 詳解語音識別的技術原理
詳解語音識別的技術原理

簡要給大家介紹一下語音怎么變文字的吧。需要說明的是,這篇文章為了易讀性而犧牲了嚴謹性,因此文中的很多表述實際上是不準確的。
首先,我們知道聲音實際上是一種波。常見的mp3等格式都是壓縮格式,必須轉成非壓縮的純波形文件來處理,比如Windows PCM文件,也就是俗稱的wav文件。wav文件里存儲的除了一個文件頭以外,就是聲音波形的一個個點了。下圖是一個波形的示例。
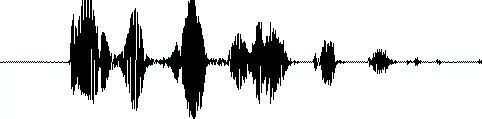
在開始語音識別之前,有時需要把首尾端的靜音切除,降低對后續步驟造成的干擾。這個靜音切除的操作一般稱為VAD,需要用到信號處理的一些技術。
要對聲音進行分析,需要對聲音分幀,也就是把聲音切開成一小段一小段,每小段稱為一幀。分幀操作一般不是簡單的切開,而是使用移動窗函數來實現,這里不詳述。幀與幀之間一般是有交疊的,就像下圖這樣:
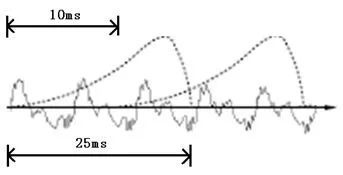
圖中,每幀的長度為25毫秒,每兩幀之間有25-10=15毫秒的交疊。我們稱為以幀長25ms、幀移10ms分幀。
分幀后,語音就變成了很多小段。但波形在時域上幾乎沒有描述能力,因此必須將波形作變換。常見的一種變換方法是提取MFCC特征,根據人耳的生理特性,把每一幀波形變成一個多維向量,可以簡單地理解為這個向量包含了這幀語音的內容信息。這個過程叫做聲學特征提取。實際應用中,這一步有很多細節,聲學特征也不止有MFCC這一種,具體這里不講。
至此,聲音就成了一個12行(假設聲學特征是12維)、N列的一個矩陣,稱之為觀察序列,這里N為總幀數。觀察序列如下圖所示,圖中,每一幀都用一個12維的向量表示,色塊的顏色深淺表示向量值的大小。
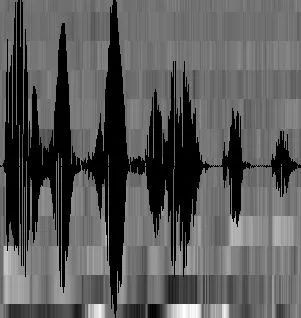
接下來就要介紹怎樣把這個矩陣變成文本了。首先要介紹兩個概念:
音素:單詞的發音由音素構成。對英語,一種常用的音素集是卡內基梅隆大學的一套由39個音素構成的音素集,參見The CMU Pronouncing Dictionary?。漢語一般直接用全部聲母和韻母作為音素集,另外漢語識別還分有調無調,不詳述。
狀態:這里理解成比音素更細致的語音單位就行啦。通常把一個音素劃分成3個狀態。
語音識別是怎么工作的呢?實際上一點都不神秘,無非是:
把幀識別成狀態(難點)。
把狀態組合成音素。
把音素組合成單詞。
如下圖所示:
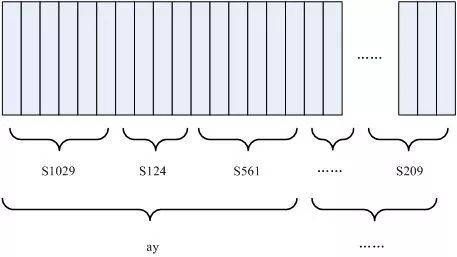
圖中,每個小豎條代表一幀,若干幀語音對應一個態,每三個狀態組合成一個音素,若干個音素組合成一個單詞。也就是說,只要知道每幀語音對應哪個狀態了,語音識別的結果也就出來了。
那每幀音素對應哪個狀態呢?有個容易想到的辦法,看某幀對應哪個狀態的概率最大,那這幀就屬于哪個狀態。比如下面的示意圖,這幀在狀態S3上的條件概率最大,因此就猜這幀屬于狀態S3。
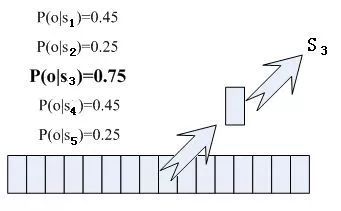
那這些用到的概率從哪里讀取呢?有個叫“聲學模型”的東西,里面存了一大堆參數,通過這些參數,就可以知道幀和狀態對應的概率。獲取這一大堆參數的方法叫做“訓練”,需要使用巨大數量的語音數據,訓練的方法比較繁瑣,這里不講。
但這樣做有一個問題:每一幀都會得到一個狀態號,最后整個語音就會得到一堆亂七八糟的狀態號。假設語音有1000幀,每幀對應1個狀態,每3個狀態組合成一個音素,那么大概會組合成300個音素,但這段語音其實根本沒有這么多音素。如果真這么做,得到的狀態號可能根本無法組合成音素。實際上,相鄰幀的狀態應該大多數都是相同的才合理,因為每幀很短。
解決這個問題的常用方法就是使用隱馬爾可夫模型(Hidden Markov Model,HMM)。這東西聽起來好像很高深的樣子,實際上用起來很簡單:
第一步,構建一個狀態網絡。
第二步,從狀態網絡中尋找與聲音最匹配的路徑。
這樣就把結果限制在預先設定的網絡中,避免了剛才說到的問題,當然也帶來一個局限,比如你設定的網絡里只包含了“今天晴天”和“今天下雨”兩個句子的狀態路徑,那么不管說些什么,識別出的結果必然是這兩個句子中的一句。
那如果想識別任意文本呢?把這個網絡搭得足夠大,包含任意文本的路徑就可以了。但這個網絡越大,想要達到比較好的識別準確率就越難。所以要根據實際任務的需求,合理選擇網絡大小和結構。
搭建狀態網絡,是由單詞級網絡展開成音素網絡,再展開成狀態網絡。語音識別過程其實就是在狀態網絡中搜索一條最佳路徑,語音對應這條路徑的概率最大,這稱之為“解碼”。路徑搜索的算法是一種動態規劃剪枝的算法,稱之為Viterbi算法,用于尋找全局最優路徑。
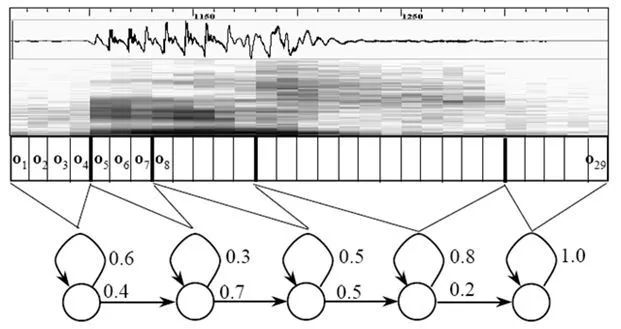
這里所說的累積概率,由三部分構成,分別是:
觀察概率:每幀和每個狀態對應的概率
轉移概率:每個狀態轉移到自身或轉移到下個狀態的概率
語言概率:根據語言統計規律得到的概率
其中,前兩種概率從聲學模型中獲取,最后一種概率從語言模型中獲取。語言模型是使用大量的文本訓練出來的,可以利用某門語言本身的統計規律來幫助提升識別正確率。語言模型很重要,如果不使用語言模型,當狀態網絡較大時,識別出的結果基本是一團亂麻。這樣基本上語音識別過程就完成了。
以上的文字只是想讓大家容易理解,并不追求嚴謹。
-
信號處理
+關注
關注
48文章
1056瀏覽量
104099 -
語音識別
+關注
關注
39文章
1780瀏覽量
114220
原文標題:詳解語音識別的技術原理:語音如何變為文字?
文章出處:【微信號:xiaojiaoyafpga,微信公眾號:電子森林】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
從“聽得見”到“聽得懂”:語音識別芯片的AI進化

廠家芯資訊|WTK6900系列語音識別芯片:精準交互,智創未來

語音識別技術在通信領域中的應用實例
詳解語音識別技術在通信領域中的應用

【「嵌入式系統設計與實現」閱讀體驗】+ 基于語音識別的智能杯墊
基于語音識別的智能會議系統具備哪些交互功能
語音識別技術的應用與發展
基于語音識別技術的智能家居控制系統

ASR語音識別技術應用







 工商網監
工商網監
評論