基于GPU的RBM并行加速方法
大小:0.94 MB 人氣: 2017-11-07 需要積分:0
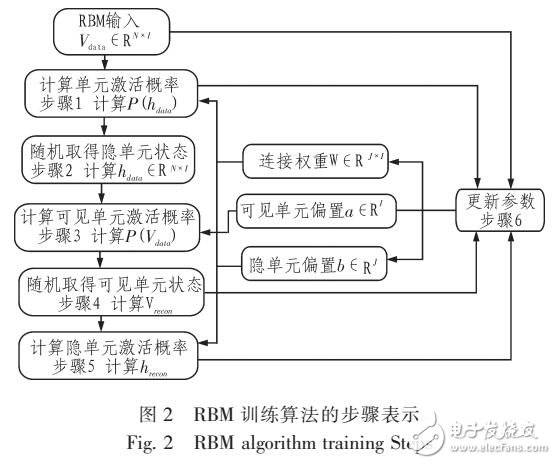
為針對受限玻爾茲曼機處理大數(shù)據時存在的訓練緩慢、難以得到模型最優(yōu)的問題,提出了基于CJPU的RBM模型訓練并行加速方法。首先重新規(guī)劃了對比散度算法在C‘JPU的實現(xiàn)步驟;其次結合以往C’JPU并行方案,提出采用CUBLAS執(zhí)行訓練的矩陣乘加運算,設計周期更長、代碼更為簡潔的Tausworthe113和CLCC4的組合隨機數(shù)生成器,利用CUDA拾取紋理內存的讀取模式實現(xiàn)了Sigmoid函數(shù)值計算;最后對訓練時間和效果進行檢驗。通過MNIST手寫數(shù)字識別集實驗證明,相較于以往RBM并行代碼,新設計的CJPU并行方案在處理大規(guī)模數(shù)據集訓練上優(yōu)勢較為明顯,加速比達到25以上。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
基于GPU的RBM并行加速方法下載
相關電子資料下載
- 天數(shù)智芯亮相2024世界人工智能大會 310
- 擁抱多元化,Imagination迎來新機遇 102
- 英偉達H200芯片將大規(guī)模交付 214
- 浪潮信息推出AIGC存儲解決方案 254
- 如何使用PyTorch構建更高效的人工智能 75
- NVIDIA Grace Hopper超級芯片支持金融平臺Murex MX.3 393
- ai服務器和通用服務器的區(qū)別在哪 113
- AMD Radeon PRO W7900雙槽工作站顯卡發(fā)布上市 290
- 摩爾線程全功能GPU加速三維GIS全國產解決方案 595
- NVIDIA加速計算和 AI助力數(shù)字銀行揭穿金融欺詐騙局 460