 電子發燒友App
電子發燒友App


1.認識zookeeper
1.1 zookeeper是什么?
ZooKeeper是源代碼開放的分布式協調服務,由雅虎創建,是Google Chubby的開源實現。ZooKeeper是一個高性能的分布式數據一致性解決方案,它將那些復雜的、容易出錯的分布式一致性服務封裝起來,構成一個高效可靠的原語集,并提供一系列簡單易用的接口給用戶使用;
知識要點:
1、源代碼開放
2、是分布式協調服務,它解決分布式數據一致性問題
A:順序一致性 B:原子性 C:單一視圖
D:可靠性 E:實時性
3、高性能
4、我們可以通過調用ZooKeeper提供的接口來解決一些分布式應用中的實際問題
1.2 zookeeper的應用場景
1.2.1.數據發布/訂閱
數據發布/訂閱 顧名思義就是一方把數據發布出來,另一方通過某種手段可以得到這些數據
通常數據訂閱有兩種方式:推模式和拉模式,推模式一般是服務器主動向客戶端推送信息, 拉模式是客戶端主動去服務器獲取數據(通常是采用定時輪詢的方式),
ZK采用兩種方式相結合
發布者將數據發布到ZK集群節點上,訂閱者通過一定的方法告訴服務器,我對哪個節點的數據感興趣,那服務器在這些節點的數據發生變化時,就通知客戶端,客戶端得到通知后可以去服務器獲取數據信息
1.2.2.負載均衡
步驟:
1、首先DB在啟動的時候先把自己在ZK上注冊成一個臨時節點,ZK的節點后面我們會講到有兩種,一種是永久節點,一類是臨時節點臨時節點在服務器出現問題的時候,節點會自動的從ZK上刪除,那么這樣ZK上的服務器列表就是最新的可用的列表
2、客戶端在需要讀寫數據庫的時候首先它去ZooKeeper得到所有可用的DB的連接信息(一張列表)
3、客戶端隨機選擇一個與之建立連接
4、當客戶端發現連接不可用的時候可再次從ZK上獲取可用的DB連接信息,當然也可以在剛獲取的那個列表里移除掉不可用的連接后再隨機選擇一個DB與之連接
1.2.3.命名服務
顧名思義,就是提供名稱的服務,例如數據庫表格ID,一般用得比較多的有兩種ID,一種是自動增長的ID,一種是UUID(9291d71a-0354-4d8e-acd8-64f7393c64ae),兩種ID各自都有缺陷,自動增長的ID局限在單庫單表中使用,不能在分布式中使用,UUID可以在分布式中使用但是由于ID沒有規律難于理解,我們可以借用ZK來生成一個順序增長的,可以在集群環境下使用的,命名易于理解的ID
1.2.4.分布式協調/通知
心跳檢測
在分布式系統中,我們常常需要知道某個機器是否可用,傳統的開發中,可以通過Ping某個主機來實現,Ping得通說明對方是可用的,相反是不可用的,ZK 中我們讓所有的機其都注冊一個臨時節點,我們判斷一個機器是否可用,我們只需要判斷這個節點在ZK中是否存在就可以了,不需要直接去連接需要檢查的機器 ,降低系統的復雜度
1.3 zookeeper的優勢
1、源代碼開放
2、已經被證實是高性能,易用穩定的工業級產品
3、有著廣泛的應用:Hadoop,HBase,Storm,Solr
2.Zookeeper中的基本概念
2.1 集群角色
Leader,Follower,Observer
Leader服務器是整個Zookeeper集群工作機制中的核心
Follower服務器是Zookeeper集群狀態的跟隨者
Observer服務器充當一個觀察者的角色
Leader,Follower 設計模式
Observer 觀察者設計模式
2.2 會話
會話是指客戶端和ZooKeeper服務器的連接,ZooKeeper中的會話叫Session,客戶端靠與服務器建立一個TCP的長連接
來維持一個Session,客戶端在啟動的時候首先會與服務器建立一個TCP連接,通過這個連接,客戶端能夠通過心跳檢測與服務器保持有效的會話,也能向ZK服務器發送請求并獲得響應
2.3 數據節點
Zookeeper中的節點有兩類
1.集群中的一臺機器稱為一個節點
2.數據模型中的數據單元Znode,分為持久節點和臨時節點
Zookeeper的數據模型是一棵樹,樹的節點就是Znode,Znode中可以保存信息
2.4 版本
版本類型說明
version當前數據節點數據內容的版本號
cversion當前數據節點子節點的版本號
aversion當前數據節點ACL變更版本號
悲觀鎖和樂觀鎖
悲觀鎖又叫悲觀并發鎖,是數據庫中一種非常嚴格的鎖策略,具有強烈的排他性,能夠避免不同事務對同一數據并發更新造成的數據不一致性,在上一個事務沒有完成之前,下一個事務不能訪問相同的資源,適合數據更新競爭非常激烈的場景
相比悲觀鎖,樂觀鎖使用的場景會更多,悲觀鎖認為事務訪問相同數據的時候一定會出現相互的干擾,所以簡單粗暴的使用排他訪問的方式,而樂觀鎖認為不同事務訪問相同資源是很少出現相互干擾的情況,因此在事務處理期間不需要進行并發控制,當然樂觀鎖也是鎖,它還是會有并發的控制!對于數據庫我們通常的做法是在每個表中增加一個version版本字段,事務修改數據之前先讀出數據,當然版號也順勢讀取出來,然后把這個讀取出來的版本號加入到更新語句的條件中,比如,讀取出來的版本號是1,我們修改數據的語句可以這樣寫,update 某某表 set 字段一=某某值 where id=1 and version=1,那如果更新失敗了說明以后其他事務已經修改過數據了,那系統需要拋出異常給客戶端,讓客戶端自行處理,客戶端可以選擇重試
2.5 watcher
事件監聽器
ZooKeeper允許用戶在指定節點上注冊一些Watcher,當數據節點發生變化的時候,ZooKeeper服務器會把這個變化的通知發送給感興趣的客戶端
2.6 ACL權限控制
ACL是Access Control Lists 的簡寫, ZooKeeper采用ACL策略來進行權限控制,有以下權限:
CREATE:創建子節點的權限
READ:獲取節點數據和子節點列表的權限
WRITE:更新節點數據的權限
DELETE:刪除子節點的權限
ADMIN:設置節點ACL的權限
3.Zookeeper集群環境的搭建
3.1集群環境
1. 準備Java運行環境,JDK
2.下載ZooKeeper安裝包
①進入apache官網:
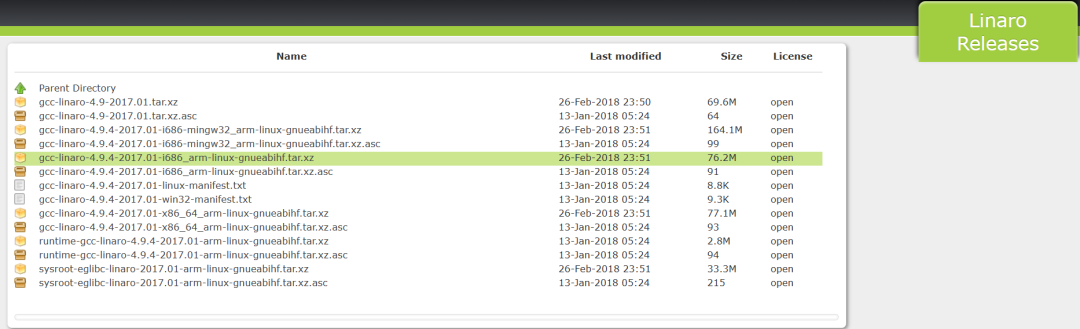
②按如下圖操作
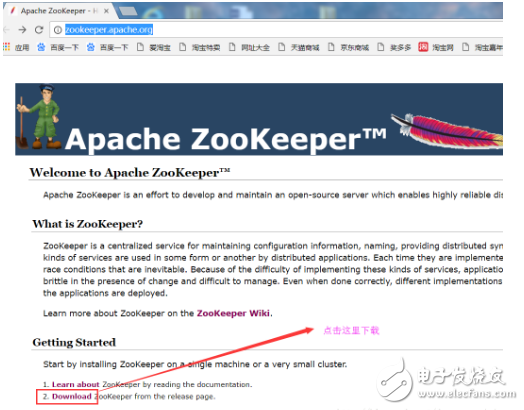
③按如下圖操作

④按如下圖操作

?
⑤按如下圖操作
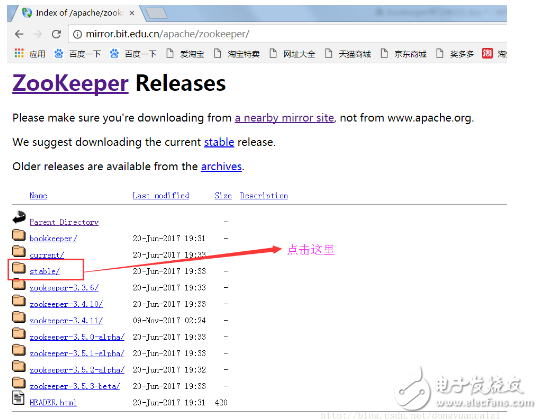
?
⑥按如下圖操作、
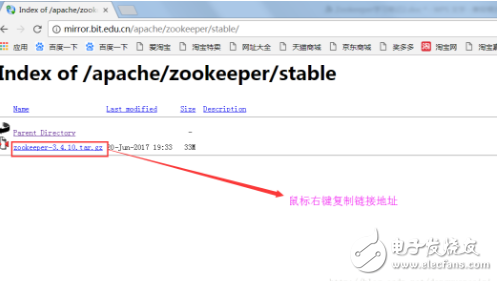
?
⑦通過命令:cd /opt/ 進入到opt目錄下,再通過
wget
下載到該目錄下,如下圖

?
⑧通過命令 tar -zxvf zookeeper-3.4.10.tar.gz 命令解壓zookeeper-3.4.10.tar.gz 壓縮文件
再通過cp zookeeper-3.4.10 -C zookeeper 將解壓后的zookeeper-3.4.10名稱改zookeeper
如下圖

3.配置文件zoo.cfg
⑨通過命令:cd zookeeper/conf 進入到zookeeper的配置文件所在的目錄,會看到如下圖的一個文件

通過命令 :cp zoo_sample.cfg zoo.cfg 將zoo_sample.cfg文件復制一份,如下圖

再通過命令:vim zoo.cfg 打開剛復制的文件,編輯里面的內容如下圖,之后保存退出
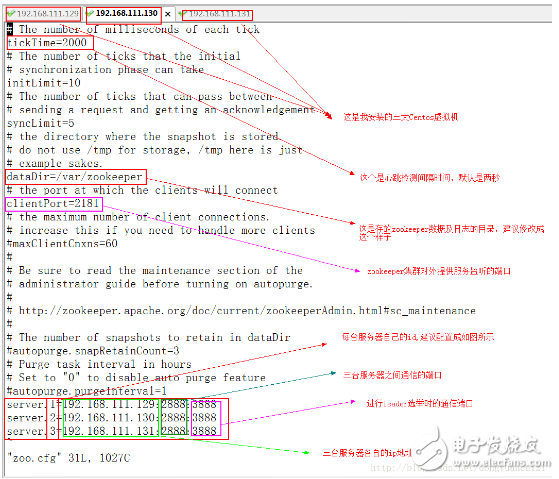
⑩通過命令 scp zoo.cfg [email protected]:/opt/zookeeper/conf/
scp zoo.cfg [email protected]:/opt/zookeeper/conf/
將修改好的配置文件復制到其余兩臺服務器相同的目錄下(復制過程中需要輸入root用戶的密碼)
4.創建myid
再通過命令 mkdir /var/zookeeper -p 創建在上面配置的存放數據的目錄
切換到這個目錄(cd /var/zookeeper),再通過命令 vim myid 創建并打開myid文件,在第一行輸入1,保存退出,如下圖
5.配置其他機器
再打開其余兩臺服務器,重復剛才創建目錄(mkdir /var/zookeeper -p,vim myid)的操作,
里面分別輸入2和3,保存退出。到這里整個zookeeper集群的配置就完成了
6.啟動服務器
①通過命令 cd /opt/zookeeper/bin 切換到zookeeper服務的bin目錄,如下圖
?
②通過命令 ./zkServer.sh start 啟動 第一臺服務器,再通過同樣的命令啟動其余一臺或兩臺服務器
②通過命令 yum install telnet 安裝telnet 軟件,其余兩臺服務器執行同樣的操作
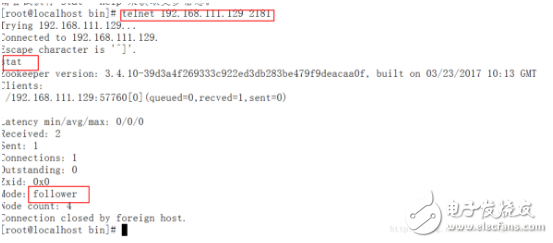
③通過命令 telnet 192.168.111.129 2181 連接第一臺服務器
再通過命令 stat 查看狀態如下圖,是follower服務器
?
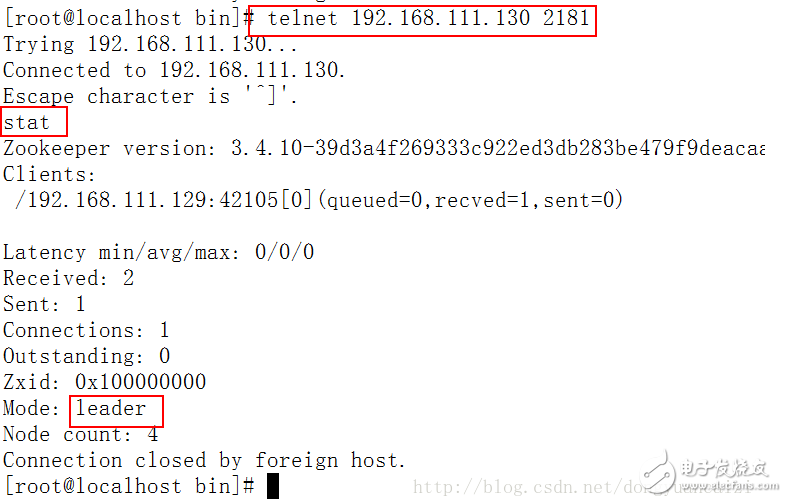
④ 通過命令 telnet 192.168.111.130 2181連接第一臺服務器
再通過命令 stat 查看狀態如下圖,是leader服務器
?
⑤如果這期間有無法連接主機的異常
需要通過命令chkconfig iptables off 關閉linux 操作系統的防火墻,其余兩臺服務器執行同樣的操作,重啟三臺讀取器,重啟zookeeper服務,就會正常
3.2單機環境
跟集群模式的配置基本一致,zoo.cfg稍有區別
3.3偽集群環境
跟集群模式的配置基本一致,zoo.cfg稍有區別











 工商網監
工商網監
評論