 電子發(fā)燒友App
電子發(fā)燒友App


2009 年 1 月 3 日,比特幣作為一種自持的 P2P 系統(tǒng)啟動(dòng)了創(chuàng)世區(qū)塊,以巧妙的設(shè)計(jì)驅(qū)使參與者維持它的運(yùn)轉(zhuǎn),并提供受限但極具顛覆性的金融功能至今。2015 年 6月 30 日,以太坊上線,為區(qū)塊鏈增加了圖靈完備的智能合約,可以對(duì)一些短小的程序的執(zhí)行結(jié)果形成共識(shí)。相對(duì)于比特幣,以太坊可以執(zhí)行更復(fù)雜的計(jì)算,提供更豐富的響應(yīng),然而這些合約是不具備學(xué)習(xí)能力和自我進(jìn)化規(guī)則的,是純粹的基于簡單規(guī)則(rule-based) 與遞歸調(diào)用的子程序的集合。參考 Conway 的生命游戲,基于 P2P 技術(shù)的虛擬貨幣網(wǎng)絡(luò)可以被界定為生存在互聯(lián)網(wǎng)上的生命,通過提供金融功能維持自身的存在,只要還有一個(gè)全節(jié)點(diǎn)在,網(wǎng)絡(luò)的狀態(tài)就可以得到保存,并且能夠響應(yīng)來自外界的交互。然而人類渴望的智能還沒有出現(xiàn),這些原始的網(wǎng)絡(luò)生命只停留在簡單規(guī)則的水平。
Cortex 在此基礎(chǔ)上更進(jìn)一步,為區(qū)塊鏈增加了人工智能的共識(shí)推斷,所有全節(jié)點(diǎn)共同運(yùn)作,對(duì)一個(gè)要求人工智能的智能合約的執(zhí)行達(dá)成共識(shí),為系統(tǒng)賦予智能響應(yīng)的能力。Cortex 作為一條兼容 EVM 智能合約的獨(dú)立公鏈,可以運(yùn)行現(xiàn)有的合約和帶有人工智能推斷的合約,在創(chuàng)世區(qū)塊發(fā)布后,也將作為一個(gè)更加智能的網(wǎng)絡(luò)生命永續(xù)存在下去。在 Cortex 中,由于開源和天然的競(jìng)爭機(jī)制,最優(yōu)秀的模型終將會(huì)存留下來,提升網(wǎng)絡(luò)的智能水平。從機(jī)器學(xué)習(xí)研究者的角度來講,Cortex 平臺(tái)集合了各種基本智能應(yīng)用的公開模型,并且是當(dāng)前的世界級(jí)水準(zhǔn) (state of the art),這將大大加速他們的研究,并朝向 AI in All 的智能世界快速前進(jìn)。這條公鏈同時(shí)使得模型在部署后的計(jì)算結(jié)果自動(dòng)地得到全網(wǎng)公證。外星人存在與否我們尚不可知,但有人工智能的陪伴,人類不再孤獨(dú)前行。
系統(tǒng)架構(gòu)
1.擴(kuò)充智能合約和區(qū)塊鏈的功能
Cortex 智能推斷框架
模型的貢獻(xiàn)者將不限于 Cortex 團(tuán)隊(duì),全球的機(jī)器學(xué)習(xí)從業(yè)人員都可以將訓(xùn)練好的相應(yīng)數(shù)據(jù)模型上傳到存儲(chǔ)層,其他需要該數(shù)據(jù)模型的用戶可以在其訓(xùn)練好的模型上進(jìn)行推斷,并且支付費(fèi)用給模型上傳者。每次推斷的時(shí)候,全節(jié)點(diǎn)會(huì)從存儲(chǔ)層將模型和數(shù)據(jù)同步到本地。通過 Cortex 特有的虛擬機(jī) CVM (Cortex Virtual Machine) 進(jìn)行一次推斷,將結(jié)果同步到全節(jié)點(diǎn),并返回結(jié)果。
將需要預(yù)測(cè)的數(shù)據(jù)進(jìn)行代入計(jì)算到已知一個(gè)數(shù)據(jù)模型獲得結(jié)果就是一次智能推斷的過程。用戶每發(fā)起一筆交易,執(zhí)行帶有數(shù)據(jù)模型的智能合約和進(jìn)行推斷都需要支付一定的 Endorphin,每次支付的 Endorphin 數(shù)量取決于模型運(yùn)算難度和模型排名等。Endorphin和 Cortex Coin 會(huì)有一個(gè)動(dòng)態(tài)的轉(zhuǎn)換關(guān)系,Endorphin 的價(jià)格由市場(chǎng)決定,反映了Cortex 進(jìn)行模型推斷和執(zhí)行智能合約的成本。這部分 Endorphin 對(duì)應(yīng)的 Cortex Coin會(huì)分成兩個(gè)部分,一部分支付給智能合約調(diào)用 Infer 的模型提交者,另一部分支付給礦工作為打包區(qū)塊的費(fèi)用。對(duì)于支付給模型提交者的比例,Cortex 會(huì)為這個(gè)比例設(shè)定一個(gè)上限。
ortex 在原有的智能合約中額外添加一個(gè) Infer 指令,使得在智能合約中可以支持使用 Cortex 鏈上的模型。
下述偽代碼表述了如何在智能合約里使用 Infer ,當(dāng)用戶調(diào)用智能合約的時(shí)候就會(huì)對(duì)這個(gè)模型進(jìn)行一次推斷:
模型提交框架
前面分析了鏈上訓(xùn)練的難處和不可行性,Cortex 提出了鏈下 (Offchain) 進(jìn)行訓(xùn)練的提交接口,包括模型的指令解析虛擬機(jī)。這能夠給算力提供方和模型提交者搭建交易和合作的橋梁。
用戶將模型通過 Cortex 的 CVM 解析成模型字符串以及參數(shù),打包上傳到存儲(chǔ)層,并發(fā)布通用接口,讓智能合約編寫用戶進(jìn)行調(diào)用。模型提交者需要支付一定的存儲(chǔ)費(fèi)用得以保證模型能在存儲(chǔ)層持續(xù)保存。對(duì)智能合約中調(diào)用過此模型進(jìn)行 Infer 所收取的費(fèi)用會(huì)有一部分交付給模型提交者。提交者也可以根據(jù)需要進(jìn)行撤回和更新等操作。對(duì)于撤回的情況,為了保證調(diào)用此模型的智能合約可以正常運(yùn)作,Cortex 會(huì)根據(jù)模型的使用情況進(jìn)行托管,并且保持調(diào)用此模型收取的費(fèi)用和存儲(chǔ)維護(hù)費(fèi)用相當(dāng)。Cortex 同時(shí)會(huì)提供一個(gè)接口將模型上傳到存儲(chǔ)層并獲得模型哈希。之后提交者發(fā)起一筆交易,執(zhí)行智能合約將模型哈希寫入存儲(chǔ)中。這樣所有用戶就可以知道這個(gè)模型的輸入輸出狀態(tài)。
智能 AI 合約
Cortex 允許用戶在 Cortex 鏈上進(jìn)行和機(jī)器學(xué)習(xí)相關(guān)的編程,并且提交一些依賴其他合約的交互,這將變得十分有趣。比如以太坊上運(yùn)行的電子寵物 Cryptokitties ,寵物之間的交互可以是動(dòng)態(tài)的、智能的、進(jìn)化的。通過用戶上傳的增強(qiáng)學(xué)習(xí)模型,賦予智能合約結(jié)合人工智能,可以很方便的實(shí)現(xiàn)類似帶有人工智能的各種應(yīng)用。
同時(shí) Cortex 為其他鏈提供 AI 調(diào)用接口。比如在比特幣現(xiàn)金和以太坊上,Cortex 提供基于人工智能的合約錢包地址上分析的調(diào)用結(jié)果。那些分析地址的模型將將不僅有助于監(jiān)管科技 (RegTech),也能給一般用戶提供轉(zhuǎn)賬目標(biāo)地址的動(dòng)態(tài)風(fēng)險(xiǎn)評(píng)估。
2.模型和數(shù)據(jù)存儲(chǔ)
Cortex 鏈并不實(shí)際存儲(chǔ)模型和數(shù)據(jù),只存儲(chǔ)模型和數(shù)據(jù)的 Hash 值,真正的模型和數(shù)據(jù)存儲(chǔ)在鏈外的 key-value 存儲(chǔ)系統(tǒng)中。新模型和新數(shù)據(jù)在節(jié)點(diǎn)上有足夠多的副本之后將可以在鏈上可用。
3.Cortex 共識(shí)推斷標(biāo)準(zhǔn)
當(dāng)用戶發(fā)起一筆交易到某個(gè)合約之后,全節(jié)點(diǎn)需要執(zhí)行該智能合約的代碼。Cortex 和普通智能合約不同的地方在于其智能合約中可能涉及推斷指令,需要全節(jié)點(diǎn)對(duì)于這個(gè)推斷指令的結(jié)果進(jìn)行共識(shí)。整個(gè)全節(jié)點(diǎn)的執(zhí)行流程是:
1. 全節(jié)點(diǎn)通過查詢模型索引找到模型在存儲(chǔ)層的位置,并下載該模型的模型字符串和對(duì)應(yīng)的參數(shù)數(shù)據(jù)。
2. 通過 Cortex 模型表示工具將模型字符串轉(zhuǎn)換成可執(zhí)行代碼。
3. 通過 Cortex 提供的虛擬機(jī) CVM ,執(zhí)行可執(zhí)行代碼,得到結(jié)果后進(jìn)行全節(jié)點(diǎn)廣播共識(shí)。
Cortex 模型表示工具的作用可以分為兩部分:
1. 模型提交者需要將自己編寫的模型代碼通過模型表示工具轉(zhuǎn)化為模型字符串之后才可以提交到存儲(chǔ)層。
2. 全節(jié)點(diǎn)下載模型字符串之后通過模型表示工具提供的轉(zhuǎn)換器轉(zhuǎn)換成可執(zhí)行代碼后,在 Cortex 虛擬機(jī)中執(zhí)行推斷操作。
Cortex 虛擬機(jī)的作用在于全節(jié)點(diǎn)的每次推斷執(zhí)行都是確定的。
4.如何挑選優(yōu)秀的模型
Cortex 鏈不會(huì)對(duì)模型進(jìn)行限制,用戶可以依靠模型 infer 的調(diào)用次數(shù)作為相對(duì)客觀的模型評(píng)價(jià)標(biāo)準(zhǔn)。當(dāng)模型使用者對(duì)模型有不計(jì)計(jì)算代價(jià)的高精度需求時(shí),Cortex 支持保留
原有模型參數(shù)使用浮點(diǎn)數(shù)來表示。從而,官方或者第三方機(jī)構(gòu)可以通過自行定義對(duì)模型的排序機(jī)制(召回率,準(zhǔn)確率,計(jì)算速度,基準(zhǔn)排序數(shù)據(jù)集等),達(dá)成模型的甄選工作,并展示在第三方的網(wǎng)站或者應(yīng)用中。
5 共識(shí)機(jī)制:PoW 挖礦
一直以來,一機(jī)一票的加密數(shù)字貨幣社區(qū)設(shè)想并未實(shí)現(xiàn)。原因是 ASIC 的特殊設(shè)計(jì)使得計(jì)算加速比得到大幅提升。社區(qū)和學(xué)術(shù)界探索了很多內(nèi)存瓶頸算法來對(duì)顯卡和 CPU 挖礦更加友好,而無需花費(fèi)大量資金購買專業(yè)挖礦設(shè)備。近年來社區(qū)實(shí)踐的結(jié)果顯示,以太坊的 Dagger-Hashimoto和 Zcash 的 Equihash是比較成功的顯卡優(yōu)先原則的算法實(shí)踐。
Cortex 鏈將進(jìn)一步秉承一機(jī)一票優(yōu)先,采用 Cuckoo Cycle 的 PoW 進(jìn)一步縮小 CPU和顯卡之間加速比的差距。同時(shí) Cortex 鏈將充分發(fā)掘智能手機(jī)顯卡的效能,使得手機(jī)和桌面電腦的顯卡差距符合通用硬件平臺(tái)測(cè)評(píng)工具(如 GFXBench )的差距比例:比如,最好的消費(fèi)級(jí)別顯卡是最好的手機(jī)顯卡算力的 10-15 倍。考慮到手機(jī)計(jì)算的功耗比更低,使得大規(guī)模用戶在夜間充電時(shí)間利用手機(jī)挖礦將變得更加可行。
特別值得注意的一點(diǎn)是,出塊加密的共識(shí)算法和鏈上的智能推斷合約的計(jì)算并沒有直接聯(lián)系,PoW 保障參與挖礦的礦工們硬件上更加公平,而智能計(jì)算合約則自動(dòng)提供公眾推理的可驗(yàn)證性。
6.防作弊以及模型篩選
由于模型是完全公開的,所以可能會(huì)有模型被復(fù)制或抄襲等現(xiàn)象發(fā)生。在一般情況下,如果是一個(gè)非常優(yōu)秀的模型,往往上線之后就會(huì)有很高的使用量,而針對(duì)這些模型進(jìn)行抄襲并沒有很大優(yōu)勢(shì),但是,在一些特殊情況下,對(duì)一些很明顯的抄襲或者完全復(fù)制的行為,Cortex 會(huì)進(jìn)行介入并且仲裁,并通過鏈上 Oracle 的方式公示。
軟件方案
1.CVM:EVM + Inference
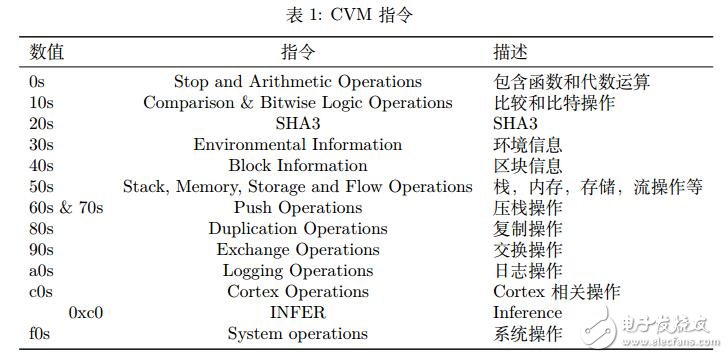
Cortex 擁有自己的虛擬機(jī),稱為 Cortex Virtual Machine(CVM)。CVM 指令集完全兼容 EVM,此外,CVM 還提供對(duì)于推斷指令的支持。Cortex 將在 0xc0 加入一個(gè)新的 INFER 指令。這條指令的輸入是推斷代碼,輸出是推斷結(jié)果。CVM 使用的虛擬機(jī)指令包含的內(nèi)容在表 1中說明。
2.Cortex 核心指令集與框架標(biāo)準(zhǔn)
人工智能的典型應(yīng)用——圖像問題,語音/語義/文本問題,與強(qiáng)化學(xué)習(xí)問題無一例外的需要以下張量操作。Cortex 以張量操作的代價(jià)作為 Endorphin 計(jì)費(fèi)的一種潛在錨定手段,剖析機(jī)器學(xué)習(xí)以及深度學(xué)習(xí)的核心指令集。在不同計(jì)算框架中,這一術(shù)語往往被稱為網(wǎng)絡(luò)層 (network layer) 或者操作符 (operator)。
? 張量的計(jì)算操作,包括:
– 張量的數(shù)值四則運(yùn)算:輸入張量,數(shù)值與四則運(yùn)算符
– 張量之間的按位四則運(yùn)算:輸入兩個(gè)張量與四則運(yùn)算符
– 張量的按位函數(shù)運(yùn)算:輸入張量與乘方函數(shù)、三角函數(shù)、冪與對(duì)數(shù)函數(shù)、大小判斷函數(shù)、隨機(jī)數(shù)生成函數(shù)、取整函數(shù)等。
– 張量的降維運(yùn)算:輸入張量與滿足結(jié)合律、交換律的操作符。
– 張量之間的廣播運(yùn)算:輸入張量,用維度低張量補(bǔ)齊維度后進(jìn)行按位操作。
– 張量之間的乘法操作:以 NCHW/NHWC 張量存儲(chǔ)模式為例,包含張量與矩陣、矩陣與向量等張量乘法/矩陣乘法操作。
? 張量的重構(gòu)操作,包括:
– 維度交換,維度擴(kuò)張與維度壓縮
– 按維度排序
– 值補(bǔ)充
– 按通道拼接
– 沿圖像平面拼接/剪裁
? 神經(jīng)網(wǎng)絡(luò)特定操作
– 全連接
– 神經(jīng)網(wǎng)絡(luò)激發(fā)函數(shù)主要依賴張量的按位函數(shù)運(yùn)算的操作
– 1 維/2 維/3 維卷積(包括不同尺度卷積核、帶孔、分組等選項(xiàng))
– 通過上采樣實(shí)現(xiàn)的 1 維/2 維/3 維反卷積操作與線性插值操作
– 通用輔助運(yùn)算(如對(duì)一階/二階信息的統(tǒng)計(jì) BatchNorm)
– 圖像類輔助計(jì)算(如可形變卷積網(wǎng)絡(luò)的形變參數(shù)模塊)
– 特定任務(wù)輔助計(jì)算(如 ROIPooling, ROIAlign 模塊)
Cortex 的核心指令集已覆蓋主流的人工智能計(jì)算框架操作。受制于不同平臺(tái)上 BLAS的實(shí)現(xiàn),Cortex 把擁有浮點(diǎn)數(shù) (Float32, Float16) 參數(shù)的 Cortex 模型通過 DevKit 轉(zhuǎn)化為定點(diǎn)數(shù)(INT8, INT6)參數(shù)模型 (Wu et al. [9]Han et al. [10]),從而支持跨平臺(tái)的推斷共識(shí)。
3.Cortex 模型表示工具
Cortex 模型表示工具創(chuàng)建了一個(gè)開放,靈活的標(biāo)準(zhǔn),使深度學(xué)習(xí)框架和工具能夠互操作。它使用戶能夠在框架之間遷移深度學(xué)習(xí)模型,使其更容易投入生產(chǎn)。Cortex 模型表示工具作為一個(gè)開放式生態(tài)系統(tǒng),使人工智能更容易獲得,對(duì)不同的使用者都有價(jià)值:人工智能開發(fā)人員可以根據(jù)不同任務(wù)選擇正確的框架,框架開發(fā)人員可以專注于創(chuàng)新與更新,硬件供應(yīng)商可以針對(duì)性的優(yōu)化。例如,人工智能開發(fā)人員可以使用 PyTorch等框架訓(xùn)練復(fù)雜的計(jì)算機(jī)視覺模型,并使用 CNTK 、Apache MXNet 或者 TensorFlow進(jìn)行推斷。
模型表示的基礎(chǔ)是關(guān)于人工智能計(jì)算的 Cortex 核心指令集的規(guī)范化。隨著人工智能領(lǐng)域研究成果、軟件框架、指令集、硬件驅(qū)動(dòng)、硬件形式的日益豐富,工具鏈碎片化問題逐漸突顯。很多新的論文站在前人的工作基礎(chǔ)上進(jìn)行微創(chuàng)新;理論過硬的科研成果得到的模型、數(shù)據(jù)、結(jié)論并不是站在過去最佳成果之上進(jìn)行進(jìn)一步發(fā)展,為精度的提高帶來天花板效應(yīng);工程師為了解決特定問題而設(shè)計(jì)的硬編碼更加無法適應(yīng)爆發(fā)式增長的數(shù)據(jù)。
Cortex 模型表示工具被設(shè)計(jì)為
? 表征:將字符串映射為主流神經(jīng)網(wǎng)絡(luò)模型、概率圖模型所支持的最細(xì)粒度的指令集
? 組織:將指令集映射為主流神經(jīng)網(wǎng)絡(luò)框架的代碼
? 遷移:提供同構(gòu)檢測(cè)工具,使得不同機(jī)器學(xué)習(xí)/神經(jīng)網(wǎng)絡(luò)框架中相同模型可以互相遷移
4.存儲(chǔ)層
Cortex 可以使用任何 key-value 存儲(chǔ)系統(tǒng)來存儲(chǔ)模型,可行的選擇是 IPFS 和 libtorrent。Cortex 的數(shù)據(jù)存儲(chǔ)抽象層并不依賴于任何具體的分布式存儲(chǔ)解決方案,分布式哈希表或者 IPFS 都可以用來解決存儲(chǔ)問題,對(duì)于不同設(shè)備,Cortex 采取不同策略:
? 全節(jié)點(diǎn)常年存儲(chǔ)公鏈數(shù)據(jù)模型
? 手機(jī)節(jié)點(diǎn)采取類似比特幣輕錢包模式,只存儲(chǔ)小規(guī)模的全模型
Cortex 只負(fù)責(zé)共識(shí)推斷,不存儲(chǔ)任何訓(xùn)練集。為了幫助合約作者篩選模型,避免過擬合的數(shù)據(jù)模型難題,合約作者可以提交測(cè)試集到 Cortex 披露模型結(jié)果。
一條進(jìn)入合約級(jí)別的調(diào)用,會(huì)在內(nèi)存池 (Mempool) 中排隊(duì),出塊后,將打包進(jìn)入?yún)^(qū)塊確認(rèn)交易。緩存期間數(shù)據(jù)會(huì)廣播到包括礦池的全節(jié)點(diǎn)。Cortex 當(dāng)前的存儲(chǔ)能力,能夠支持目前圖片、語音、文字、短視頻等絕大部分典型應(yīng)用,足以覆蓋絕大多數(shù)人工智能問題。對(duì)于超出當(dāng)前存儲(chǔ)限制的模型和數(shù)據(jù),比如醫(yī)療全息掃描數(shù)據(jù),一條就可能幾十個(gè) GB ,將在未來 Cortex 提升存儲(chǔ)限制后加入支持。
對(duì)于 Cortex 的全節(jié)點(diǎn),需要比現(xiàn)有比特幣和以太坊更大的存儲(chǔ)空間來存儲(chǔ)緩存的數(shù)據(jù)測(cè)試集和數(shù)據(jù)模型。考慮到摩爾定律 (Moore’s Law),存儲(chǔ)設(shè)備價(jià)格將不斷下降,因此不會(huì)構(gòu)成障礙。對(duì)于每個(gè)數(shù)據(jù)模型,Metadata 內(nèi)將建立標(biāo)注信息,用來進(jìn)行鏈上調(diào)用的檢索。Metadata 的格式在表 2中表述。

5.模型索引
Cortex 存儲(chǔ)了所有的模型,在全節(jié)點(diǎn)中,對(duì)于每筆需要驗(yàn)證的交易,如果智能合約涉及共識(shí)推斷,則需要從內(nèi)存快速檢索出對(duì)應(yīng)的模型進(jìn)行推斷。Cortex 的全節(jié)點(diǎn)內(nèi)存將為本地存儲(chǔ)的模型建立索引,根據(jù)智能合約存儲(chǔ)的模型地址去檢索。
6.模型緩存
Cortex 的全節(jié)點(diǎn)存儲(chǔ)能力有限,無法存下全網(wǎng)所有模型。Cortex 引入了緩存來解決這個(gè)問題,在全節(jié)點(diǎn)中維護(hù)一個(gè) Model Cache 。Model Cache 數(shù)據(jù)模型的替換策略,有最近最常使用(LRU)、先進(jìn)先出(FIFO)等,也可以使用任何其他方案來提高命中率。
7.全節(jié)點(diǎn)實(shí)驗(yàn)
針對(duì)全節(jié)點(diǎn)執(zhí)行推斷指令的吞吐情況,本章描述了一些在單機(jī)上實(shí)驗(yàn)的結(jié)果。測(cè)試平臺(tái)配置為:
? CPU: E5-2683 v3
? GPU: 8x1080Ti
? 內(nèi)存: 64 GB
? 硬盤: SSD 960 EVO 250 GB
實(shí)驗(yàn)中使用的測(cè)試代碼基于 python 2.7 和 MXNet ,其中主要包含以下模型:
? CaffeNet
? Network in Network
? SqueezeNet
? VGG16
? VGG19
? Inception v3 / BatchNorm
? ResNet-152
? ResNet101-64x4d
所有模型都可以在 MXNet 的文檔 1 中找到。實(shí)驗(yàn)分別在 CPU 和 GPU 中測(cè)試這些模型在平臺(tái)上的推斷速度,這些測(cè)試不考慮讀取模型的速度,所有模型會(huì)提前加載到內(nèi)存或者顯存中。
測(cè)試結(jié)果如表 3,括號(hào)中是 Batch Size(即一次計(jì)算所傳入的數(shù)據(jù)樣本量),所有 GPU測(cè)試結(jié)果都是在單卡上的測(cè)試。
以上是單機(jī)測(cè)試的結(jié)果。為了模擬真實(shí)的情況,試驗(yàn)平臺(tái)上設(shè)置 10 萬張的圖片不斷進(jìn)行推斷,每次推斷選擇隨機(jī)的模型來進(jìn)行并且 Batch Siz e 為 1,圖片發(fā)放到 8 張帶有負(fù)載均衡的顯卡上。對(duì)于兩種情況:
1. 所有模型都已經(jīng)讀取完畢并存放到顯存中,其單張圖片推斷的平均速度為 3.16ms。
2. 每次重新讀取數(shù)據(jù)(包括模型和輸入數(shù)據(jù))而不是提前加載進(jìn)顯存,但是進(jìn)行緩存,其單張圖片推斷的平均速度為 113.3 ms。
結(jié)論 全節(jié)點(diǎn)在模型已經(jīng)預(yù)讀到顯存之后,支持負(fù)載均衡,并且將同一模型進(jìn)行顯卡間并行推斷,測(cè)試結(jié)果大約每秒能執(zhí)行接近 300 次的單一推斷。如果在極端情況下不進(jìn)行顯存預(yù)讀,而只是進(jìn)行緩存,每次重新讀取模型和輸入數(shù)據(jù),大約每秒能進(jìn)行 9 次左右的單一推斷。以上實(shí)驗(yàn)都是在沒有優(yōu)化的情況下進(jìn)行的計(jì)算,Cortex 的目標(biāo)之一是致力于不斷優(yōu)化提高推斷性能。
硬件方案
1.CUDA and RoCM 方案
Cortex 的硬件方案大量采用了 NVidia 公司的 CUDA 驅(qū)動(dòng)與 CUDNN 庫作為顯卡計(jì)算的開發(fā)框架。同時(shí),AMD OpenMI 軟件項(xiàng)目采用了 RoCM 驅(qū)動(dòng)與 HIP/HCC 庫人工智能研發(fā)計(jì)劃, 并計(jì)劃在 2018 年底推出后支持的開發(fā)框架。
2.FPGA 方案
FPGA 產(chǎn)品的特性是低位定點(diǎn)運(yùn)算 (INT8 甚至 INT6 運(yùn)算),延時(shí)較低,但是計(jì)算功耗較高,靈活性較差;在自動(dòng)駕駛領(lǐng)域、云服務(wù)領(lǐng)域已經(jīng)有較好的深度學(xué)習(xí)部署方案。Cortex 計(jì)劃對(duì) Xilinx 與 Altera 系列產(chǎn)品提供 Infer 支持。
3.全節(jié)點(diǎn)的硬件配置需求 - 多顯卡和回歸傳統(tǒng)的 USB 挖礦
不同于傳統(tǒng)的比特幣和以太坊全節(jié)點(diǎn),Cortex 對(duì)全節(jié)點(diǎn)的硬件配置需求較高。需要比較大的硬盤存儲(chǔ)空間和多顯卡桌面主機(jī)來達(dá)到最佳確認(rèn)速度的性能,然而這并不是必需的。在比特幣領(lǐng)域 USB 曾經(jīng)是一種即插即用的比特幣小型 ASIC 礦機(jī),在大規(guī)模礦廠形成之前,這種去中心化的挖礦模式,曾經(jīng)風(fēng)靡一時(shí),Cortex 全節(jié)點(diǎn)在缺少顯卡算力的情況下可以配置類似的神經(jīng)網(wǎng)絡(luò)計(jì)算芯片或計(jì)算棒,這些設(shè)備已經(jīng)在市場(chǎng)上逐漸成熟。與 USB 挖礦不同的是,計(jì)算芯片是做全節(jié)點(diǎn)驗(yàn)證的硬件補(bǔ)足,并非計(jì)算挖礦具體過程中需要的設(shè)備。
4.現(xiàn)有顯卡礦廠需要的硬件改裝措施
對(duì)于一個(gè)現(xiàn)有顯卡算力的礦廠,特別是有高端顯卡的礦廠,Cortex 提供改造咨詢服務(wù)和整體技術(shù)解決方案,使得礦廠具有和世界一流 AI 公司同等水平的智能計(jì)算中心,硬件性價(jià)比將遠(yuǎn)遠(yuǎn)超過現(xiàn)有商用 GPU 云,多中心化的礦廠有機(jī)會(huì)出售算力給算法提供者,或者以合作的方式生成數(shù)據(jù)模型,和世界一流的互聯(lián)網(wǎng)、AI 公司同場(chǎng)競(jìng)技。具體的改造策略有:
? 主板和 CPU 的定制策略,滿足多路 PCI-E 深度學(xué)習(xí)的數(shù)據(jù)傳輸帶寬
? 萬兆交換機(jī)和網(wǎng)卡的硬件解決方案
? 存儲(chǔ)硬件和帶寬解決方案
? 相關(guān)軟件在挖 Cortex 主鏈、挖其他競(jìng)爭顯卡幣和鏈下深度學(xué)習(xí)訓(xùn)練之間自動(dòng)切換
? 相關(guān)的手機(jī)端監(jiān)控收益、手動(dòng)切換等管理軟件
5. 手機(jī)設(shè)備和物聯(lián)網(wǎng)設(shè)備挖礦和計(jì)算
平衡異構(gòu)計(jì)算芯片 (CPU)、顯示芯片 (GPU)、FPGA 與 ASIC 計(jì)算模塊的算力收益比例,從而更加去中心的進(jìn)行工作量證明挖礦,一直是主鏈設(shè)計(jì)的難點(diǎn),特別是能夠讓算力相對(duì)弱小的設(shè)備,比如手機(jī)和 IoT 設(shè)備參與其中。同時(shí),由于目前市場(chǎng)上的手機(jī)設(shè)備已經(jīng)出現(xiàn)了支持 AI 計(jì)算的芯片或者計(jì)算庫、基于手機(jī) AI 芯片的計(jì)算框架也可以參與智能推斷,只不過全節(jié)點(diǎn)的數(shù)據(jù)模型相對(duì)較大,移動(dòng)端需要定制對(duì)可執(zhí)行數(shù)據(jù)模型的規(guī)模做篩選。Cortex 主鏈將發(fā)布 Android 和 iOS 客戶端 App:
? 閑置中具有顯卡算力的設(shè)備能通過 SoC 、ARM 架構(gòu)的 CPU/GPU 參與挖礦,比如市場(chǎng)中,電視盒子的顯卡性能其實(shí)已經(jīng)很不錯(cuò)了,而 90% 時(shí)間基本都在閑置
? 用戶手機(jī)在上班充電和睡覺充電中都可以參與挖礦,只要算法上讓手機(jī)的顯卡得到公平的收益競(jìng)爭力
? 手機(jī)或其他配有 AI 芯片的設(shè)備,能夠自動(dòng)在主鏈出塊和執(zhí)行智能推斷之間切換
手機(jī)端的推斷能力可能會(huì)受到芯片供應(yīng)商的軟件技術(shù)限制,不同軟件供應(yīng)商正在封裝不同的計(jì)算協(xié)議,Cortex 將負(fù)責(zé)抽象層接口的編寫和輕智能客戶端的篩選。
代幣模型
1.Cortex Coin (CTXC)
模型提交者的獎(jiǎng)勵(lì)收益
傳統(tǒng)的區(qū)塊鏈對(duì)于每個(gè)打包區(qū)塊的獎(jiǎng)勵(lì)是直接支付給礦工的,Cortex 為了激勵(lì)開發(fā)者提交更加豐富和優(yōu)秀的模型,調(diào)用合約需要支付的 Endorphin 不僅僅會(huì)分配給幫助區(qū)塊打包的節(jié)點(diǎn)礦工,還會(huì)支付給模型的提供者。費(fèi)用的收取比例采用市場(chǎng)博弈價(jià)格,類似以太坊中 Gas 的機(jī)制。
模型提交者成本支出
為了防止模型提交者進(jìn)行過度的提交和存儲(chǔ)攻擊 - 比如,隨意提交幾乎不可用的模型以及頻繁提交相同模型從而占用存儲(chǔ)資源 - 每個(gè)模型提交者必須支付存儲(chǔ)費(fèi)用。這樣可以促使模型提交者提交更加優(yōu)秀的模型。這樣調(diào)用者更多,模型提交者收益更大。
模型復(fù)雜度和 Endorphin 的耗費(fèi)
Endorphin 用來衡量在推斷過程中將數(shù)據(jù)模型帶入合約時(shí),計(jì)算所耗費(fèi)的虛擬機(jī)級(jí)別硬件計(jì)算資源,Endorphin 的耗費(fèi)正比于模型大小,同時(shí) Cortex 也為模型的參數(shù)大小設(shè)置了 8GB 的上限,對(duì)應(yīng)最多約 20 億個(gè) Float32 的參數(shù)。
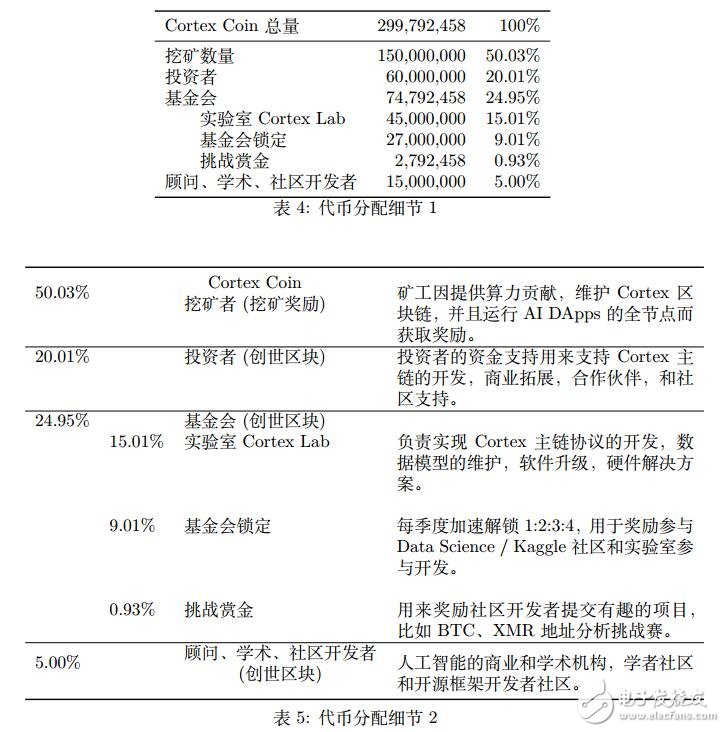
2.代幣分配
Cortex Coin (CTXC) 數(shù)量總共為 299,792,4582個(gè)。其中 60,000,000 (20.01%) 分配給早期投資者。
3 代幣發(fā)行曲線
Cortex Coin 發(fā)行總量為 299,792,458 個(gè),其中 150,000,000 的 Cortex Coin 可以通過挖礦獲得。
第一個(gè) 4 年 75,000,000
第二個(gè) 4 年 37,500,000
第三個(gè) 4 年 18,750,000
第四個(gè) 4 年 9,375,000
第五個(gè) 4 年 4,687,500
…
依此類推,發(fā)行量按每四年減半。

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論