 電子發燒友App
電子發燒友App


COVA 協議擁有可以信任的 TEE 節點,并將通過設計社區激勵結構、多方秘密共享和計算方案,以激勵各方誠實行事。
新的數據傳輸協議
過去的幾年,以下幾個技術都取得了新的進展:運用字節運行監控(Bytecode Runtime Monitoring)、可驗證的秘密共享、可信執行環境(Trusted Execution Environment)以及基于博弈論的市場激勵方案。通過利用上述技術創新,COVA 創建了一個新的 Web 3.0 分布式數據傳輸協議,從而實現網絡的帕累托最優狀態。
COVA協議由七層實現。在本文中,我們將為這七個層中的每一層提供簡要說明:
第一層:數據所有者:dApp和數據存儲
COVA 用戶可以很容易地構建自己的 dApp,在測試階段,我們構建了一個基于 electronjs 的多平臺分散式應用程序(dApp)。這使得數據所有者能夠在自己的個人計算機中安全地離線處理、編碼和加密數據,具體如下:
1. 在數據處理階段,敏感的數據集被用一個矢量 v 進行縮放。這樣做的原因是為 TEE 節點增加安全防護——雖然TEE節點本身已經非常安全,極不可能被攻破。
2. 然后,數據將被編碼為 COVA 的智能數據格式,其中包含數據所有者指定的數據使用權限條款(例如不能在下周日之前讀取數據),再用 nacl 加密庫進行加密。
3. 在完成處理、編碼和加密步驟之后,這個 dApp 將加密密鑰 K 和其他敏感信息(例如矢量 v)分割成 N(在我們的設計中,N=100)塊:
在這里,我們使用受 Adi Shamir 秘密共享方案啟發的閾值加密算法來生成這些秘密。然后,dApp將元數據記錄到我們的數據目錄區塊鏈(第二層),并通過加密通道將 100 個秘密部分發送到 100 個路由節點。數據所有者還可以通過此界面與數據用戶創建智能合約(或者在稍后階段,數據使用者可以從目錄中查找數據集并與數據所有者創建智能合約)。
在后續的文章更新中,我們將公布上述方案的各種細節,包括多方秘密共享方案,如何在保持結構的情況下進行矢量 v 縮放等。
此外,對于測試階段的數據存儲,我們不限制任何數據存儲解決方案,大家可以選擇許多現有的數據存儲提供者(ipfs、s3、Dropbox 等)。數據所有者可以將加密數據上傳到他們選擇的任何存儲解決方案中,并將數據集鏈接到我們的 dApp 接口中。這些行為都是安全的,因為檢索實際數據集的唯一方法是讓某人同時訪問密鑰 K 和矢量 v,而這兩者都是通過閾值加密方案保護的。如果沒有大多數路由節點的共識,即使對手能夠攻擊大量的路由節點,他們也不能檢索密鑰。
第二層:數據目錄區塊鏈
數據目錄區塊鏈是分布式的分類帳本,用于保存數據集的元數據。獲得許可的各方(通常是數據所有者或 TEE)可以更新分類賬的元數據,但不能刪除條目。我們在測試網絡中使用了 tendermind 和 bigchaindb 來實現這個分類。
元數據字段是完全可定制的。dApp builder 可以讓數據所有者設計所需的規范,根據數據用戶平臺的規范更改元數據(或格式),比如根據醫療數據集的分散式市場要求更改。
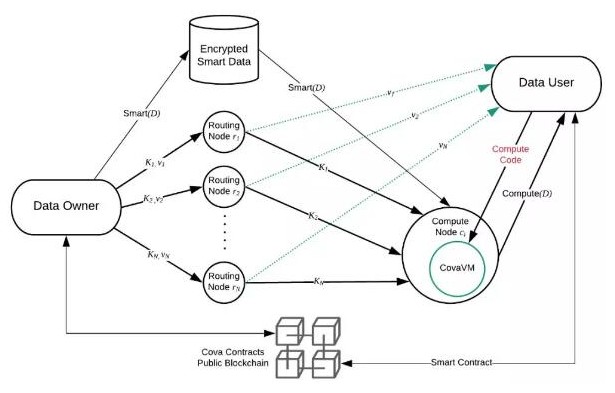
第三層:路由節點和計算節點池
COVA 的 TEE 節點分為兩種:
路由節點:主要用于路由、驗證和傳輸計算狀態。每個池100個節點,高可用性、更高的安全押金和更高的獎勵。
計算節點:主要用于計算,對退出中間計算有一個懲罰。其可以是 TEE 節點,也可以是 TEE 控制的云計算節點(CS2)。
為了保證高可用性,我們擁有多個由 100 個路由節點組成的池。正如我們將在第四層討論的,我們需要多數人的共識和可用性來檢索加密密鑰,我們希望激勵節點高度可用,同時將冗余計算的數量保持在最低限度。
我們有各種激勵和懲罰,以盡量減少惡意行為和最大限度地利用網絡。例如,如果某一個路由節點不滿足我們的可用性標準(比如確保 99% 以上正常運行時間),其他路由節點可以集體投票將此路由節點降級到計算節點,其他一些激勵和懲罰措施,我們將在介紹第六層時補充。
最后,路由節點和計算節點都具有極高的安全性,它們都是運行 Intel SGX 軍事級別隱私保護技術的 TEE 節點,唯一的區別是路由節點是根據可用性和較高的押金投入而選擇的社區。而且,包括多方秘密共享、擴展或激勵結構在內的機制都已到位,足以防止節點主機在出現某些 zero-day 漏洞攻擊下損害 TEE 節點——雖然這種情況出現的可能性極小。
第四層:路由節點上的閾值加密密鑰存儲
COVA 使用可驗證的多方秘密共享方案,而不是完全信任一個 TEE 路由節點(比如數據加密密鑰)。我們使用了 Shamir 秘密共享方案的一個延伸方案。當我們擁有大多數誠實路由節點時,它可以生成秘密。此外,它還可以檢測一個路由節點是否誠實,這樣我們就可以禁止某些不誠實的路由節點。這個方案背后的數學概念如下:
1. 數據所有者生成一個 100m 個隨機多項式,其中 m 是誠實路由節點的最小分數,常數多項式是加密密鑰。
2. 然后,數據所有者在 100 個不同的點上計算該多項式,并將這些秘密共享發送到路由節點。路由節點不能重新創建密鑰,除非至少有 m 個節點提供了它們的秘密共享。
3. 此外,在至少有 m 個誠實的情況下,如果其他節點不誠實,我們可以檢測到惡意用戶。
在我們的設計中,秘密共享方案被用于共享加密密鑰和縮放矢量 v。
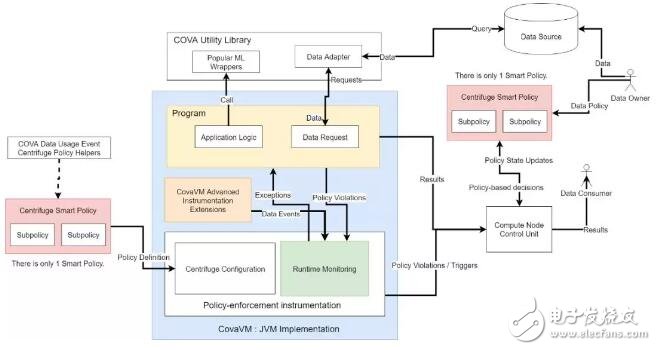
第五層:智能條款執行器
智能條款執行器指的是在 TEE 節點上運行的 Centrifuge 語言和 CovaVM 虛擬機。舉個例子,假定我們需要運行一個來自數據使用者的不可信代碼,就需要創建一個沙盒,CovaVM,并啟用一個運行時監視系統,以確保代碼遵循數據所有者設置的數據使用條款。目前為止,我們已經實現了開放源代碼的安全模型,確保數據用戶只能運行 python sklearn 或者 Tensorflow 庫中 28 個已批準的機器學習模型,我們會使用 Centrifuge 來驗證。
第六層:社區經濟:支付和激勵
社區經濟是一個抽象的層次。它幫助我們實現目標,即通過 COVA 基金會的最小干預,創建一個自我維持的、分散的網絡。要做到這一點,我們需要精心設計支付和獎勵措施。我們需要支付各種步驟,包括計算獎勵的 TEE 計算節點、路由獎勵的 TEE 路由節點和獎勵數據所有者的貢獻。在我們的測試網中,COVA Token由以太坊智能合約提供支持,以最大限度適應和易于開發。
理論上講,TEE 是完全安全的,不過為了防止安全漏洞和攻擊載體(比如 spectre、meltdown 和 foreshadowing)的影響,我們將最敏感信息的檢索移動到路由節點共識上。我們的基本假設是,大多數節點是誠實的。此外,如果任何節點是不誠實的,我們可以使用多數共識中找到的信息立即檢測到這類節點。在這種情況下,該路由節點將完全喪失其大量押金,并且特定 CPU(由唯一的 CPUID 標識)和該路由節點所有者將被禁止進入網絡。
在計算節點這一側,雖然很難在不重新運行整個計算的情況下計算整個輸出,但我們在路由節點和數據使用者中都有一個驗證階段。為了簡單起見,如果我們假設一個參與者是惡意的(手段:破壞 TEE enclave)的獨立概率是 ε,那么對于 k 方驗證,所有這些都是惡意的概率是 ε?,ε 本身就是一個很小的數,ε? 值就更小了。
雖然用戶冒著押金(或法律行動)風險以獲得一些縮放數據集或不正確的計算以獲得小額計算獎勵的動機相當小,但我們還是嚴陣以待,并且使用各種隨機驗證器來確保安全。
第七層:數據使用界面
數據使用界面是一個簡單的界面,允許數據使用者在啟動與數據所有者的智能合約時運行一些自定義代碼(策略允許)。此部分的實現細節將留給協議用戶或 dApp builder。目前,數據使用者可以編寫 python 代碼,這些代碼將由 Centrifuge 和 CovaVM 驗證。
代碼在 TEE 中運行完畢后,TEE 將縮放的計算值返回給數據使用者,路由節點提供最多 100 個由矢量 v 構成的秘密位,數據使用者可以運用 Shamir 的秘密共享方案組合生成矢量 v。為了完成數據分析和聚合計算,數據使用者可以通過導出的縮放矢量來找到在未縮放數據上訓練的等效模型。例如:如果我們使用矢量 v 任何監督機器學習模型(Supervised Machine Learning Model)來縮放訓練數據,則相當于在使用 Centrifuge 模型之前使用 v 縮放測試數據和預測。
最后
雖然這七層可能看起來令人很復雜,但與任何協議(如 HTTP 或 FTP)類似,最終用戶只需要熟悉這個胖協議的第一層或第七層就可以。在接下來的深度文章中,我們將繼續為大家解釋各個層以及每層設置的各種激勵。
















 工商網監
工商網監
評論