 電子發燒友App
電子發燒友App


Neuromorphic處理器
這就是一個叫做NeuRAM3的項目。屆時,他們的芯片會擁有超低功耗、尺寸和高度可配置的神經架構。他們的目標是較之傳統方案,打造一個能將功耗降低50倍的產品。
據介紹,這個方案包含了基于FD-SOI工藝的整體集成的3D技術,另外還用到的RRAM來做突觸元素。在NeuRAM3項目之下,這個新型的混合信號多核神經形態芯片設備較之IBM的TrueNorth,能明顯降低功耗。
據介紹,全新的 NVIDIA Pascal? 架構讓 Tesla P100 能夠為 HPC 和超大規模工作負載提供超高的性能。憑借每秒超過 20 萬億次的 FP16 浮點運算性能,經過優化的 Pascal 為深度學習應用程序帶來了令人興奮的新可能。
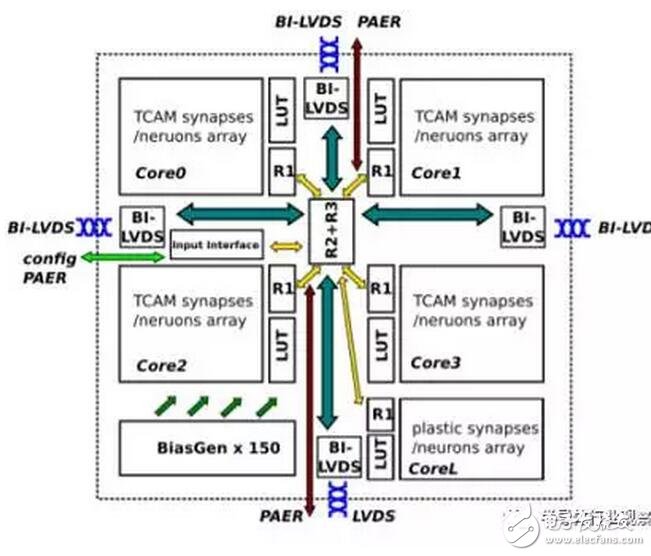
Neuromorphic處理器
而通過加入采用 HBM2 的 CoWoS(晶圓基底芯片)技術,Tesla P100 將計算和數據緊密集成在同一個程序包內,其內存性能是上一代解決方案的 3 倍以上。這讓數據密集型應用程序的問題解決時間實現了跨時代的飛躍。
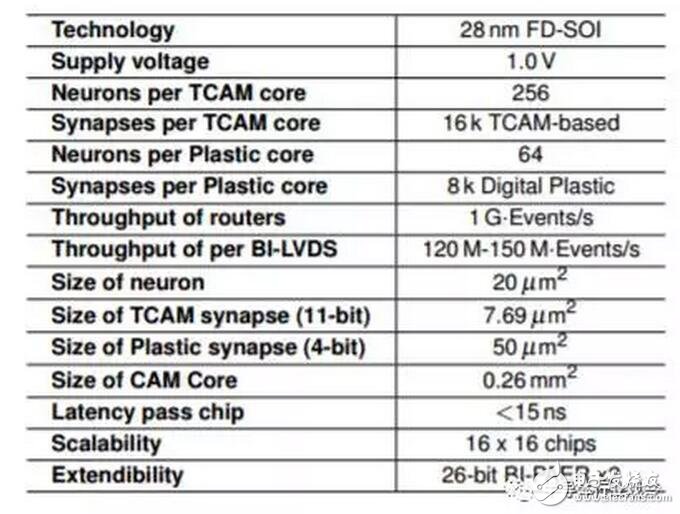
Neuromorphic處理器的基本參數
再者,因為搭載了 NVIDIA NVLink? 技術, Tesla P100的快速節點可以顯著縮短為具備強擴展能力的應用程序提供解決方案的時間。采用 NVLink 技術的服務器節點可以 5 倍的 PCIe 帶寬互聯多達八個 Tesla P100。這種設計旨在幫助解決擁有極大計算需求的 HPC 和深度學習領域的全球超級重大挑戰。
(2)Intel
在今年十一月。Intel公司發布了一個叫做Nervana的AI處理器,他們宣稱會在明年年中測試這個原型。如果一切進展順利,Nervana芯片的最終形態會在2017年底面世。這個芯片是基于Intel早前購買的一個叫做Nervana的公司。按照Intel的人所說,這家公司是地球上第一家專門為AI打造芯片的公司。
Intel公司披露了一些關于這個芯片的一些細節,按照他們所說,這個項目代碼為“Lake Crest”,將會用到Nervana Engine 和Neon DNN相關軟件。。這款芯片可以加速各類神經網絡,例如谷歌TensorFlow框架。芯片由所謂的“處理集群”陣列構成,處理被稱作“活動點”的簡化數學運算。相對于浮點運算,這種方法所需的數據量更少,因此帶來了10倍的性能提升。
Lake Crest利用私有的數據連接創造了規模更大、速度更快的集群,其拓撲結構為圓環形或其他形式。這幫助用戶創造更大、更多元化的神經網絡模型。這一數據連接中包含12個100Gbps的雙向連接,其物理層基于28G的串并轉換。
這一2.5D芯片搭載了32GB的HBM2內存,內存帶寬為8Tbps。芯片中沒有緩存,完全通過軟件去管理片上存儲。
英特爾并未透露這款產品的未來路線圖,僅僅表示計劃發布一個名為Knights Crest的版本。該版本將集成未來的至強處理器和Nervana加速處理器。預計這將會支持Nervana的集群。不過英特爾沒有透露,這兩大類型的芯片將如何以及何時實現整合。
至于整合的版本將會有更強的性能,同時更易于編程。目前基于圖形處理芯片(GPU)的加速處理器使編程變得更復雜,因為開發者要維護單獨的GPU和CPU內存。
據透露,到2020年,英特爾將推出芯片,使神經網絡訓練的性能提高100倍。一名分析師表示,這一目標“極為激進”。毫無疑問,英特爾將迅速把這一架構轉向更先進的制造工藝,與已經采用14納米或16納米FinFET工藝的GPU展開競爭。
(3)IBM
百年巨人IBM,在很早以前就發布過wtson,現在他的人工智能機器早就投入了很多的研制和研發中去。而在去年,他也按捺不住,投入到類人腦芯片的研發,那就是TrueNorth。
TrueNorth是IBM參與DARPA的研究項目SyNapse的最新成果。SyNapse全稱是Systems of Neuromorphic Adaptive Plastic Scalable Electronics(自適應可塑可伸縮電子神經系統,而SyNapse正好是突觸的意思),其終極目標是開發出打破馮?諾依曼體系的硬件。
這種芯片把數字處理器當作神經元,把內存作為突觸,跟傳統馮諾依曼結構不一樣,它的內存、CPU和通信部件是完全集成在一起。因此信息的處理完全在本地進行,而且由于本地處理的數據量并不大,傳統計算機內存與CPU之間的瓶頸不復存在了。同時神經元之間可以方便快捷地相互溝通,只要接收到其他神經元發過來的脈沖(動作電位),這些神經元就會同時做動作。
2011年的時候,IBM首先推出了單核含256 個神經元,256×256 個突觸和 256 個軸突的芯片原型。當時的原型已經可以處理像玩Pong游戲這樣復雜的任務。不過相對來說還是比較簡單,從規模上來說,這樣的單核腦容量僅相當于蟲腦的水平。
不過,經過3年的努力,IBM終于在復雜性和使用性方面取得了突破。4096個內核,100萬個“神經元”、2.56億個“突觸”集成在直徑只有幾厘米的方寸(是2011年原型大小的1/16)之間,而且能耗只有不到70毫瓦,IBM的集成的確令人印象深刻。
這樣的芯片能夠做什么事情呢?IBM研究小組曾經利用做過DARPA 的NeoVision2 Tower數據集做過演示。它能夠實時識別出用30幀每秒的正常速度拍攝自斯坦福大學胡佛塔的十字路口視頻中的人、自行車、公交車、卡車等,準確率達到了80%。相比之下,一臺筆記本編程完成同樣的任務用時要慢100倍,能耗卻是IBM芯片的1萬倍。
跟傳統計算機用FLOPS(每秒浮點運算次數)衡量計算能力一樣,IBM使用SOP(每秒突觸運算數)來衡量這種計算機的能力和能效。其完成460億SOP所需的能耗僅為1瓦—正如文章開頭所述,這樣的能力一臺超級計算機,但是一塊小小的助聽器電池即可驅動。
通信效率極高,從而大大降低能耗這是這款芯片最大的賣點。TrueNorth的每一內核均有256個神經元,每一個神經有分別都跟內外部的256個神經元連接。
(4)Google
其實在Google上面,我是很糾結的,這究竟是個新興勢力,還是傳統公司。但考慮到Google已經那么多年了,我就把他放在傳統里面吧。雖然傳統也是很新的。而谷歌的人工智能相關芯片就是TPU。也就是Tensor Processing Unit。
TPU是專門為機器學習應用而設計的專用芯片。通過降低芯片的計算精度,減少實現每個計算操作所需的晶體管數量,從而能讓芯片的每秒運行的操作個數更高,這樣經過精細調優的機器學習模型就能在芯片上運行的更快,進而更快的讓用戶得到更智能的結果。Google將TPU加速器芯片嵌入電路板中,利用已有的硬盤PCI-E接口接入數據中心服務器中。
據Google 資深副總Urs Holzle 透露,當前Google TPU、GPU 并用,這種情況仍會維持一段時間,但也語帶玄機表示,GPU 過于通用,Google 偏好專為機器學習設計的芯片。GPU 可執行繪圖運算工作,用途多元;TPU 屬于ASIC,也就是專為特定用途設計的特殊規格邏輯IC,由于只執行單一工作,速度更快,但缺點是成本較高。至于CPU,Holzle 表示,TPU 不會取代CPU,研發TPU 只是為了處理尚未解決的問題。但是他也指出,希望芯片市場能有更多競爭。
如果AI算法改變了(從邏輯上講隨著時間的推移算法應該會改變),你是不是想要一款可以重新編程的芯片,以適應這些改變?如果情況是這樣的,另一種芯片適合,它就是FPGA(現場可編程門陣列)。FPGA可以編程,和ASIC不同。微軟用一些FPGA芯片來增強必應搜索引擎的AI功能。我們很自然會問:為什么不使用FPGA呢?
谷歌的回答是:FPGA的計算效率比ASIC低得多,因為它可以編程。TPU擁有一個指令集,當TensorFlow程序改變時,或者新的算法出現時,它們可以在TPU上運行。
現在問題的答案開始浮現。在谷歌看來,能耗是一個重要的考量標準,數據中心相當巨大,建設在世界各地,包括芬蘭和***。能耗越高,運營的成本就越高,隨著時間的推移實際消耗的金錢會成倍增長。谷歌工程師對比了FPGA和ASIC的效率,最終決定選擇ASIC。
問題的第二部分與TPU的指令集有關。這是一套基本的命令,它以硬編碼形式存在于芯片中,能夠識別、執行;在芯片世界,指令集是計算機運行的基礎。
在開發TPU指令集時,它是專門用來運行TensorFlow的,TensorFlow是一個開源軟件庫,針對的是AI應用的開發。谷歌認為,如果AI有必要在底層進行改變,極可能發生在軟件上,芯片應該具備彈性,以適應這種改變。
TPU架構的技術細節讓許多了解芯片的人驚奇。Anandtech的Joshua Ho有一個有趣的理論:TPU更加類似于第三類芯片,也就是所謂的數字信號處理器(Digital Signal Processor)。
(5)微軟
這是又一個由軟轉硬的代表,微軟蟄伏六年,打造出了一個迎接AI世代的芯片。那就是Project Catapult。
據介紹,這個FPGA 目前已支持微軟Bing,未來它們將會驅動基于深度神經網絡——以人類大腦結構為基礎建模的人工智能——的新搜索算法,在執行這個人工智能的幾個命令時,速度比普通芯片快上幾個數量級。有了它,你的計算機屏幕只會空屏 23 毫秒而不是 4 秒。
在第三代原型中,芯片位于每個服務器的邊緣,直接插入到網絡,但仍舊創造任何機器都可接入的 FPGA 池。這開始看起來是 Office 365 可用的東西了。最終,Project Catapult 準備好上線了。另外,Catapult 硬件的成本只占了服務器中所有其他的配件總成本的 30%,需要的運轉能量也只有不到 10%,但其卻帶來了 2 倍原先的處理速度。








 工商網監
工商網監
評論