 電子發燒友App
電子發燒友App


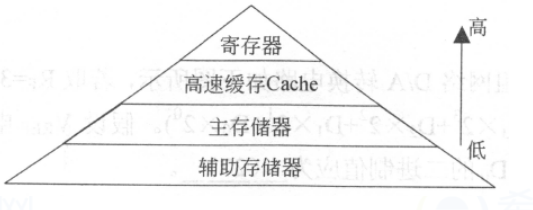
對于一個簡單的計算機系統模型,我們可以將存儲器系統看做是一個線性的字節數組,而 CPU 能夠在一個常數時間內訪問每個存儲器的位置。實際上,存儲器系統(memory system)是一個具有不同容量、成本和訪問時間的存儲設備的層次結構。CPU 寄存器保存著最常用的數據。
靠近 CPU 的小、快速的高速緩存存儲器(cache memory)做為一部分存儲在相對慢速的主存儲器(main memory)中數據和指令的緩沖區域。主存緩存存儲在容量較大的、慢速磁盤上的數據,而磁盤常常作為存儲在通過網絡連接的其他機器的磁盤的緩存。
Cache 基本模型
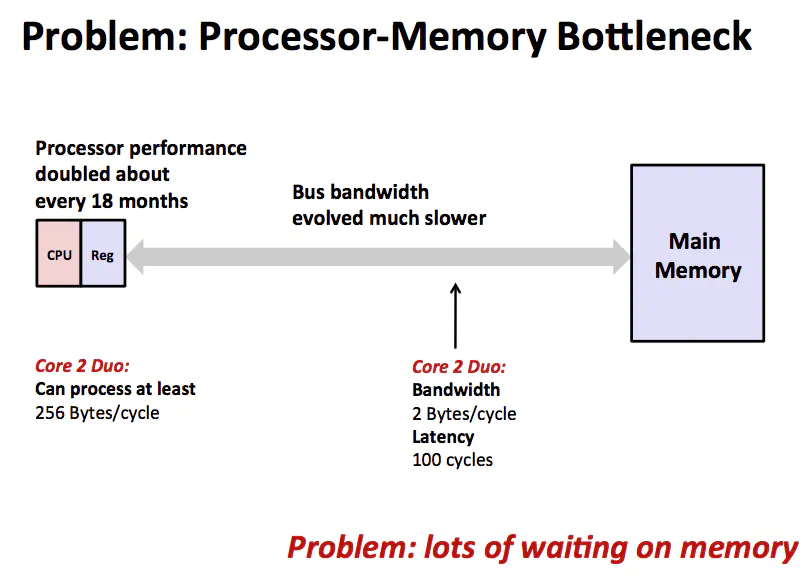
問題
CPU 通過總線從主存取指令和數據,完成計算之后再將結果寫回內存。這個模型的瓶頸在于 CPU 的超級快的運算速度和主存相對慢的多的運算速度無法匹配,導致大量的時間都浪費在內存上。既然內存比較慢那么就盡量減少 CPU 對內存的訪問,于是在 CPU 和 主存之間增加一層 Cache,如下圖所示。
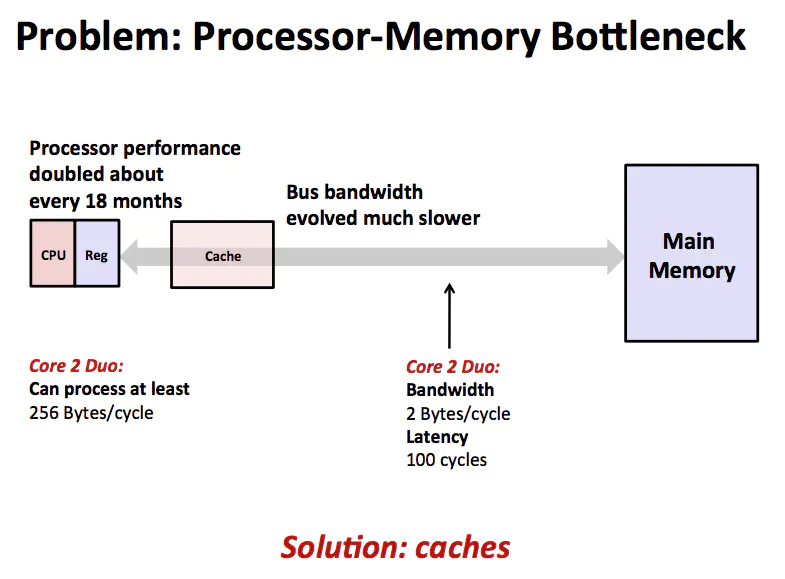
cache
在計算機中,Cache 就是訪問速度快的計算機內存被用來保存頻繁訪問或者最近訪問的指令和內存。通常 Cache 的造價比較高,所以相對 Memory 來說,容量比較小,保存的數據也有限。總而言之,由于 CPU 和內存之間的指令和數據訪問存在瓶頸,所以增加了一層 Cache,用來盡力消除 CPU 和內存之間的瓶頸。這個模型如下圖所示。
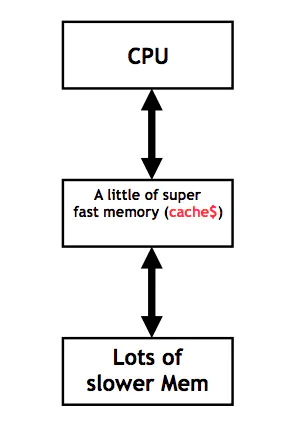
Cache 模型
局部性原理
你可能會問為什么在CPU 和內存之間增加一層 Cache,就可以盡力消除 CPU 和內存之間的瓶頸呢?
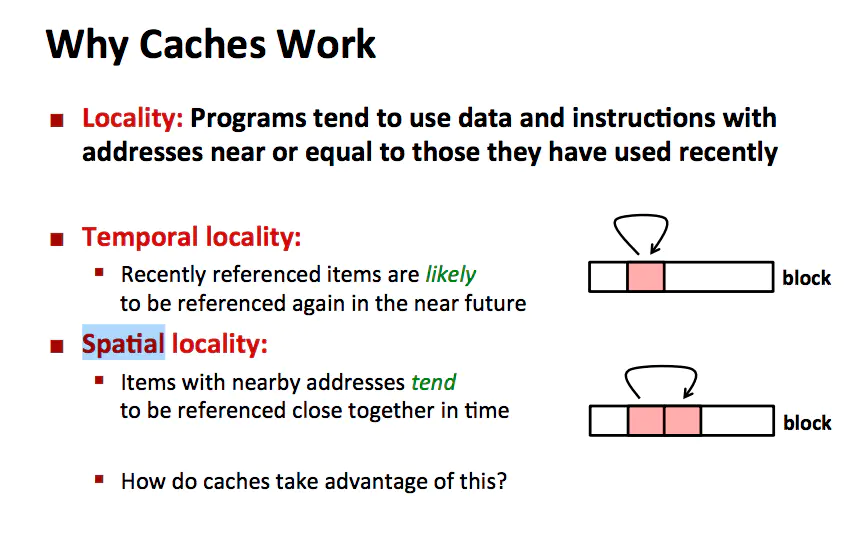
why cache work
如上圖所示,是局部性原理(principle of locality)讓 Cache 更好的工作。一個編寫良好的計算機程序通常都具有良好的局部性(locality),程序傾向于引用鄰近于其他最近引用過的數據項的數據項,或者最近引用過的數據項本身,這種傾向性被稱作局部性原理。
局部性通常有 2 種不同的形式:時間局部性(temporal locality)和空間局部性 (spatial locality)。在一個具有良好時間局部性的程序中,被引用過一次的內存地址很可能在不遠的將來會再被多次引用。在一個具有良好空間局部性的程序中,如果一個內存位置被引用了一次,那么程序很可能在不遠的將來會引用附近的一個內存位置。
程序是如何利用這個局部性原理呢?

Cache&locality
從數據方面來說,
sum 變量在每次循環迭代的時候都會被訪問,符合時間局部性。
采用步長為 1 的方式訪問數組 a ,符合空間局部性。
從指令方面來說,
循環迭代,符合時間局部性
線性執行指令,符合空間局部性
對于程序員來說,編寫具有良好的局部性的程序是讓程序運行更快的方法之一。
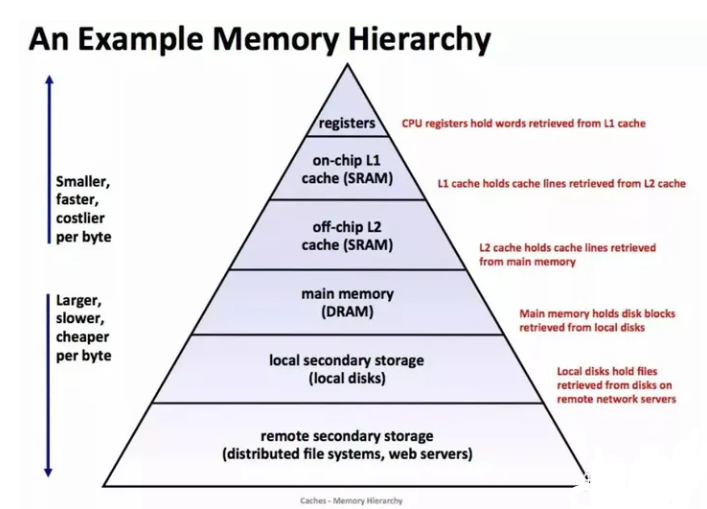
存儲器的層次結構
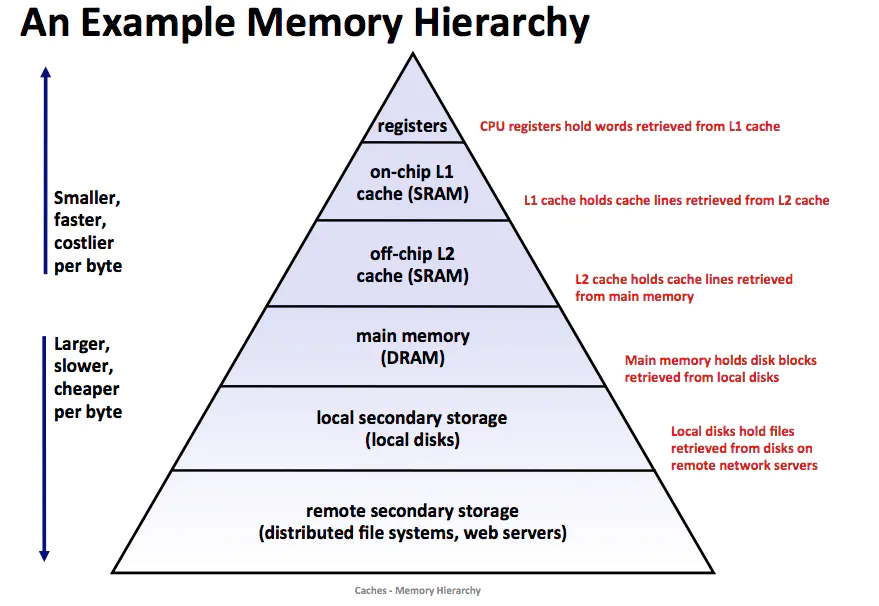
存儲器層次結構
上圖展示了一個典型的存儲器層次結構。一般而言,從高層往底層走,存儲設備變得更慢、更便宜和更大。在最高層是少量快速的CPU 寄存器,CPU 可以再一個時鐘周期內訪問它們。接下來是一個或者多個小型到中型的基于 SRAM 的高速緩存存儲器,可以再幾個 CPU 時鐘周期內訪問它們。
然后是一個大的基于 DRAM 的主存,可以在幾十或者幾百個時鐘周期內訪問它們。接下來是慢速但是容量很大的本地磁盤。最后有些系統甚至包括了一層附加的遠程服務器上的磁盤,要通過網絡來訪問它們,例如網絡文件系統(Network File System,NFS)這樣的分布式文件系統,允許程序訪問存儲在遠程的網絡服務器上的文件。
存儲器層次結構的核心是,對于每個 k , 位于 k 層的更快更小的存儲設備作為位于 k+1 層的更大更慢的存儲設備的緩存。也就是說,層次結構中的每一層都緩存來自較低一層的數據對象。例如,本地磁盤作為通過網絡從遠程磁盤取出文件的緩存,以此類推知道 CPU 寄存器。
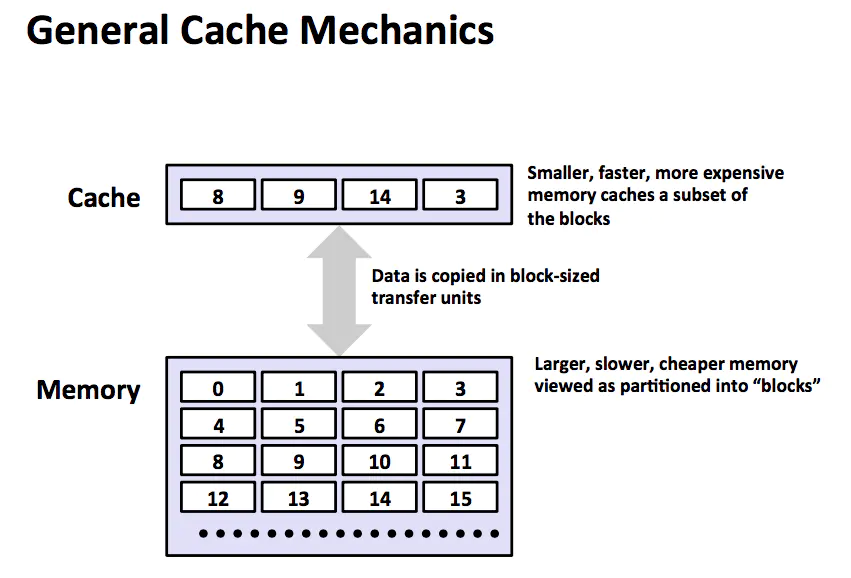
cache
上圖展示了存儲器層次結構中緩存的一般性概念。第 k+1 層的存儲器被劃分成連續的數據對象組塊(chunk),稱為塊(block)。每個塊都有一個唯一的名字或者地址以區別其他的塊。例如第 k+1 層存儲器被劃分成 16 個大小固定的塊,編號為 0 ~ 15。第 k 層的存儲器被劃分成較少的塊的集合,每個塊的大小與 k+1 層的塊的大小一樣。
在任何時刻,第 k 層的緩存包含了第 k+1 層塊的一個子集的副本。例如,第 k 層的緩存有 4 個塊的控件,當前包含了 8,9,14,3 的副本。
數據總是以塊大小為傳輸單元在第 k 層 和 第 k+1 層之間來回復制的,雖然在層次結構總任何一對相鄰的層次之間塊大小是固定的,但是其他的層次對之間可以有不同的塊大小。
例如 L1 和 L2 之間的傳送通常使用的是幾十個個字大小的塊,而 L5 和 L4 之間的傳送用的是大小為幾百或者幾千字節的塊。一般而言,層次結構中較低層(離 CPU 較遠)的設備的訪問時間較長,因此為了補償這些較長的訪問時間,傾向于使用較大的塊。
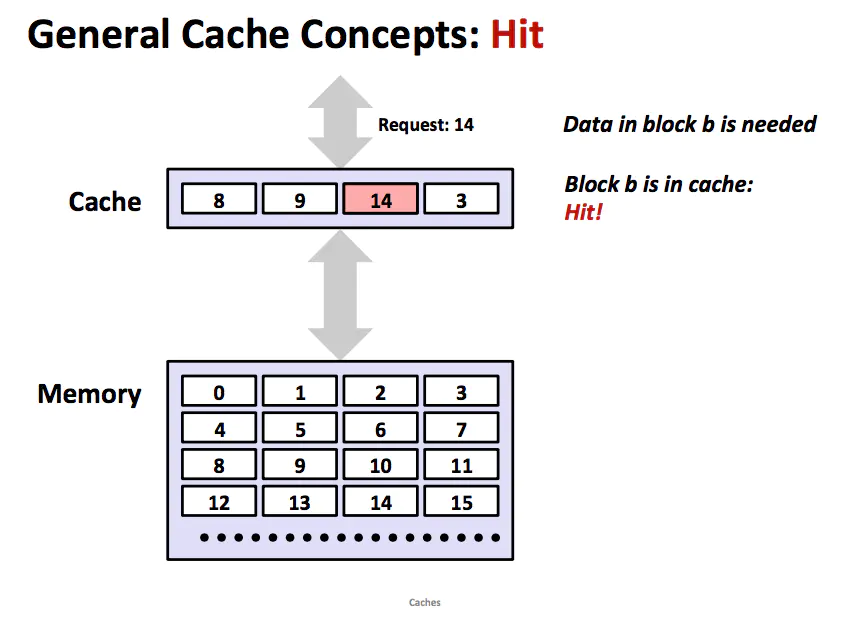
cache hit
當程序需要第 k+1 層的某個數據對象 d 時,它首先會在當前存儲在第 k 層的一個塊中查找 d。如果 d 剛好緩存在第 k 層,那么就是緩存命中。該程序直接從第 k 層讀取 d,根據存儲器層次結構的性質,從 k 層讀取數據顯然比從 k+1 層讀取數據更快。如上圖所示,一個具有良好時間局部性的程序可以從塊 14 中讀出一個數據對象,得到一個對 k 層的緩存命中 。
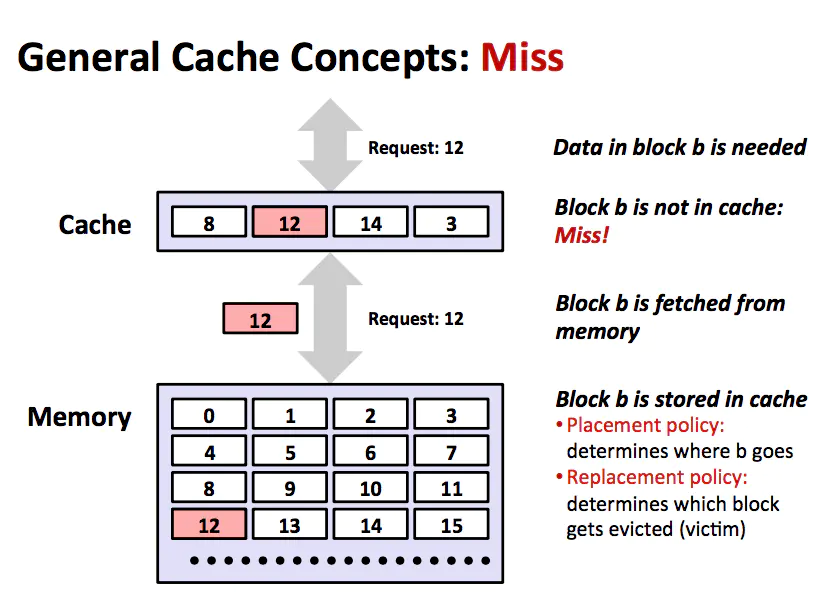
cache miss
如果第 k 層中沒有緩存數據對象 d,那么就是我們所說的緩存不命中 (cache miss)。當發生緩存不命中時,第 k 層的緩存從第 k+1 層緩存中取出包含 d 的那個塊,如果第 k 層的緩存已經滿了,那么可能會覆蓋現存的一個塊。覆蓋一個現存的一個塊的過程稱為替換或者驅逐。被替換的塊有時也稱作犧牲塊。決定替換哪個塊是由緩存的替換策略來控制的,替換策略有隨機替換和最近最少被使用(LRU)替換策略。
高速緩存存儲器
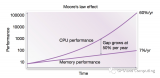
早期的計算機系統的存儲器結構只有三層:CPU 寄存器, DRAM 主存,磁盤。由于 CPU 和主存之間逐漸增大的速度差距,系統設計者在 CPU 和 主存之間插入了一個小的 SRAM 高速緩存存儲器,稱為 L1 高速緩存。隨著 CPU 和主存之間逐漸增大的速度差距,系統設計者在 L1 和 主存之間插入了一個更大的 SRAM 高速緩存存儲器,稱為 L2 高速緩存。
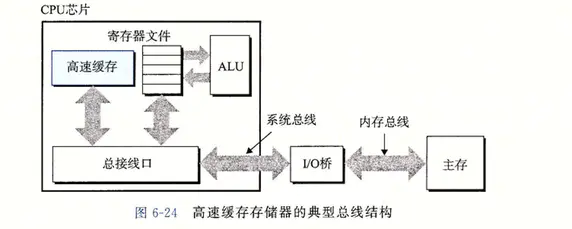
高速緩存存儲器的典型總線結構
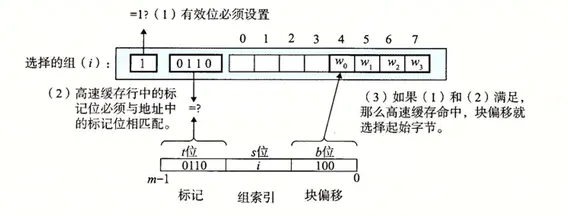
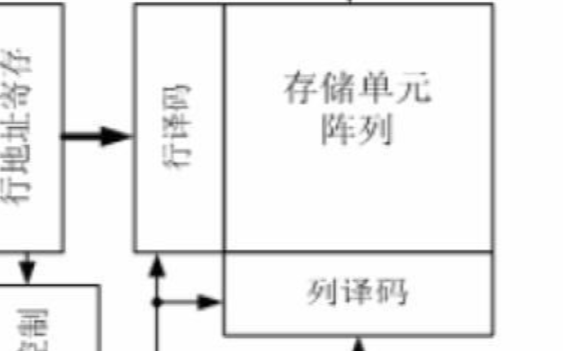
假設一個計算機系統,其中每個存儲器地址 m 位,形成 M = 2^m 個不同的地址。如下圖所示。一個機器的高速緩存被組織成一個有 S = 2^s 個高速緩存組(cache set)的數組。每個組包含 E 個高速緩存行(cache line),每個行由一個 B = 2^b 字節的數據塊組成,一個有效位(valid bit)指明這個行是否有效,t = m -(s+b)個標記位(tab bit),他們唯一地標識存儲在這個高速緩存行中的塊。
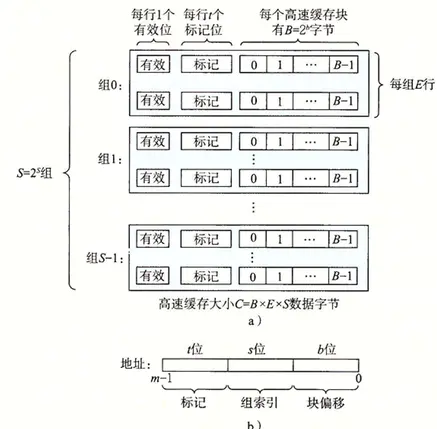
Cache Organization
根據每個組的高速緩存行數 E,高速緩存可以被分為不同的類,每個組只有一行(E = 1)的高速緩存成為直接映射高速緩存。下面我們以直接映射高速緩存來講解。
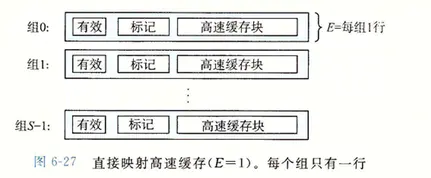
E=1
假設有這么一個系統,它有一個 CPU,一個寄存器文件,一個 L1 高速緩存和一個主存。當 CPU 執行一條讀內存字 w 的指令,它向 L1 請求這個字,如果 L1 有 w 的副本,那么 L1 高速緩存命中,高速緩存取出 w,返回給 CPU。
若是不命中,當 L1 向主存請求包含 w 的塊的副本時,CPU 必須等待。當被請求的塊從內存到達 L1 時,L1 將這個塊存放在它的一個高速緩存行里面,然后取出 w,返回給 CPU 。高速緩存上面的工作過程分為 3 個步驟:
組選擇
行匹配
字抽取
第一步,直接映射高速緩存的組選擇。高速緩存從 w 中取出 s 個組索引位。例子中的組索引位 00001 定位到組 1。
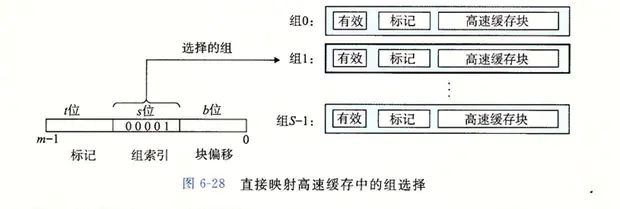
直接映射高速緩存的組選擇
第二步,直接映射高速緩存的行匹配。由于只有一個高速緩存行,而且有效位也設置了,所以這個行是有用的,從 w 中取出標記位 t ,與高速緩存行中的標記位相匹配,所以緩存命中。
直接映射高速緩存的行匹配
第三步,直接映射高速緩存的字選擇。一旦緩存命中,那么我們就知道 w 就在這個塊中的某個位置。我們把塊看成一個字節的數組,而字節偏移是到這個數組的索引。所以最后一步是確定所需要的字在塊中的偏移位置。例子中的塊偏移是 100,它說明了 w 的副本是從塊中的字節 4 開始的(假設字長為 4 字節)。
第四步,直接映射高速緩存不命中的行替換。如果緩存不命中,那么它需要從存儲器層次結構中的下一層取出被請求的塊,然后將新的塊存儲在一個高速緩存行中。對于直接映射高速緩存來說,每個組只要一個行,替換策略就是用新取出的行替換當前的行。
編寫高速緩存友好的代碼
確保代碼高速緩存友好的基本方法有 2 種,
讓最常見的情況運行的快。
盡量減少每個循環內部的緩存不命中數量。
int?sumvec(int?v[n])
{
??int?i,?sum?=?0;
??for?(i?=?0;?i?
首先對于局部變量 i 和 sum,循環體有良好的時間局部性。對數組 v 的步長為 1 的引用,對 v[0] 的引用會不命中,而對應的 v[0] ~ v[3] 的塊會被從內存加載到高速緩存中,因此接下來的三個引用都會命中,以此類推,四個引用中,三個會命中,這個是我們能做到的最好的情況了,具有良好的空間局部性。
總結
作為一個程序員需要理解存儲器的結構層次,因為它對應用程序的性能有巨大的影響。如果你的程序需要的數據是存儲在 CPU 寄存器中的,那么在指令的執行期間,在 0 個周期內就可以訪問到它們,如果在高速緩存中,需要 4 ~ 75 個周期。
如果存儲在主存中,需要上百個周期,如果存儲在磁盤上,大約需要幾千萬個周期。如果理解了系統是如何將數據再存儲器層次結構中上上下下移動的,那么就可以在編寫自己的應用程序的時候使得他們的數據項存儲在結構層次中較高的地方,以便 CPU 可以更快的訪問到它們。
編程時候可以注意以下幾點,讓程序性能更好!
1.重復引用同一個變量的程序有良好的時間局部性;
2.具有步調長度為k的引用模式程序,步調越小,空間局部性越好;
3.循環通常具有很好的空間局部性?&?時間局部性;
4.數組通常具有很好的空間局部性;
參考
本文是華盛頓大學的公開課 《 The Hardware / Software Interface 》的課程筆記,該課程的參考書籍是大名鼎鼎的 CSAPP 也就是《 深入理解計算機系統 》這書。文章截圖來源于課程,文章的內容也參考了 CSAPP 的書本內容。
審核編輯:黃飛
?














 工商網監
工商網監
評論