 電子發(fā)燒友App
電子發(fā)燒友App


大多數(shù)數(shù)據(jù)庫系統(tǒng)存儲一組數(shù)據(jù)記錄,這些記錄由表中的列和行組成。字段是列和行的交集:某種類型的單個值。
屬于同一列的字段通常具有相同的數(shù)據(jù)類型。例如,如果我們定義了一個包含用戶數(shù)據(jù)的表,那么所有的用戶名都將是相同的類型,并且屬于同一列。在邏輯上屬于同一數(shù)據(jù)記錄(通常由鍵標識)的值的集合構成一行。
對數(shù)據(jù)庫進行分類的方法之一是按數(shù)據(jù)在磁盤上的存儲方式進行分類:按行或按列進行分類。表可以水平分區(qū)(將屬于同一行的值存儲在一起),也可以垂直分區(qū)(將屬于同一列的值存儲在一起)。圖1-2描述了這種區(qū)別:a)顯示了按列分區(qū)的值,b)顯示了按行分區(qū)的值。
▲圖1-2:面向列和行的存儲中的數(shù)據(jù)布局面向行的數(shù)據(jù)庫的例子很多:MySQL、PostgreSQL和大多數(shù)傳統(tǒng)的關系數(shù)據(jù)庫。而兩個開源的、面向列數(shù)據(jù)存儲的先驅(qū)則是MonetDB和C-Store(C-Store是Vertica的開源前身)。
01 面向行的數(shù)據(jù)布局
面向行的數(shù)據(jù)庫按記錄或行來存儲數(shù)據(jù)。它的布局非常接近表格的數(shù)據(jù)表示方法,即其中每一行都具有相同的字段集合。例如,面向行的數(shù)據(jù)庫可以有效地存儲用戶條目,其中包含姓名、出生日期和電話號碼:
| ID | Name | Birth Date | Phone Number |
| 10 | John | 01 Aug 1981 | +1 111 222 333 |
| 20 | Sam | 14 Sep 1988 | +1 555 888 999 |
| 30 | Keith | 07 Jan 1984 | +1 333 444 555 |
這種方法適用于如下的場景:數(shù)據(jù)記錄(姓名、出生日期和電話號碼)由多個字段組成且由某個鍵(在本例中為單調(diào)遞增的ID)所唯一標識。表示單個用戶的數(shù)據(jù)記錄的所有字段通常被一起讀取。在創(chuàng)建數(shù)據(jù)時(例如,當用戶填寫注冊表單時),我們也將它們一起寫入數(shù)據(jù)庫。與此同時,我們可以單獨修改某個字段。
在需要按行訪問數(shù)據(jù)的情況下,面向行的存儲最有用,將整行存儲在一起可以提高空間局部性。
因為諸如磁盤之類的持久性介質(zhì)上的數(shù)據(jù)通常是按塊訪問的(換句話說,磁盤訪問的最小單位是塊),所以單個塊可能將包含某行中所有列的數(shù)據(jù)。
這對于我們希望訪問整個用戶記錄的情況非常有用,但這樣的存儲布局會使訪問多個用戶記錄某個字段的查詢(例如,只獲取電話號碼的查詢)開銷更大,因為其他字段的數(shù)據(jù)在這個過程中也會被讀入。
02 面向列的數(shù)據(jù)布局
面向列的數(shù)據(jù)庫垂直地將數(shù)據(jù)進行分區(qū)(即通過列進行分區(qū)),而不是將其按行存儲。在這種數(shù)據(jù)存儲布局中,同一列的值被連續(xù)地存儲在磁盤上(而不是像前面的示例那樣將行連續(xù)地存儲)。
例如,如果我們要存儲股票市場的歷史價格,那么股票價格這一列的數(shù)據(jù)便會被存儲在一起。將不同列的值存儲在不同的文件或文件段中,可以按列進行有效的查詢,因為它們可以一次性地被讀取出來,而不是先對整行進行讀取后再丟棄掉不需要的列。
面向列的存儲非常適合計算聚合的分析型工作負載,例如查找趨勢、計算平均值等。如果邏輯記錄具有多個字段,但是其中某些字段(在本例中為股票價格)具有不同的重要性并且該字段所存儲的數(shù)據(jù)經(jīng)常被一起使用,那么我們一般使用復雜聚合來處理這樣的情況。
從邏輯角度看,表示股票市場價格的數(shù)據(jù)仍舊可以表示為表的形式:
| ID | Symbol | Date | Price |
| 1 | DOW | 08 Aug 2018 | 24,314.65 |
| 2 | DOW | 09 Aug 2018 | 24,136.16 |
| 3 | S&P | 08 Aug 2018 | 2,414.45 |
| 4 | S&P | 09 Aug 2018 | 2,232.32 |
而列式存儲則看起來與上述存儲布局完全不同—屬于同一列的值被緊密地存儲在一起:
Symbol: 1:DOW; 2:DOW; 3:S&P; 4:S&P
Date: 1:08 Aug 2018; 2:09 Aug 2018; 3:08 Aug 2018; 4:09 Aug 2018
Price: 1:24,314.65; 2:24,136.16; 3:2,414.45; 4:2,232.32
為了重建數(shù)據(jù)元組(這對于連接、篩選和多行聚合可能很有用),我們需要在列級別上保留一些元數(shù)據(jù),以標識與它關聯(lián)的其他列中的數(shù)據(jù)點是哪些。如果你顯式地執(zhí)行此操作,則需要每個值都必須持有一個鍵,這將導致數(shù)據(jù)重復并增加存儲的數(shù)據(jù)量。
針對這種需求,一些列存儲使用隱式標識符(虛擬ID),并使用該值的位置(換句話說,其偏移量)將其映射回相關值。
在過去幾年中,可能由于對不斷增長的數(shù)據(jù)集運行復雜分析查詢的需求不斷增長,我們看到了許多新的面向列的文件格式,如Apache Parquet、Apache ORC、RCFile,以及面向列的存儲,如Apache Kudu、ClickHouse,以及許多其他列式數(shù)據(jù)存儲組件。
03 區(qū)別與優(yōu)化
認為行存儲和列存儲之間的區(qū)別僅在于數(shù)據(jù)的存儲方式有所不同,這是不充分的。選擇數(shù)據(jù)布局只是列式存儲所針對的一系列可能的優(yōu)化的步驟之一。
在一次讀取中,從同一列中讀取多個值可以顯著提高緩存利用率和計算效率。在現(xiàn)代CPU上,向量化指令可以使單條CPU指令一次處理多個數(shù)據(jù)點。
另外,將具有相同數(shù)據(jù)類型的值存儲在一起(例如,數(shù)字與數(shù)字在一起,字符串與字符串在一起)可以提高壓縮率。我們可以根據(jù)不同的數(shù)據(jù)類型使用不同的壓縮算法,并為每種情況選擇最有效的壓縮方法。
要決定是使用面向列還是面向行的存儲,你需要了解訪問模式。如果所讀取的記錄中的大多數(shù)或所有列都是需要的,并且工作負載主要由單條記錄查詢和范圍掃描組成,則面向行的存儲布局可能產(chǎn)生更好的結果。如果掃描跨越多行,或者在列的子集上進行計算聚合,則值得考慮使用面向列的存儲布局。
04 寬列式存儲
面向列的數(shù)據(jù)庫不應與寬列式存儲(如BigTable或HBase)相混淆。在這些數(shù)據(jù)庫中,數(shù)據(jù)表示為多維映射,列被分組為列族(通常存儲相同類型的數(shù)據(jù)),并且在每個列族中,數(shù)據(jù)被逐行存儲。此布局最適合存儲由一個鍵或一組鍵來檢索的數(shù)據(jù)。
BigTable論文中的一個典型示例是WebTable。一個WebTable存儲著一個帶有某個時間戳、包含如下信息的快照:網(wǎng)頁內(nèi)容、屬性以及它們之間的關系。
頁面由反向URL所標識,并且所有屬性(如頁面內(nèi)容和錨,錨表示頁面之間的鏈接)由生成這些快照的時間戳來標識。簡而言之,它可以表示為一個嵌套的映射,如圖1-3所示。

▲圖1-3:WebTable的概念性結構數(shù)據(jù)存儲在具有層次索引的多維排序映射中:我們可以通過特定網(wǎng)頁的反向URL來定位與該網(wǎng)頁相關的數(shù)據(jù),也可以通過時間戳來定位該網(wǎng)頁的內(nèi)容或錨。每一行都按其行鍵進行索引。
在列族中,相關列被分組在一起(在本例中為contents和anchor),這些列族分別存儲在磁盤上。列族中的每個列都由列鍵標識,該鍵是列族名稱和限定符(在本例中為html,cnnsi.com,my.look.ca)的組合。
列族可以按照時間戳存儲多個版本的數(shù)據(jù)。這種布局使得我們可以快速定位更高層的條目(在本例中為Web頁面)及其參數(shù)(不同版本的內(nèi)容和指向其他頁面的鏈接)。
理解寬列式存儲的概念表示是有用的,而它們的物理布局也有所不同。列族的數(shù)據(jù)布局示意圖如圖1-4所示:列族被單獨存儲,但在每個列族中,屬于同一鍵的數(shù)據(jù)被存儲在一起。
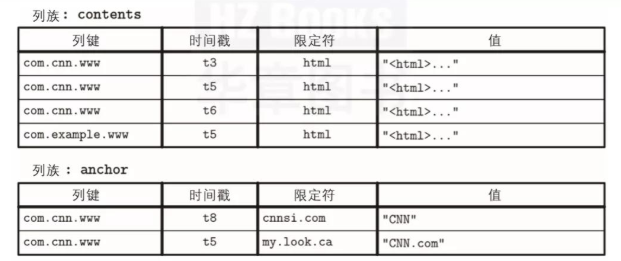
▲圖1-4:WebTable的物理結構








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論