 電子發(fā)燒友App
電子發(fā)燒友App


分布式系統(tǒng)是實現高可伸縮性,局部性和可用性的基本概念。然而,另一方面,當從客戶端查看時,整個系統(tǒng)需要很多獨創(chuàng)性才能看起來一致。另外,據說構建具有完整特征的分布式系統(tǒng)幾乎是不可能的,并且有必要選擇應用程序應該強調哪些性能。
除了描述這些分布式系統(tǒng)的特性外,我們還描述了具有高性能的區(qū)塊鏈的特性。最后,通過總結容錯屬性,我們將進一步探索區(qū)塊鏈的更大潛力,并希望通過討論每個高級區(qū)塊鏈項目(如Tendermint)全面解釋MOLD應該瞄準的系統(tǒng)。
1. 簡介(容錯概述以及總體流程)
與單個系統(tǒng)不同,分布式系統(tǒng)存在部分故障。單個系統(tǒng)的整體故障往往會導致整個系統(tǒng)崩潰。另一方面,在部分故障中,系統(tǒng)可以在從部分故障中恢復的同時繼續(xù)操作而不會嚴重影響整體性能。
在本文中,按照以下順序,我們將解釋容錯;即使系統(tǒng)的一部分發(fā)生故障,系統(tǒng)也可以繼續(xù)處理。
?什么樣的屬性是容錯的
?什么樣的失敗以及它們如何被分類
?關于溝通失敗
?“可靠的多播”,增加了進程的抵抗力
?關于分布式提交問題
2. 什么是容錯?
容錯
容錯定義如下
即使發(fā)生故障也能夠忍受服務
另外,具有容錯性的系統(tǒng)有時被稱為高可靠性系統(tǒng),并且與可靠性系統(tǒng)相關的要求分為以下四種。
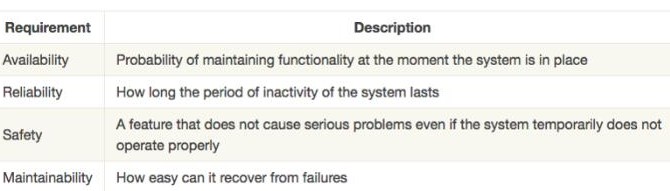
失敗模型
分布式系統(tǒng)中進程的典型故障如下:

通信鏈路的故障也是分類的。
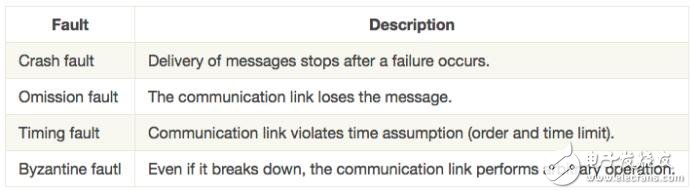
例如,對于分布式的失敗,可能會發(fā)生虛假消息的傳遞,因此最難以處理。
冗余可以隱藏故障。這很容易理解,例如考慮到哺乳動物有兩只眼睛,耳朵和肺。即使這些分布式器官中的一些失效,你也可以在隱藏故障的同時使用該系統(tǒng)。這稱為物理冗余。冗余有三種類型:信息冗余,時間冗余和物理冗余。
3. 流程彈性
在描述容錯之后,我們考慮如何實現容錯。
進程復制
典型的方法是進程復制。在組中創(chuàng)建(復制)相同的進程稱為復制。通過在分布式系統(tǒng)中復制,即使在部分故障的情況下,也可以通過正常過程提供服務。我們將復制過程稱為副本。
復用(復制)有兩種方法如下。
?主基礎協(xié)議(被動復制)
?重復寫入協(xié)議(PositiveReplication)
在前的中,只有主副本處理來自客戶端的消息,而其他副本備份主進程。雖然復制品之間的處理結果沒有不一致,并且通信功能的實現更容易,但是主復制品的故障需要選擇算法,并且處理有些復雜。
在后一種情況下,所有副本都會從客戶端接收和處理消息。此時,基于消息的處理需要總排序和原子性的兩個屬性。因此,原子多播需要更復雜的通信功能。

k容錯
在重復寫入協(xié)議中,據說具有k個容錯,即使它們失敗,k個組件也能正常移動。如果你有分布式故障,則至少需要2k+1個進程才能具有k容錯能力。
原子組播問題
作為上述復制模型的前提,存在所有請求必須以相同順序到達所有服務器的條件。這稱為原子多播問題。這將在第5章中詳細討論。
流程之間的協(xié)議
進程之間協(xié)議的問題對于賦予分布式系統(tǒng)容錯性是至關重要的。分布式協(xié)議算法的目的是在有限數量的步驟中達成共識,以實現彼此之間沒有失敗的過程,并且在代表性過程中存在一般分布式的問題。
分布式的一般問題
在具有k個錯誤進程的系統(tǒng)中,僅當存在2k+1個或更多正常進程并且整體上存在N=《 3k+1個進程時才達成協(xié)議。換句話說,只有超過三分之二的進程正常工作才能達成協(xié)議。(如果小于該值,則可能會因失敗的過程而受到欺騙。)
附錄:關于容錯所需的正常節(jié)點數
對于許多協(xié)議,具有分布式阻塞的最大允許節(jié)點數被稱為1/3。原因將在下面簡要描述。
設“N”為節(jié)點總數,“F”為分布式節(jié)點,“T”為正常共識所需的節(jié)點數。
例如,假設“N-F”的正常節(jié)點被分成相同的數字,并且數字表示如下。
(N-F) / 2
由于“F”的分布式節(jié)點具有任意行為,為了正常地達成共識,必須滿足以下表達式。
T 》 (N-F)/2 + F ???①
此外,考慮到F的所有分布式節(jié)點都處于離線狀態(tài)的情況,其他正常節(jié)點可以采用共識,因此以下表達式成立。
N-F ≥ T ???②
從①·②,
N?F 》 (N?F)/2 + F
∴F 《 N3
基于上述,當總節(jié)點中分布式節(jié)點的數量小于1/3時,可以正常地達成共識。
4.可靠的客戶端-服務器通信
到目前為止,我們討論了分布式系統(tǒng)中進程的容錯能力,并了解了復制。本章討論了通信鏈路上容錯的介紹。
P2P通信
分布式系統(tǒng)中的通信基礎是連接一個進程和另一個進程的點對點通信(一對一通信)。
TCP
TCP:實現可靠通信的點對點通信
TCP具有序列號,定時器,校驗和,確認,重傳控制,擁塞控制等機制。例如,由于丟失消息而導致的遺漏失敗可以通過包括TCP序列號的確認和基于確認的重傳控制來處理。
發(fā)生故障時的RPC(遠程過程調用)
RPC的目的是通過本地過程調用的形式實現進程間通信而不需要意識到通信部分。在使用RPC的分布式系統(tǒng)中可能會發(fā)生五個障礙。
1. 客戶端無法找到服務器。
2. 從客戶端到服務器的請求消息將丟失。
3. 收到請求后服務器崩潰。
4. 從服務器到客戶端的響應消息將丟失。
5. 在客戶端發(fā)送請求消息后發(fā)生故障。
作為對每個的對策,存在設置異常處理和計時器(時間限制)的方法。
5.可靠的團隊溝通
我們在前一章中專注于一對一通信,因此我們在此解釋一對多多播通信的高可靠性。在分布式系統(tǒng)中,重要的是發(fā)送消息而不會泄漏,包括訂單到彼此的服務器。
在沒有故障的情況下可靠的多播
考慮按順序向每個成員發(fā)送消息。
發(fā)送方首先將多播消息保存在手頭的歷史存儲器中。此外,發(fā)送方從接收方接收傳輸確認通知(ACK)。在ACK中,輸入并返回最后一個消息標識符已完成傳輸。如果由于消息丟失等而無法接收到包含預期標識符的ACK,則發(fā)送方重新發(fā)送該消息。
確保來自發(fā)件人的郵件以相同的順序傳遞給所有進程。
在分布式系統(tǒng)中,不是“一個過程”
具有“何時”發(fā)送方“在消息傳遞期間失敗,該消息被傳遞到所有剩余進程或被忽略”的屬性的可靠多播稱為虛擬同步。
此外,作為虛擬同步并以總順序執(zhí)行消息傳遞的通信稱為原子多播。
虛擬同步的一個實現示例是Isis。Isis保留并轉移mmessageM進行處理,直到它知道所有成員都收到了消息M.
6.分布式提交
推廣原子多播問題的問題稱為分布式提交問題。
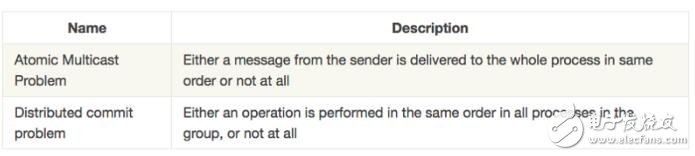
原子提交
有必要終始如一地判斷不同的類似站點的進程是否一致地提交或中止。這種操作稱為原子提交。
6–1.兩階段提交協(xié)議(2PC)
兩階段提交協(xié)議(2PC)是實現原子提交的典型方法。顧名思義,每個階段包括兩個步驟,組織如下。
(第1階段【投票階段】)
組織者向所有參與者發(fā)送VOTE_REQUEST消息
2. 收到VOTE_REQUEST消息的參與者如果能夠提交其交易并通過發(fā)送VOTE_ABORT消息進行投票(如果需要中止),則向組織者發(fā)送VOTE_COMMT消息。
(第2階段[提交階段])
3. 組織者收集所有參與者的投票。如果所有投票都是COMMIT,我們自己承諾并向所有參與者發(fā)送GLOBAL_COMMIT消息。如果ABORT甚至多于一個,它決定中止交易并發(fā)送GLOBAL_ABORT消息。
4.參與者等待來自組織者的消息,如果它是GLOBAL_COMMIT本地,則提交,如果它是GLOBAL_ABORT則丟棄該交易。
在整個過程中,組織者和參與者進行如下狀態(tài)轉換。
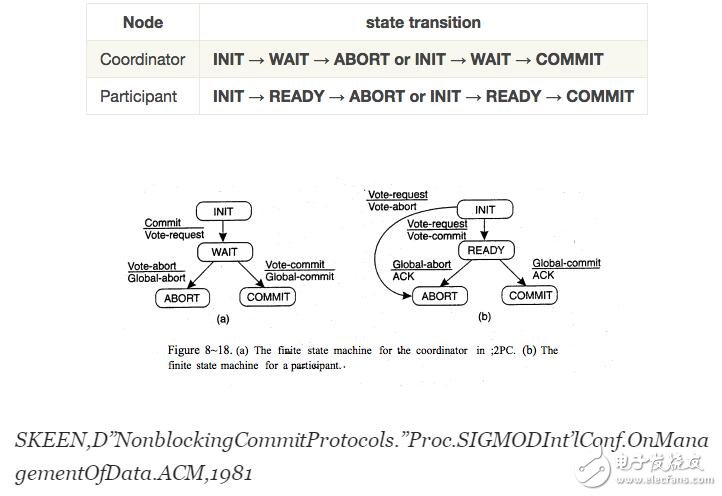
阻止提交協(xié)議
上述兩階段提交協(xié)議存在很大問題。當組織者在階段3中失敗并且所有參與者都在等待來自組織者的消息時。,參與者不能合作決定應該最終采取的行動決定。據此,兩階段提交被稱為阻塞提交協(xié)議。
實際上,在兩階段提交中阻塞自身很少發(fā)生,因此它沒有被大量使用,但是設計了三階段提交協(xié)議作為避免阻塞的解決方案。
6–2.三階段提交
與兩階段提交協(xié)議不同,三階段提交協(xié)議滿足以下兩個條件。[Skeen和Stonebraker,1983]指出,這兩個條件對于沒有阻塞的提交協(xié)議是必要和充分的。
1. 沒有直接進入COMMIT狀態(tài)或ABORT狀態(tài)的情況。
2. 沒有可能做出最終決定,也沒有轉換到COMMIT狀態(tài)的狀態(tài)。
SKEEN,D.andSTONEBRAKER,M”AFormalModelofCrashRecoveryinaDistributedSystem.”IEEETrans.Softw.Eng.,Mar.1983
具體地,在兩階段提交的兩個階段之間提供PRECOMMIT狀態(tài)。
整個參與者和組織者改變狀態(tài)如下。
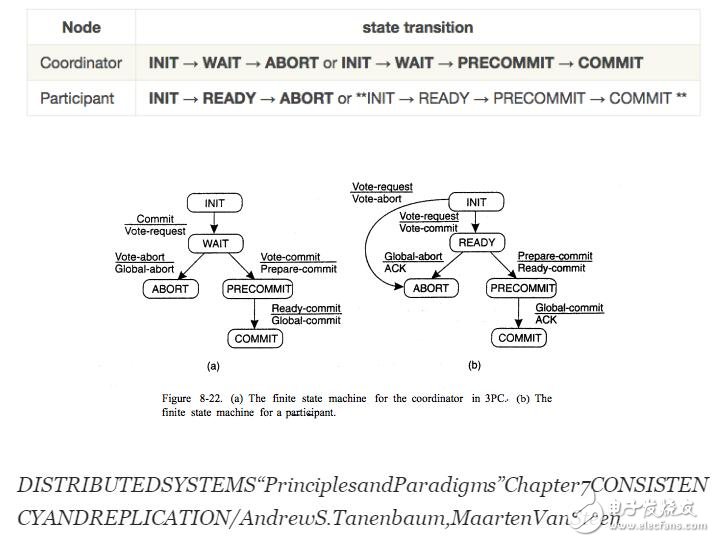
兩階段提交的最大區(qū)別是所有進程都返回INIT,ABORT,PRECOMMIT狀態(tài)。由于它永遠不會處于READY狀態(tài),因此剩余的進程始終做出最終決定,并且可以充當非阻塞協(xié)議。
三階段提交僅僅是一個概念表示,即使組織者失敗,也沒有正常工作的機制。然而,在區(qū)塊鏈出現之后,它的歷史將會發(fā)生很大變化。Tendermint項目通過在區(qū)塊鏈中采用三階段提交來實現非阻塞協(xié)議。
7.區(qū)塊鏈中的容錯
最后,基于上述內容,我們還將參考分布式區(qū)塊鏈系統(tǒng)中的容錯。
7–1.區(qū)塊鏈容錯
區(qū)塊鏈的容錯性很高。讓我們根據第2章中分類的四個可靠性要求,仔細研究區(qū)塊鏈的性質。
區(qū)塊鏈系統(tǒng)停止運行的時間和數量很少。特別是在比特幣網絡中,可以說很少有高可用性和可靠性,因為即使某些節(jié)點出現故障,它也能實現零停機并繼續(xù)正常運行。
接下來,關于安全性,當系統(tǒng)在區(qū)塊鏈網絡中不能正常運行時,將出現諸如“交易未被處理和阻塞”,“網絡中的節(jié)點之間不共享信息以及分叉的分塊”之類的問題。后者極有可能導致重大麻煩。
關于可維護性,可以說社區(qū)很容易劃分,比如像比特幣這樣的公共區(qū)塊鏈,并且難以從中恢復。比特幣網絡可以高度贊賞,因為它具有高可用性和可靠性,因此不需要恢復,但如果你希望具有可維護性,則應考慮選擇私有鏈或聯盟鏈。
此外,區(qū)塊鏈非常有意義,因為它為分布式斷層提供了有效的解決方案,這被認為是最難處理的。具體來說,它是以PoW等為代表的一致性算法……通過形成激勵結構來處理分布式的一般問題;通過維持/貢獻而不是基于博弈論破壞網絡的行動,礦工凸輪獲得更多利潤的算法。應該注意的是,諸如硬叉之類的新問題正在發(fā)生,然而,可以說它已經取得了一定的成功。此外,
Hyperledger采用的PBFT也通過設置領導節(jié)點確認投票來實現高分布式容錯。
7–2.Blcokchain流程彈性
考慮如何在容錯描述之后實現容錯。
首先,有兩種處理復制的方法。
1.主要基礎協(xié)議
2.重復寫入協(xié)議
采用1的主基礎協(xié)議的主要協(xié)議是基于PoW一致性算法的區(qū)塊鏈。在PoW的情況下,它是主要基礎中的本地寫協(xié)議的規(guī)范。成功找到PoW的nonce值作為獨占控件(領導者選擇算法)的礦工獲得了將區(qū)塊添加為主服務器的權利。但是,當有權成為主服務器的節(jié)點同時出現時,區(qū)塊鏈會分叉。
另一方面,采用2的重復寫協(xié)議的是基于PBFT的區(qū)塊鏈。包括Tendermint在內的各種基于PBFT的共識算法沒有主要服務器首先負責地執(zhí)行每個數據的更新,并且所有參與節(jié)點可以在同一時段執(zhí)行寫操作。也就是說,可以說PBFT類型一致性協(xié)議類似于重復寫入類型的活動復制協(xié)議。
7–3.區(qū)塊鏈高可靠性通信
我已經提到了區(qū)塊鏈的過程,但這次我將重點關注通信鏈接。
在區(qū)塊鏈中,參與網絡的每個節(jié)點執(zhí)行P2P通信并共享數據。另外,由領導者選擇算法選擇的主服務器執(zhí)行多播,以便例如在找到隨機數時將新添加的 區(qū)塊的信息共享給每個參與節(jié)點。此時,考慮到在通信鏈路或節(jié)點中發(fā)生故障的情況,重要的是實現原子多播,其是虛擬同步并且以總的順序執(zhí)行消息傳遞。
那么,區(qū)塊鏈中的原子多播問題和分布式提交問題是如何解決的呢?
在采用比特幣等PoW的公共鏈中,原子多播尚未實現。因此,可能會發(fā)生頻繁的叉子。由于每個節(jié)點隨時間正確地共享數據,因此建立了一致性,但確認交易存儲在區(qū)塊中需要10分鐘以上。
在這里,我們要關注Tendermint一致性算法。通常,存在2PC(兩階段提交)作為實現原子提交的方法,并且已經提出了作為改進版本的3PC方法,但兩者都是不完整的。因此,Tendermint通過將區(qū)塊鏈與3PC方法混合并在循環(huán)方法下在節(jié)點上添加約束來實現原子提交。下一章將解釋這個創(chuàng)新分布式提交問題的方法。
7–4.Tendermint中的分布式提交(創(chuàng)新的三階段提交模型)
首先,Tendermint是PBFT類型。在Hyperledger中,作為領導者的驗證者始終是相同的過程,但是Tendermint具有領導者選擇算法,并且通過循環(huán)法確定性地確定領導者。領導者共同提出存儲在mempool中的下一個交易塊。有了這個提議,Tendermint共識實現了3PC(三階段提交)并實現了原子組播。Tendermint一致性算法可以大致分為三種狀態(tài)。
1. PROPOSE
通過基于樁數的領導者選擇算法通過循環(huán)法確定性地選擇的驗證器集的提議。在這種狀態(tài)下開始投票。
2. PRE-VOTE
擬議區(qū)塊的第一次投票。一旦獲得三分之二或更多的批準,我們將繼續(xù)進行下一步,但要等到收集所有選票的限制時間。由于這個時間限制,可以說Tendermint是部分異步一致性算法。此外,該投票算法具有1/3k的容錯能力。
3. PRE-COMMIT
在預投票中超過2/3的同意第二次投票。此時,如下所述,當未收集2/3或更多的投票時,Tendermint的智能部分是一種衡量標準。
如前所述,通過為三階段提交設置PRECOMMIT階段,如果滿足以下條件,則可以實現阻塞協(xié)議。
1. 沒有直接轉換為COMMIT狀態(tài)或ABORT狀態(tài)的狀態(tài)
2. 沒有可能做出最終決定,也沒有轉換到COMMIT狀態(tài)的狀態(tài)。
在Tendermint中,在第二個投票階段投票的驗證者Pre-Commit被鎖定,并且只能在預投票中投票獲得超過2/3票數的鎖定區(qū)塊或區(qū)塊。通過鎖定處理,滿足上述兩個條件。換句話說,由于每個驗證器始終只能在預先提交中對一個塊進行投票,因此它不會實現分叉機制。
換句話說,“Tendermint共識是確保添加區(qū)塊的操作在網絡中的所有節(jié)點上完成,或者根本沒有節(jié)點完成;實現最終結果的下一代共識協(xié)議。








 工商網監(jiān)
工商網監(jiān)
評論