模型參數量的內存空間。這對于一些高端的GPU可能不是什么問題,但是對于一些計算資源比較緊張的設備而言,這是一個比較大的部署問題。
3.計算量的大小。當把一款大型CNN模型部署于移動設備上時,由于計算量大同時移動設備計算性能弱,因此可能會消耗數分鐘去處理一張圖片,這對于一款模型被部署于真實應用中是一個比較大的問題。
當然,現在有很多工作提出可以通過壓縮CNN模型來使得模型具備更快的inference性能,這些方法主要包括低秩分解、模型量化、模型二值化、參數剪枝等。然而上述所說的方法都只能解決之前所提到的三個主要問題中的一個或兩個,同時,部分方法還需要軟件或硬件的支持才能實現真正的加速。
另一個減少CNN計算資源消耗的方法就是網絡稀疏化。稀疏化可被應用于不同的層級。本文提出了一種network slimming的網絡稀疏化方法,該方法解決了在資源有限的場景下上述所提到的問題。
本文的方法中,主要通過對BatchNorm layer中的scale參數應用了L1正則項,從而非常方便的在當前的框架下實現了通道稀疏化。在該方法中,L1正則項將會使得不重要的通道的BatchNorm Layer中的scale參數推向0附近,通過這樣的方法,算法篩選出了不重要的通道,為后續的通道剪枝帶來了很多的便利。
與此同時,在該算法中引入的L1正則項并沒有帶來精度的損失,相反,在一些案例中,反而得到了更高的精度。在做通道剪枝的過程中,裁剪掉一些不重要的通道(即低權值的通道)可能會帶來一些精度的損失,但是這些損失的精度可以通過后續的fine-tuning操作補償回來。剪枝得到的壓縮版網絡在模型尺寸、運行時內存占用以及計算量方面與初始的網絡相比更具競爭力。上述所說的過程可以被重復數次,在進行多道裁剪工序后將會得到壓縮比越來越高的網絡模型。
根據本文在多個數據集上的實驗結果可以驗證本文的網絡在經過slimming操作后,實現了20倍的模型尺寸壓縮以及5倍的模型計算量壓縮,而在精度方面沒有損失,甚至反而比原始模型更高。此外,由于本文的算法并沒有對網絡進行參數存儲方式對修改,因此該方法可適用于在常規的硬件平臺以及軟件包上實現網絡壓縮以及inference加速。
Network Slimming
本文的目標是提供一個簡單的策略在CNN上實現通道稀疏。在本章節將對channel-level稀疏的優勢以及難點做一些分析,并且介紹了本文如何通過BatchNormLayer的scale參數來實現通道稀疏化。
(1)channel-level 稀疏化的優勢
網絡稀疏化可以被應用于不同的層級中,主要可分為weigh-level、kernel-level、channel-level或者layer-level。weight-level的稀疏化通常具備高度的靈活性以及通用性,并帶來了較大的壓縮比,但是該方案通常需要特殊的軟硬件加速的支持才能實現最終的加速。
與此相反,layer-level的方案不需要特殊軟硬件加速的支持即可實現最終的加速,但是這種方案相比weight-level不夠靈活,部分層需要被整個裁剪掉,同時,該方案只會在網絡層數特別深的前提下才會顯得比較有效。因此,根據上述的對比,channel-level的稀疏化在靈活性以及實現難度方面達到了一個較好的平衡,該方案可被用于各種典型的CNN模型中,為每一個原始模型生成一個“瘦身”版的網絡模型,該模型可以在各個常規的CNN平臺上高效的運行。
(2)channel-level稀疏化的挑戰
要實現channel-level的稀疏化需要裁剪掉所有與被裁剪通道相關的輸入通道以及輸出通道。直接用算法根據通道權值去裁剪一個預訓練模型的通道會比較低效,因為不是所有的通道權值都會分布在0附近。如論文[23]所闡述的,直接在預訓練好的ResNet中裁剪時,在精度不損失的前提下,只能裁剪掉~10%的通道。論文[35]通過引入了強制的稀疏正則項來實現通道權值的稀疏化,令通道的權值分布在0附近。本文提出了一種新方法來解決上述問題。
本文的方法就是為每一個通道引入一個scale 因子,該因子將對該通道的輸出做乘積運算,從而實現對通道重要程度的建模,本文對模型參數以及scale因子進行聯合訓練,最后把那些scale因子小的通道裁剪掉并fine-tune整個網絡。在引入了正則項以后,優化的目標函數如下式所示:
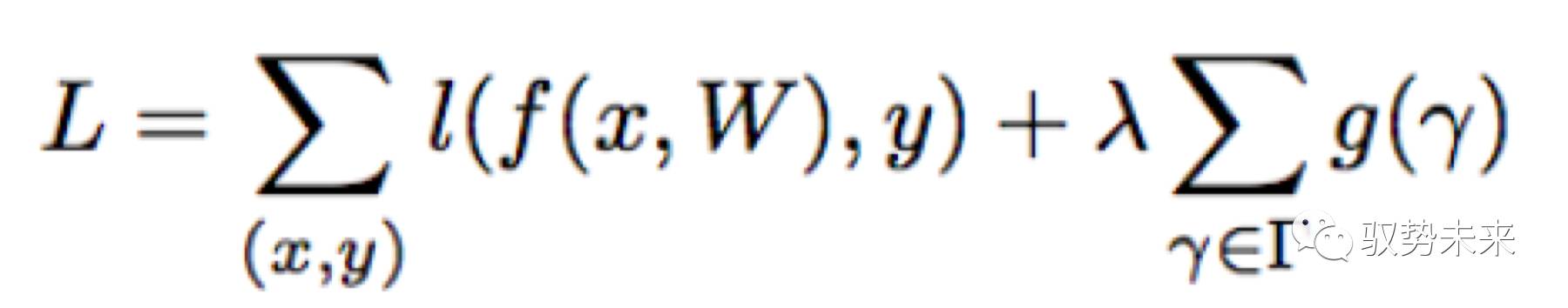
上式中,(x,y)表示訓練的輸入項與目標項,W表示可訓練的參數,第一項表示CNN常規的訓練損失, g(.)是一個引入在scale因子γ上的懲罰項,入表示第一項與第二項之間的權重比。在本文在實現中采用了g(s)=|s|,即L1正則項,被廣泛應用于實現網絡稀疏化,同時采用了subgradient descent的優化方法來優化L1正則項。
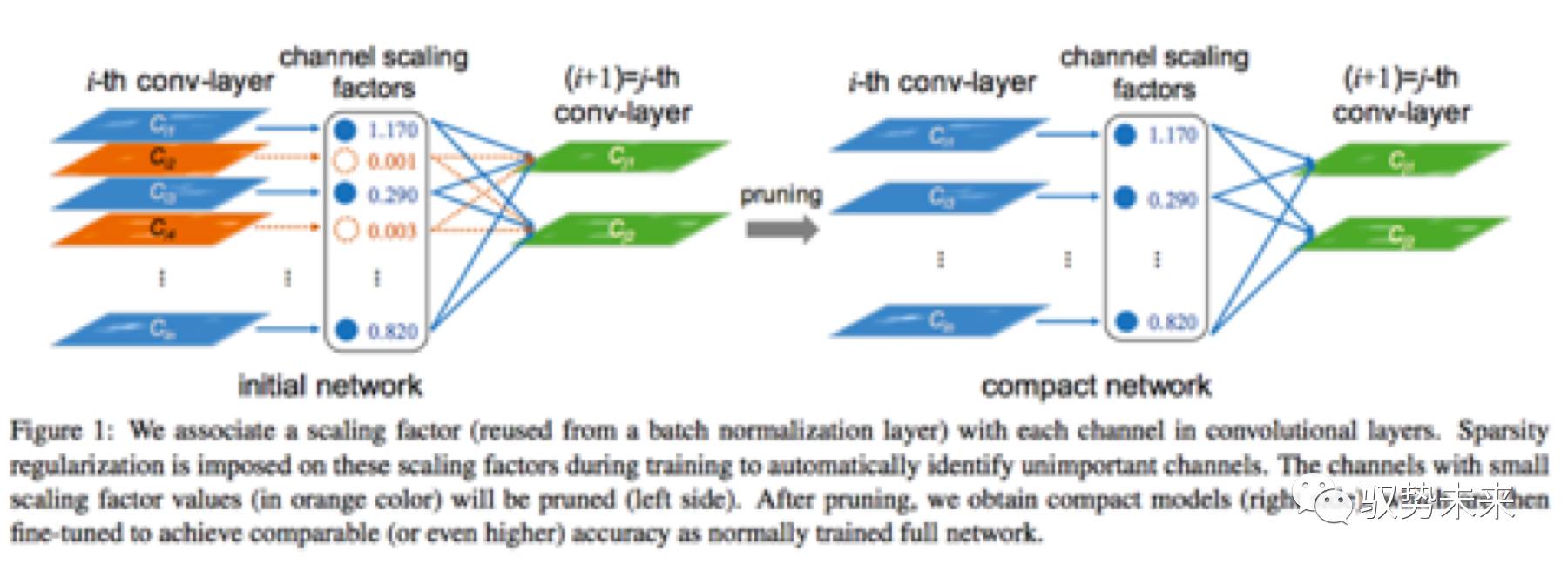
如上圖Figure 1所示,當需要裁剪一個通道時僅需要移除該通道的輸入與輸出的連接即可得到一個壓縮后的模型而不需要做其他的一些特殊操作。同時,由于在訓練過程中,scale因子實現了對通道的重要程度的建模,因此,當后續做剪枝時,僅需要直接移除那些不重要的通道即可而不會影響模型整體的泛化能力。
(1)利用BatchNorm Layer進行channel-wise的稀疏化
BatchNorm 層已經被廣泛的應用于各種CNN結構中,作為一種標準的方法來實現快速收斂以及增強泛化能力。BatchNorm Layer的設計思路啟發了作者去設計一種簡單有效的方法來實現channel-wise稀疏化。BatchNorm Layer的計算定義如下:
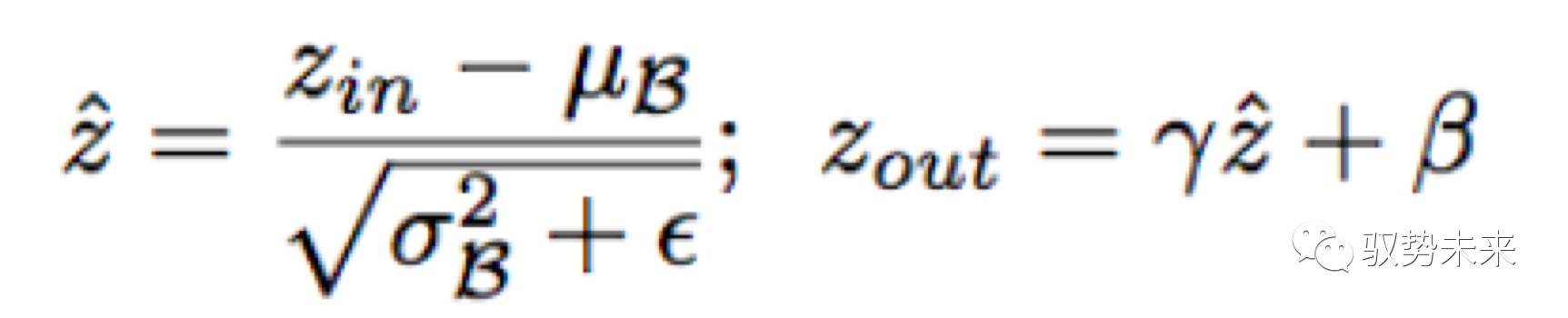
其中zin與zout分別代表Batchnorm Layer 的輸入和輸出,與分別表示當前mini-batch下面的均值與方差,而與是可學習的參數,可以將規范化后的分布返回到任何一種原始尺度下。
將BN層放置在Convolution層的后面是一種非常通用的方法。因此,可以直接利用BN層中的γ參數來建模通道的重要性,通過這樣的設計,不需要引入額外的實現就能達到算法的設計目標,事實上,這是可以用來實現channel-wise稀疏化的最有效也是最快捷的方法。接下來討論一下ScaleLayer的放置問題。
1.假如只是在Convolution后面增加了scale層而沒有使用Batchnorm Layer,Scale層學到的參數對于評估通道的重要性沒有意義,因為,Convolutionlayer和Scale layer都是線性變換,可以通過減少Scale因子的值同時放大Convolution Layer的參數值來達到同樣的目標。
2.假如將Scale Layer放置在BatchnormLayer前,Scale Layer的效果會被BatchnormLayer 的規范化效果完全抵消掉。
3.將ScaleLayer 插入在Batchnorm Layer 之后時,就可以為每一個通道提供兩個scale參數進行通道建模了。
(2)通道剪枝以及Finetune
在引入L1正則項進行網絡稀疏化訓練以后就可以得到一個多數通道權值在0附近的模型。之后對網絡這些權值在0附近的通道進行裁剪,將這些通道對應的輸入輸出的連接移除。在裁剪過程中,本文采用了一個全局裁剪閾值,比如,當需要裁剪70%的通道時,本文會選取一個裁剪百分位為70%的閾值。通過這樣的操作即可得到裁剪后的模型。
經過上述的裁剪操作后,如果采用的裁剪比例較高可能會帶來部分精度的損失,但是這部分損失可以通過后續的Finetune操作補償回來。在作者的實踐過程中發現,在進行Finetune操作后,裁剪后的模型往往會比原始的未裁剪的網絡精度高。
(3)多次循環剪枝
本文的方法可以從單步操作推廣到多步操作。操作流程如下圖所示:
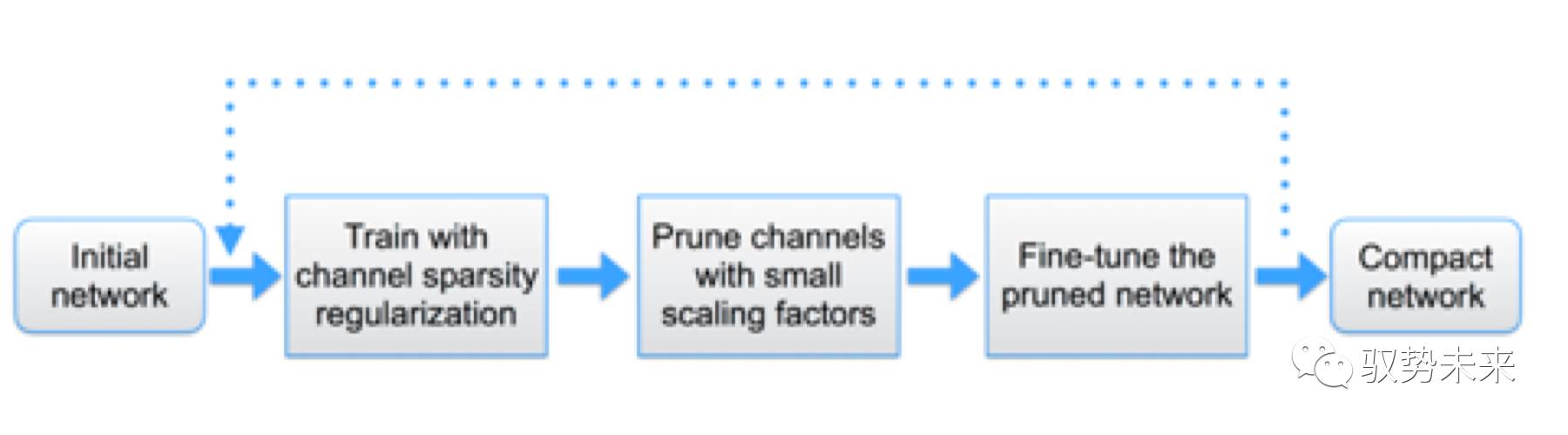
根據本文的實踐經驗發現multi-pass得到的結果往往會得到更高的壓縮比。
(4)對Cross Layer Connections 以及 Pre-activation 結構剪枝.
network slimming的方法可以被直接應用于VGGNet、AlexNet這樣的網絡結構,但是當需要把該方法應用于ResNet、DenseNet這樣的網絡結構時需要做其他的一些特殊設計。對于這樣的網絡,前一個網絡的輸出往往會被作為后面多個網絡模塊的輸入,這些網絡中 BN層的放置將被放置在Convolution層前。在這樣的網絡結構中,為了在inference時實現網絡參數以及網絡計算量的壓縮,需要在不重要的通道前放置一個channel-selection-layer來屏蔽不需要的channel。
結果分析
在Cifar10、Cifar100、SVHN上,本文采用了三種模型結構進行了測試分析。分別為VGGNet、ResNet164、DenseNet-40。在ImageNet數據集上,本文采用了VGGNet-A網絡進行了測試分析。下圖table 1為在Cifar數據集以及SVHN數據集上進行驗證的一些結果。
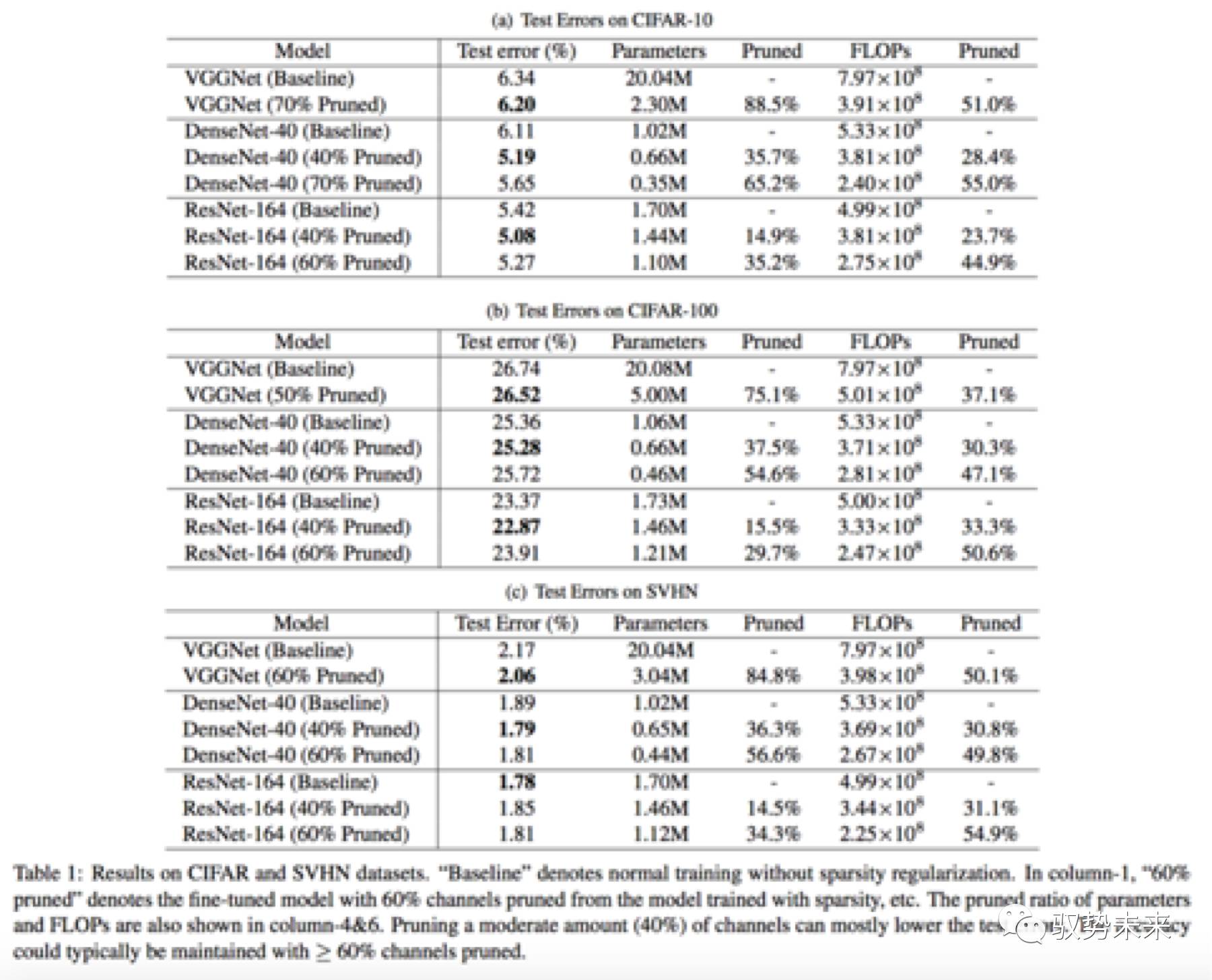
如上表table1所示,分別在Cifar10、Cifar100以及SVHN三個數據集進行了訓練測試,可以看到在這三個數據集中,每一個模型在進行了60%以上的channel-pruning以后,均能保持與原始模型幾乎一致的結果,甚至部分模型裁剪后的結果還有提升。
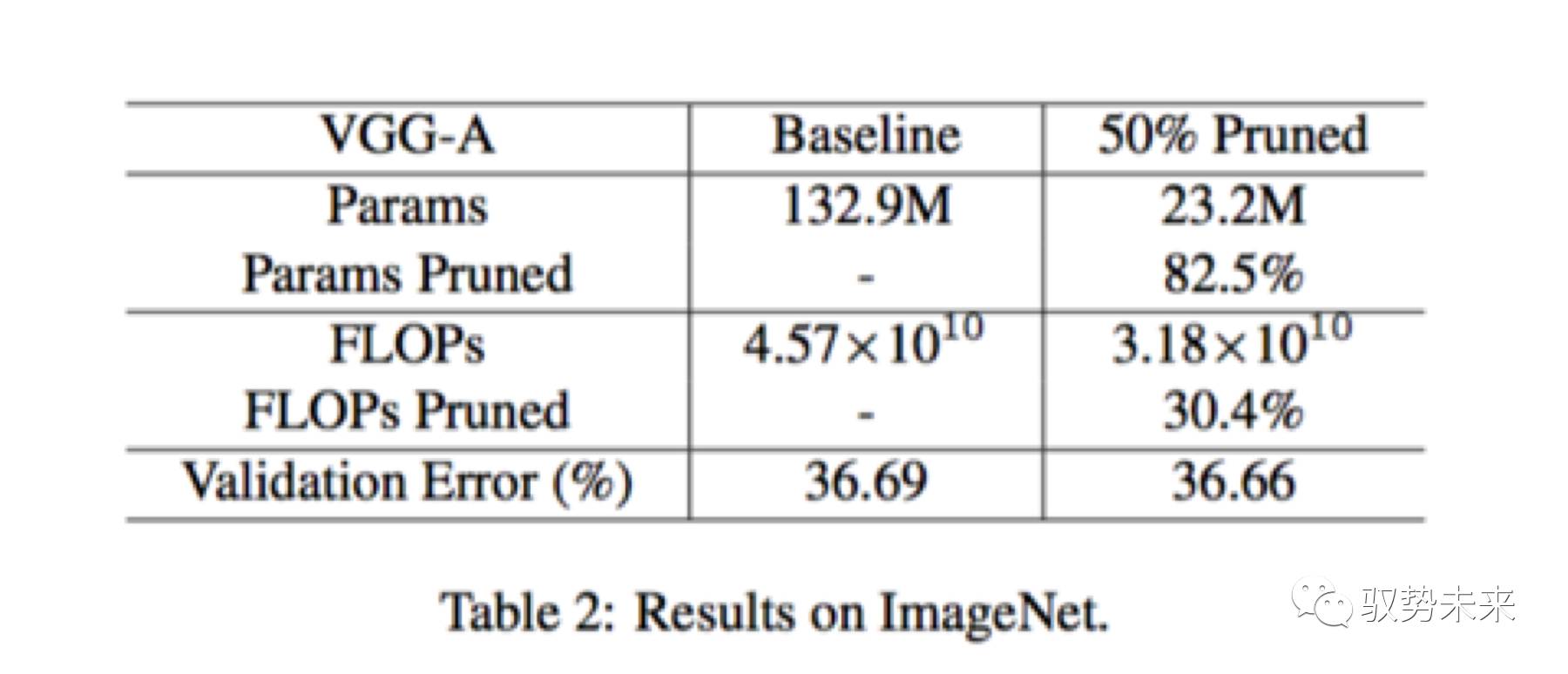
如下圖table2所示為VGGNet-A網絡在ImageNet上訓練測試的一個結果表。當采用了50%的通道裁剪以后,參數裁剪比例超過了5倍,但是Flops裁剪比例僅為30.4%,這是因為在卷積層中只有378個通道被裁剪掉了,而在全連接層中,有5094個通道被裁剪掉。
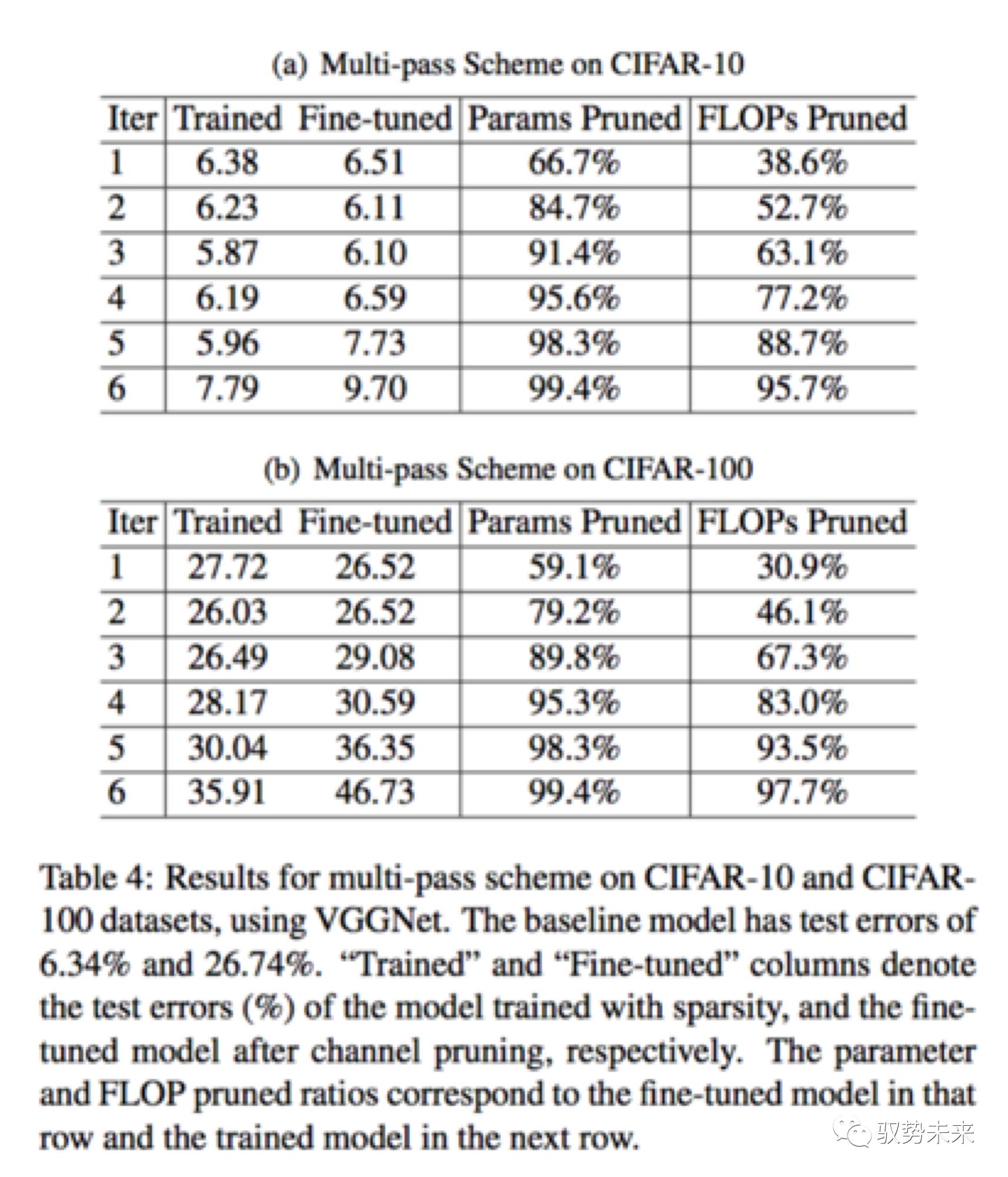
如下表table4, 展示了在VGGNet在Cifar10以及Cifar100上進行multi-pass裁剪的一個對比結果。如在Cifar10數據集上,隨著迭代次數的提升,裁剪比例越來越高,在iter 5的時候,得到了最低的test error。此時該模型達到了20x的參數減少和5x的計算量減少。而在Cifar100上,在iter3上,test error開始增加。這可能是因為在cifar100上,類別數目大于Cifar10,所以裁剪的太厲害會影響最終的結果,但是仍然實現了接近90%的參數減少以及接近70%的計算量下降。
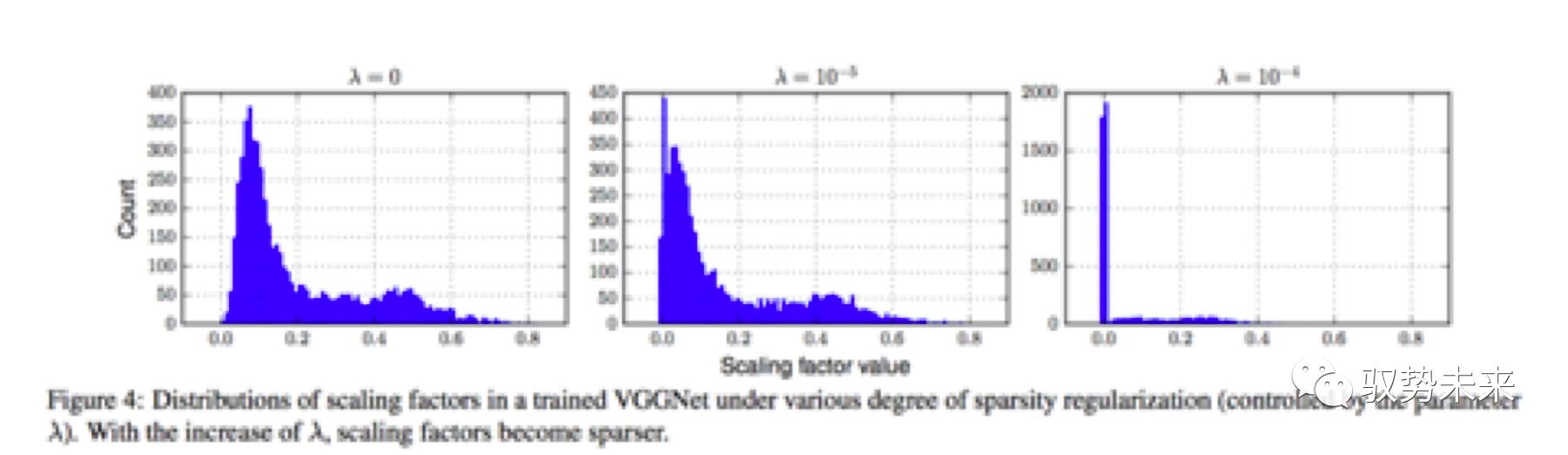
如下圖Figure 4為本文采用VGGNet在Cifar100上作稀疏化訓練一些對比實驗,可以發現隨著入的增大,模型通道權重的結果會越來越稀疏。
我們的一些實踐
由于公布的代碼是在torch框架下的代碼,因此,我們根據在Caffe上對上述結果進行了一次簡單的驗證。在驗證過程中采用了VGGNet-A網絡作為實驗網絡,并采用的Cifar10作為訓練數據集。
如下圖所示,左上為入=0,在iteration = 10000時的入參數分布圖,右上為入=0,iteration=45000的參數分布圖。左下為入=10e-4,iteration = 45000的參數統計圖,右下為入=10-3, iteration = 45000下的參數統計圖。[橫軸值除以100為參數實際區間]
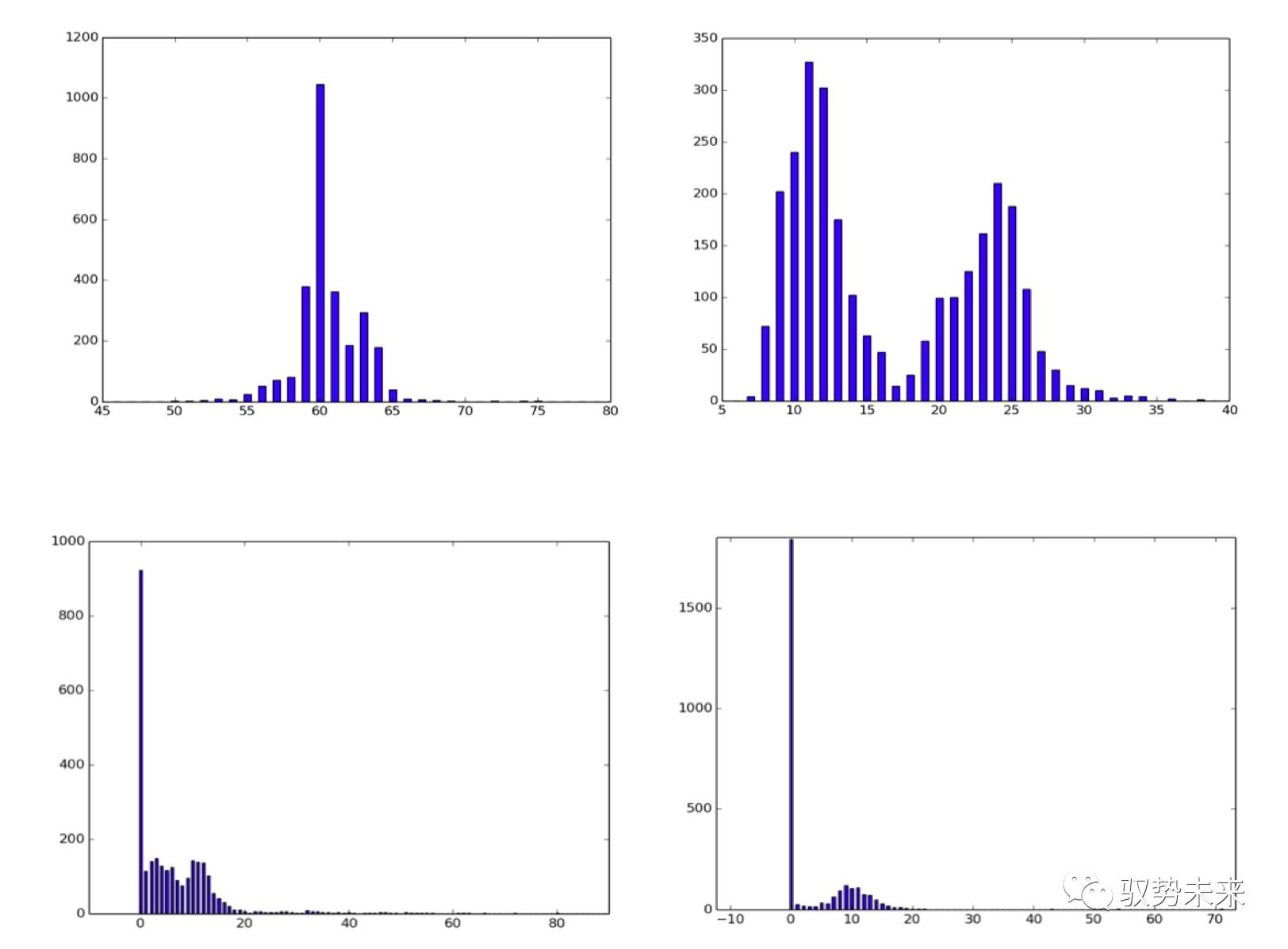
根據上面這一組圖我們發現如下幾點得到了驗證。
(1)隨著訓練次數的增加,入參數在正則項的影響下,逐步左移,重要的通道權值逐步凸顯,不重要的通道權值逐步抑制,與論文中Figure6的結論相符
(2)隨著入參數的增大,L1正則項的影響越來越大,參數越來越向0點靠攏,稀疏比例提高
(3)在增加L1正則項以后,實現了對通道的稀疏化但訓練的結果并沒有下降甚至反而有所提升,考慮在訓練過程中,“噪聲”通道由于L1正則項的引入被抑制,而真正的有效通道被凸顯。
因此,我們認為slimming的方法對于channel-wise的稀疏化是有效的。我們也采用同樣的參數在ImageNet數據集上進行了實驗,實驗發現效果并不如在cifar10數據集上那么好,雖然也有參數稀疏化的效果但是并不如cifar10上那么明顯,同時參數稀疏化后大部分主要分布在0.2附近,后續我們將進一步進行試驗。
總而言之,channel-slimming利用了BatchNorm Layer的特性巧妙的對通道重要性建模并最后實現通道的稀疏化還是非常值得學習的。
-
嵌入式
+關注
關注
5144文章
19592瀏覽量
316089 -
數據
+關注
關注
8文章
7250瀏覽量
91499 -
自動駕駛
+關注
關注
788文章
14259瀏覽量
170115
發布評論請先 登錄





 工商網監
工商網監
評論