在Spark Streaming中實(shí)現(xiàn)快速狀態(tài)流處理
大小:0.5 MB 人氣: 2017-10-12 需要積分:1
推薦 + 挑錯(cuò) + 收藏(0) + 用戶評(píng)論(0)
標(biāo)簽:狀態(tài)流處理(1487)sparkstreaming(1879)
許多復(fù)雜流處理流水線程序必須將狀態(tài)保持一段時(shí)間,例如,如果你想實(shí)時(shí)了解網(wǎng)站用戶行為,你需要將網(wǎng)站上各“用戶會(huì)話(user session)”信息保存為持久狀態(tài)并根據(jù)用戶的行為對(duì)這一狀態(tài)進(jìn)行持續(xù)更新。這種有狀態(tài)的流計(jì)算可以在Spark Streaming中使用updateStateByKey 方法實(shí)現(xiàn)。在Spark 1.6 中,我們通過使用新API mapWithState極大地增強(qiáng)對(duì)狀態(tài)流處理的支持。該新的API提供了通用模式的內(nèi)置支持,而在以前使用updateStateByKey 方法來實(shí)現(xiàn)這一相同功能(如會(huì)話超時(shí))需要進(jìn)行手動(dòng)編碼和優(yōu)化。因此,mapWithState 方法較之于updateStateByKey方法,有十倍之多的性能提升。在本博文當(dāng)中,我們將對(duì)mapWithState方法進(jìn)行深入講解,同時(shí)提前感受后續(xù)新版本中將加入的特性。
使用mapWithState方法進(jìn)行狀態(tài)流處理
Spark Streaming中最強(qiáng)大的特性之一是簡(jiǎn)單的狀態(tài)流處理API及相關(guān)聯(lián)的本地化、可容錯(cuò)的狀態(tài)管理能力。開發(fā)人員僅需要指定狀態(tài)的結(jié)構(gòu)和更新邏輯,Spark Streaming便能夠接管集群中狀態(tài)的分發(fā)、管理,在程序出錯(cuò)時(shí)自動(dòng)進(jìn)行恢復(fù)并提供端到端的容錯(cuò)保障。盡管現(xiàn)有DStream中updateStateByKey方法能夠允許用戶執(zhí)行狀態(tài)計(jì)算,但使用mapWithState方法能夠讓用戶更容易地表達(dá)程序邏輯,同時(shí)讓性能提升10倍之多。讓我們通過一個(gè)例子對(duì)mapWithState方法的優(yōu)勢(shì)進(jìn)行闡述。
假設(shè)我們要根據(jù)用戶歷史動(dòng)作對(duì)某一網(wǎng)站的用戶行為進(jìn)行實(shí)時(shí)分析,對(duì)各個(gè)用戶,我們需要保持用戶動(dòng)作的歷史信息,然后根據(jù)這些歷史信息得到用戶的行為模型并輸出到下游的數(shù)據(jù)存儲(chǔ)當(dāng)中。
在Spark Streaming中構(gòu)建此應(yīng)用程序時(shí),我們首先需要獲取用戶動(dòng)作流作為輸入(例如通過Kafka或Kinesis),然后使用mapWithState 方法對(duì)輸入進(jìn)行轉(zhuǎn)換操作以生成用戶模型流,最后將處理后的數(shù)據(jù)流保存到數(shù)據(jù)存儲(chǔ)當(dāng)中。
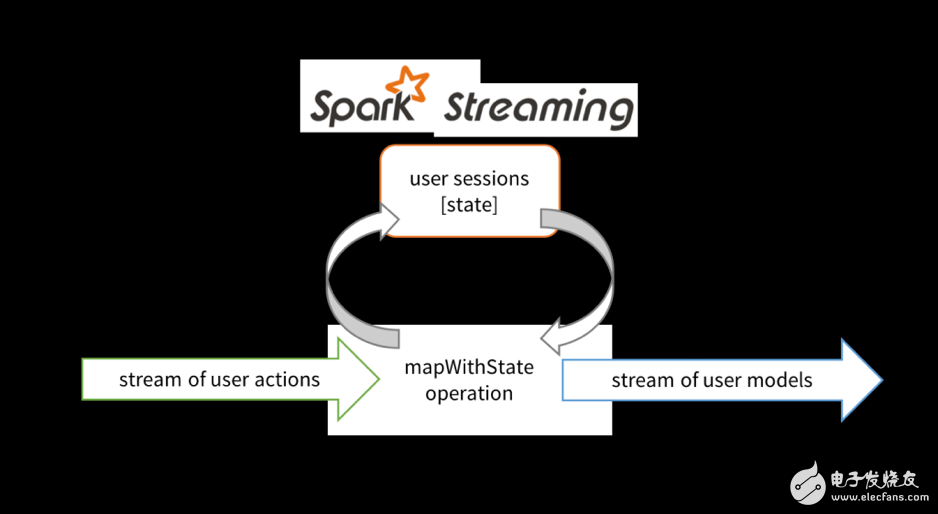
在Spark Streaming中使用狀態(tài)流處理進(jìn)行用戶會(huì)話維護(hù)
mapWithState方法可以通過下面的抽象方式進(jìn)行理解,假設(shè)它是將用戶動(dòng)作和當(dāng)前用戶會(huì)話作為輸入的一個(gè)算子(operator),基于某個(gè)輸入動(dòng)作,該算子能夠有選擇地更新用戶會(huì)話,然后輸出更新后的用戶模型作為下游操作的輸入。開發(fā)人員在定義mapWithState方法時(shí)可以指定該更新函數(shù)。
現(xiàn)在讓我們轉(zhuǎn)入到具體代碼來說明,首先我們定義狀態(tài)數(shù)據(jù)結(jié)構(gòu)及狀態(tài)更新函數(shù):
def stateUpdateFunction( userId: UserId, newData: UserAction, stateData: State[UserSession]): UserModel = { val currentSession = stateData.get()// 獲取當(dāng)前會(huì)話數(shù)據(jù) val updatedSession = 。..// 使用newData計(jì)算更新后的會(huì)話 stateData.update(updatedSession) // 更新會(huì)話數(shù)據(jù) val userModel = 。..// 使用updatedSession計(jì)算模型 returnuserModel // 將模型發(fā)送給下游操作 }
然后,在用戶動(dòng)作DStream上定義mapWithState 方法,通過創(chuàng)建StateSpec對(duì)象來實(shí)現(xiàn),該對(duì)象中包含所有前述指定的操作。
// 用去動(dòng)作構(gòu)成的Stream,用戶ID作為key val userActions = 。..// key-value元組(UserId, UserAction)構(gòu)成的stream // 待提交的數(shù)據(jù)流 val userModels = userActions.mapWithState(StateSpec.function(stateUpdateFunction))
mapWithState的新特性和性能改進(jìn)
通過前面的例子,我們已經(jīng)明白其使用方式,現(xiàn)在讓我們?cè)偕钊肜斫馐褂迷撔碌腁PI所帶來的特定優(yōu)勢(shì)。
1. 原生支持會(huì)話超時(shí)
許多基于會(huì)話的應(yīng)用程序要求具備超時(shí)機(jī)制,當(dāng)某個(gè)會(huì)話在一定的時(shí)間內(nèi)(如用戶沒有顯式地注銷而結(jié)束會(huì)話)沒有接收到新數(shù)據(jù)時(shí)就應(yīng)該將其關(guān)閉,與使用updateStateByKey方法時(shí)需要手動(dòng)進(jìn)行編碼實(shí)現(xiàn)所不同的是,開發(fā)人員可以通過mapWithState方法直接指定其超時(shí)時(shí)間。
userActions.mapWithState(StateSpec.function(stateUpdateFunction).timeout(Minutes(10)))
除超時(shí)機(jī)制外,開發(fā)人員也可以設(shè)置程序啟動(dòng)時(shí)的分區(qū)模式和初始狀態(tài)信息。
2. 任意數(shù)據(jù)都能夠發(fā)送到下游
與updateStateByKey方法不同,任意數(shù)據(jù)都可以通過狀態(tài)更新函數(shù)將數(shù)據(jù)發(fā)送到下游操作,這一點(diǎn)已經(jīng)在前面的例子中有說明(例如通過用戶會(huì)話狀態(tài)返回用戶模型),此外,最新狀態(tài)的快照也能夠被訪問。
val userSessionSnapshots = userActions.mapWithState(statSpec).snapshotStream()
變量userSessionSnapshots 為一個(gè)DStream,其中各個(gè)RDD為各批(batch)數(shù)據(jù)處理后狀態(tài)更新會(huì)話的快照,該DStream與updateStateByKey方法返回的DStream是等同的。
3. 更高的性能
最后,與updateStateByKey方法相比,使用mapWithState方法能夠得到6倍的低延遲同時(shí)維護(hù)的key狀態(tài)數(shù)量要多10倍,這一性能提升和擴(kuò)展性可從后面的基準(zhǔn)測(cè)試結(jié)果得到驗(yàn)證,所有的結(jié)果全部在時(shí)間間隔為1秒的batch和相同大小的集群中生成。
下圖比較的是mapWithState 方法和updateStateByKey 方法處理1秒的batch所消耗的平均時(shí)間,在本例中,我們?yōu)橥瑯訑?shù)量(從0.25~1百萬)的key保存其狀態(tài),然后以同樣的速率(30k個(gè)更新/s)對(duì)其進(jìn)行更新,如下圖所示,mapWithState方法比updateStateByKey方法的處理時(shí)間快8倍,從而允許更低的端到端延遲。
非常好我支持^.^
(0) 0%
不好我反對(duì)
(0) 0%