人工智能作詩機器人
作詩機器人作為一個玩具也好一個科學研究的領域課題也罷,很早就有人開始研究了。就但從數學模型角度來說,作詩姬應該屬于隱馬爾可夫模型的變種。
所謂隱馬爾可夫模型HMM就是從時間序列的隨機事件中去統計前后狀態的轉化概率。這種模型在NLP領域應用是非常廣泛的,在作詩姬這種玩具中也少不了它拋頭露面。
遇到這種命題,首先應該想到的是使用RNN模型(LSTM)來進行訓練。因為RNN具有一種天生就最適合擬合隱馬爾可夫模型的構造,所以這個大的思路應該是沒有什么問題的。可是,中文有中文的特點,而且中文當中有一些令我們中國人最自豪的,最優美的韻律感,同時也是我們自己在嘗試寫詩的過程中最不好把握的東西——平仄和韻腳。隱馬爾可夫模型可以統計出來在一個字后面出現另一個字是多大概率,而且可以有一定自由度地選擇其中的一個字作為下一個接續字——可以選擇概率最大的那個字,這種情況下一旦第一個字確定后,后面整個詩文理論上就是全部確定的;也可以按照概率從大到小排列,用概率的比例去生成一個 “不均勻的骰子”,使得下一個字的產生有一定變化。

用隱馬爾可夫模型生成字的時候,選擇概率較大的字出現的目的是為了讓語句更為通暢,因為兩個字有較大概率緊鄰出現的話大多是因為它們是一個詞,或者在單字詞盛行的古詩文中至少是詞組或者常用短語。例如“紅顏”、“春光”、“山河”、“相送”等。而概率小的鄰接字含義很可能表示的是這兩個字從來沒有前后腳出現過,或者偶爾出現過那么一兩次還是一個屬于前面的詞尾一個屬于后面的詞頭的情況,那如果采用的話自然是狗屁不通。
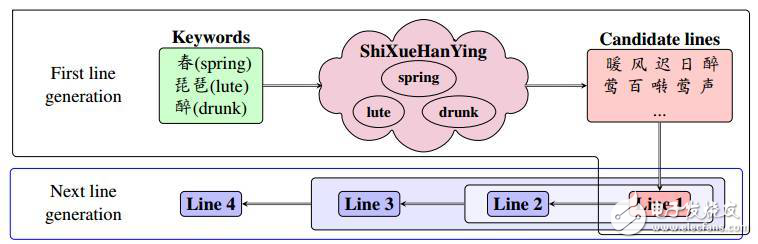
光是用隱馬爾可夫模型去統計還是不夠的,要生成一個有一定“含義”的詩文是需要有一定的意境和慣用詞匯的。為此,有這樣一本書作為辭典備用,叫做《詩學含英》,不過別找了京東上沒有,這么偏門小眾的書求助萬能的淘寶吧。由于在五絕和七絕這樣的詩律中是講究押韻和平仄工整的,所以第二三四句實際上是根據第一句來生成的,它們的生成要在規則上與第一句呼應。那么就要先重點生成第一句,再一句一句按照規則去生成其余的句子。

非常好我支持^.^
(0) 0%
不好我反對
(0) 0%