 電子發燒友App
電子發燒友App


人工智能(Artificial Intelligence,縮寫為AI)是對人的意識、思維過程進行模擬的一門新學科。如今,人工智能從虛無縹緲的科學幻想變成了現實。計算機科學家們在人工智能的技術核心--機器學習(Machine Learning)和深度學習(Deep Learning)領域上已經取得重大的突破,機器被賦予強大的認知和預測能力。回顧歷史,在1997年,IBM“深藍”戰勝國際象棋冠軍卡斯帕羅夫;在2011年,具備機器學習能力的IBM Waston參加綜藝節目贏得100萬美金;在2016年,利用深度學習訓練的Aplphago成功擊敗人類世界冠軍。種種事件表明機器也可以像人類一樣思考,甚至比人類做得更好。
目前,人工智能在金融、醫療、制造等行業得到了廣泛應用,全球投資從2012年的5.89億美元猛增至2016年50多億美元。麥肯錫預計,到2025年人工智能應用市場的總值將達到1270億美元。與此同時,麥肯錫通過對2016年人工智能市場的投資進行深入分析,發現有將近60%的資金并購圍繞機器學習來布局。其中,基于軟件的機器學習初創公司比基于機器的機器人公司更受投資歡迎。從2013 年到2016 年,這一領域的投資復合年均增長率達到約80%。由此可見,機器學習已經成為目前人工智能技術發展的主要方向。
二、機器學習與人工智能、深度學習的關系
在介紹機器學習之前,先需要對人工智能、機器學習和深度學習三者之間的關系進行梳理。目前業界最常見的劃分是:
人工智能是使用與傳統計算機系統完全不同的工作模式,它可以依據通用的學習策略,讀取海量的“大數據”,并從中發現規律、聯系和洞見,因此人工智能能夠根據新數據自動調整,而無需重設程序。
機器學習是人工智能研究的核心技術,在大數據的支撐下,通過各種算法讓機器對數據進行深層次的統計分析以進行“自學”;利用機器學習,人工智能系統獲得了歸納推理和決策能力;而深度學習更將這一能力推向了更高的層次。
深度學習則是機器學習算法的一種,隸屬于人工神經網絡體系,現在很多應用領域中性能最佳的機器學習都是基于模仿人類大腦結構的神經網絡設計而來的,這些計算機系統能夠完全自主地學習、發現并應用規則。相比較其他方法,在解決更復雜的問題上表現更優異,深度學習是可以幫助機器實現“獨立思考”的一種方式。
總而言之,人工智能是社會發展的重要推動力,而機器學習,尤其是深度學習技術就是人工智能發展的核心,它們三者之間是包含與被包含的關系。如圖1所示。
圖1 人工智能、機器學習、深度學習之間的關系
三、機器學習:實現人工智能的高效方法
從廣義上來說,機器學習是一種能夠賦予機器學習的能力以此讓它完成直接編程無法完成的功能的方法。但從實踐的意義上來說,機器學習是一種通過利用數據,訓練出模型,然后使用模型預測的一種方法。國外有些學者對機器學習進行了定義大同小異,有學者認為,機器學習是對能通過經驗自動改進的計算機算法的研究;也有學者認為,機器學習是指利用數據或以往的經驗,以此優化計算機程序的性能標準。由此可知,機器學習是通過經驗或數據來改進算法的研究,通過算法讓機器從大量歷史數據中學習規律,得到某種模式并利用此模型預測未來,機器在學習的過程中,處理的數據越多,預測結果就越精準。
機器學習在人工智能的研究中具有十分重要的地位。它是人工智能的核心,是使計算機具有智能的根本途徑,其應用遍及人工智能的各個領域。從20世紀50年代人們就開始了對機器學習的研究,從最初的基于神經元模型以及函數逼近論的方法研究,到以符號演算為基礎的規則學習和決策樹學習的產生,以及之后的認知心理學中歸納、解釋、類比等概念的引入,至最新的計算學習理論和統計學習的興起,機器學習一直都在相關學科的實踐應用中起著主導作用。現在已取得了不少成就,并分化出許多研究方向,主要有符號學習、連接學習和統計學習等。
(一)機器學習的發展歷程
機器學習發展過程大體可分為以下四個階段:
1.50年代中葉到60年代中葉
在這個時期,所研究的是“沒有知識”的學習,即“無知”學習;其研究目標是各類自組織系統和自適應系統;其主要研究方法是不斷修改系統的控制參數以改進系統的執行能力,不涉及與具體任務有關的知識。指導本階段研究的理論基礎是早在40年代就開始研究的神經網絡模型。隨著電子計算機的產生和發展,機器學習的實現才成為可能。這個階段的研究導致了模式識別這門新科學的誕生,同時形成了機器學習的二種重要方法,即判別函數法和進化學習。塞繆爾的下棋程序就是使用判別函數法的典型例子。不過,這種脫離知識的感知型學習系統具有很大的局限性。無論是神經模型、進化學習或是判別函數法,所取得的學習結果都很有限,遠不能滿足人們對機器學習系統的期望。在這個時期,我國研制了數字識別學習機。
2.60年代中葉至70年代中葉
本階段的研究目標是模擬人類的概念學習過程,并采用邏輯結構或圖結構作為機器內部描述。機器能夠采用符號來描述概念(符號概念獲取),并提出關于學習概念的各種假設。本階段的代表性工作有溫斯頓(Winston)的結構學習系統和海斯·羅思(Hayes Roth)等的基于邏輯的歸納學習系統。雖然這類學習系統取得較大的成功,但只能學習單一概念,而且未能投入實際應用。此外,神經網絡學習機因理論缺陷未能達到預期效果而轉入低潮。因此,使那些對機器學習的進展抱過大希望的人們感到失望。他們稱這個時期為“黑暗時期”。
3.70年代中葉至80年代中葉
在這個時期,人們從學習單個概念擴展到學習多個概念,探索不同的學習策略和各種學習方法。機器的學習過程一般都建立在大規模的知識庫上,實現知識強化學習。尤其令人鼓舞的是,本階段已開始把學習系統與各種應用結合起來,并取得很大的成功,促進機器學習的發展。在出現第一個專家學習系統之后,示例歸約學習系統成為研究主流,自動知識獲取成為機器學習的應用研究目標。1980年,在美國的卡內基梅隆大學(CMU)召開了第一屆機器學習國際研討會,標志著機器學習研究已在全世界興起。此后,機器歸納學習進入應用。1986年,國際雜志《機器學習》(Machine Learning)創刊,迎來了機器學習蓬勃發展的新時期。70年代末,中國科學院自動化研究所進行質譜分析和模式文法推斷研究,表明我國的機器學習研究得到恢復。1980年西蒙來華傳播機器學習的火種后,我國的機器學習研究出現了新局面。
4.機器學習最新階段始于1986年
一方面,由于神經網絡研究的重新興起,對連接機制學習方法的研究方興未艾,機器學習的研究已經在全世界范圍內出現新的高潮,機器學習的基本理論和綜合系統的研究得到加強和發展。另一方面,對實驗研究和應用研究得到前所未有的重視,機器學習有了更強的研究手段和環境。從而出現了符號學習、神經網絡學習、進化學習和基于行為主義(actionism)的強化學習等百家爭鳴的局面。
圖2 ?機器學習的發展歷程
(二)機器學習的結構模型
機器學習的本質就是算法。算法是用于解決問題的一系列指令。程序員開發的用于指導計算機進行新任務的算法是我們今天看到的先進數字世界的基礎。計算機算法根據某些指令和規則,將大量數據組織到信息和服務中。機器學習向計算機發出指令,允許計算機從數據中學習,而不需要程序員做出新的分步指令。
機器學習的基本過程是給學習算法提供訓練數據。然后,學習算法基于數據的推論生成一組新的規則。這本質上就是生成一種新的算法,稱之為機器學習模型。通過使用不同的訓練數據,相同的學習算法可以生成不同的模型。從數據中推理出新的指令是機器學習的核心優勢。它還突出了數據的關鍵作用:用于訓練算法的可用數據越多,算法學習到的就越多。事實上,AI 的許多最新進展并不是由于學習算法的激進創新,而是現在積累了大量的可用數據。
圖3 ?機器學習的結構模型
(三)機器學習的工作方式
1.選擇數據:首先將原始數據分成三組:訓練數據、驗證數據和測試數據;
2.數據建模:再使用訓練數據來構建使用相關特征的模型;
3.驗證模型:使用驗證數據輸入到已經構建的數據模型中;
4.測試模型:使用測試數據檢查被驗證的模型的性能表現;
5.使用模型:使用完全訓練好的模型在新數據上做預測;
6.調優模型:使用更多數據、不同的特征或調整過的參數來提升算法的性能表現。
圖4 機器學習的工作方式
(四)機器學習發展的關鍵基石:
(1)海量數據:人工智能的能量來源是穩定的數據流。機器學習可以通過海量數據來“訓練” 自己,才能開發新規則來完成日益復雜的任務。目前全球有超過30億人在線,約170 億個連接的設備或傳感器,產生了大量數據,而數據存儲成本的降低,使得這些數據易于被使用。
(2)超強計算:強大的計算機和通過互聯網連接遠程處理能力使可以處理海量數據的機器學習技術成為可能,具某媒體稱,ALPHGO之所以能在與對李世石的對決中取得歷史性的勝利,這與它硬件配置的1920個CPU和280個GPU超強運算系統密不可分,可見計算能力對于機器學習是至關重要的。
(3)優秀算法:在機器學習中,學習算法(learning algorithms)創建了規則,允許計算機從數據中學習,從而推論出新的指令(算法模型),這也是機器學習的核心優勢。新的機器學習技術,特別是分層神經網絡,也被稱為“深度學習”,啟發了新的服務,刺激了對人工智能這一領域其他方面的投資和研究。
圖5 ?機器學習的關鍵基石
(五)機器學習的算法分類
機器學習基于學習形式的不同通常可分為三類:
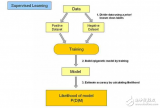
1.監督學習(Supervised Learning)
? ?給學習算法提供標記的數據和所需的輸出,對于每一個輸入,學習者都被提供了一個回應的目標。監督學習主要被應用于快速高效地教熟AI現有的知識,被用于解決分類和回歸的問題。常見的算法有:
(1)決策樹(Decision Trees):決策樹可看作一個樹狀預測模型,它通過把實例從根節點排列到某個葉子節點來分類實例,葉子節點即為實例所屬的分類。決策樹的核心問題是選擇分裂屬性和決策樹的剪枝。決策樹是一個決策支持工具,它用樹形的圖或者模型表示決策及其可能的后果,包括隨機事件的影響、資源消耗、以及用途。用于分析判斷有無貸款意向的決策樹示如圖 所示,從商業角度看,常用于基于規則的信用評估、賽馬結果預測等。
圖6 決策樹
(2)Adaboost算法:這是一種迭代算法,其核心思想是針對同一個訓練集訓練不同的分類器(弱分類器),然后把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。算法本身是改變數據分布實現的,它根據每次訓練集之中的每個樣本的分類是否正確,以及上次的總體分類的準確率,來確定每個樣本的權值。將修改權值的新數據送給下層分類器進行訓練,然后將每次訓練得到的分類器融合起來,作為最后的決策分類器。AdaBoost算法主要解決了:兩類問題、多類單標簽問題、多類多標簽問題、大類單標簽問題和回歸問題; 優點:學習精度明顯增加,并且不會出現過擬合問題,AdaBoost算法技術常用于人臉識別和目標跟蹤領域。
圖7 Adaboost
(3)人工神經網絡(Artificial Neural Network -ANN)算法:人工神經網絡是由大量處理單元互聯組成的非線性、自適應信息處理系統。它是在現代神經科學研究成果的基礎上提出的,試圖通過模擬大腦神經網絡處理、記憶信息的方式進行信息處理。人工神經網絡是并行分布式系統,采用了與傳統人工智能和信息處理技術完全不同的機理,克服了傳統的基于邏輯符號的人工智能在處理直覺、非結構化信息方面的缺陷,具有自適應、自組織和實時學習的特點。
圖8 人工神經網絡
(4)SVM(Support Vector Machine):SVM 法即支持向量機算法,由Vapnik等人于1995年提出,具有相對優良的性能指標。該方法是建立在統計學習理論基礎上的機器學習方法。 SVM是一種二分算法。假設在N維空間,有一組點,包含兩種類型,SVM生成a(N-1) 維的超平面,把這些點分成兩組。比如你有一些點在紙上面,這些點是線性分離的。SVM會找到一個直線,把這些點分成兩類,并且會盡可能遠離這些點。從規模看來,SVM(包括適當調整過的)解決的一些特大的問題有:廣告、人類基因剪接位點識別、基于圖片的性別檢測、大規模圖片分類,適用于新聞分類、手寫識別等應用。
圖9 支持向量機算法
(5)樸素貝葉斯(Naive Bayesian):貝葉斯法是一種在已知先驗概率與類條件概率的情況下的模式分類方法,待分樣本的分類結果取決于各類域中樣本的全體。樸素貝葉斯分類器基于把貝葉斯定理運用在特征之間關系的強獨立性假設上。優點:在數據較少的情況下仍然有效,可以處理多類別問題。缺點:對于輸入數據的準備方式較為敏感。適用數據類型:標稱型數據。現實生活中的應用例子:電子郵件垃圾副過濾、判定文章屬性分類、分析文字表達的內容含義和人臉識別、情感分析、消費者分類。
圖10 ?樸素貝葉斯算法
(6)K-近鄰(k-Nearest Neighbors,KNN):這是一種分類算法,其核心思想是如果一個樣本在特征空間中的k個最相鄰的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,并具有這個類別上樣本的特性。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。 kNN方法在類別決策時,只與極少量的相鄰樣本有關。由于kNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,kNN方法較其他方法更為適合。
圖11 ?K-近鄰算法
(7)邏輯回歸(Logistic Regression):這是一種分類算法,主要用于二分類問題。邏輯回歸是一種非常強大的統計方法,可以把有一個或者多個解釋變量的數據,建立為二項式類型的模型,通過用累積邏輯分布的邏輯函數估計概率,測量分類因變量和一個或多個獨立變量之間的關系。邏輯回歸是一種非線性回歸模型,相比于線性回歸,它多了一個sigmoid函數(或稱為Logistic函數)。通常,回歸在現實生活中的用途如下:信用評估、測量市場營銷的成功度、預測某個產品的收益、特定的某天是否會發生地震,路面交通流量分析、郵件過濾。
圖12 ?邏輯回歸算法
(8)隨機森林算法(Random Forest):隨機森林算法可以用于處理回歸、分類、聚類以及生存分析等問題,當用于分類或回歸問題時,它的主要思想是通過自助法重采樣,生成很多個樹回歸器或分類器。在機器學習中,隨機森林是一個包含多個決策樹的分類器, 并且其輸出的類別是由個別樹輸出的類別的眾數而定,常用于用戶流失分析、風險評估。
圖13 ?隨機森林算法
(9)線形回歸( Linear Regression):這是利用數理統計中回歸分析,來確定兩種或兩種以上變量間相互依賴的定量關系的一種統計分析方法,運用十分廣泛。線性回歸是回歸分析中第一種經過嚴格研究并在實際應用中廣泛使用的類型。這是因為線性依賴于其未知參數的模型比非線性依賴于其位置參數的模型更容易擬合,而且產生的估計的統計特性也更容易確定。
圖14 ?線形回歸算法
2.無監督學習(Unsupervised Learning)
給學習算法提供的數據是未標記的,并且要求算法識別輸入數據中的模式,主要是建立一個模型,用其試著對輸入的數據進行解釋,并用于下次輸入。現實情況下往往很多數據集都有大量的未標記樣本,有標記的樣本反而比較少。如果直接棄用,很大程度上會導致模型精度低。這種情況解決的思路往往是結合有標記的樣本,通過估計的方法把未標記樣本變為偽的有標記樣本,所以無監督學習比監督學習更難掌握。主要用于解決聚類和降維問題,常見的算法有:
(1)聚類算法:把一組對象分組化的任務,使得在同一組的對象比起其它組的對象,它們彼此更加相似。常用的聚類算法包括:
①K-means算法:這是典型的基于原型的目標函數聚類方法的代表,它是數據點到原型的某種距離作為優化的目標函數,利用函數求極值的方法得到迭代運算的調整規則。其優點是算法足夠快速、簡單,并且如果預處理數據和特征工程十分有效,那么該聚類算法將擁有極高的靈活性。缺點是該算法需要指定集群的數量,而K值的選擇通常都不是那么容易確定的。另外,如果訓練數據中的真實集群并不是類球狀的,那么K均值聚類會得出一些比較差的集群。
圖15 ?K-means算法
②Expectation Maximisation (EM):這是一種迭代算法,用于含有隱變量(latent variable)的概率參數模型的最大似然估計或極大后驗概率估計。EM算法的主要目的是提供一個簡單的迭代算法計算后驗密度函數,它的最大優點是簡單和穩定,但容易陷入局部最優。
圖16 ?EM算法
③Affinity Propagation 聚類:AP 聚類算法是一種相對較新的聚類算法,該聚類算法基于兩個樣本點之間的圖形距離(graph distances)確定集群。采用該聚類方法的集群擁有更小和不相等的大小。優點:該算法不需要指出明確的集群數量。缺點:AP 聚類算法主要的缺點就是訓練速度比較慢,并需要大量內存,因此也就很難擴展到大數據集中。另外,該算法同樣假定潛在的集群是類球狀的。
④層次聚類(Hierarchical Clustering):層次聚類是一系列基于以下概念的聚類算法:是通過對數據集按照某種方法進行層次分解,直到滿足某種條件為止。按照分類原理的不同,可以分為凝聚和分裂兩種方法。優點:層次聚類最主要的優點是集群不再需要假設為類球形。另外其也可以擴展到大數據集。缺點:有點像 K 均值聚類,該算法需要設定集群的數量。
圖17 ?層次聚類算法
⑤DBSCAN:這是一個比較有代表性的基于密度的聚類算法。與劃分和層次聚類方法不同,它將簇定義為密度相連的點的最大集合,能夠把具有足夠高密度的區域劃分為簇,并可在噪聲的空間數據庫中發現任意形狀的聚類。它將樣本點的密集區域組成一個集群。優點:DBSCAN 不需要假設集群為球狀,并且它的性能是可擴展的。此外,它不需要每個點都被分配到一個集群中,這降低了集群的異常數據。缺點:用戶必須要調整「epsilon」和「min_sample」這兩個定義了集群密度的超參數。DBSCAN 對這些超參數非常敏感。
圖18 DBSCAN算法
(2)降維算法:其主要特征是將數據從高維降低到低維層次,最大程度的保留了數據的信息。代表算法是:
①主要代表是主成分分析算法(PCA算法):主成分分析也稱主分量分析,旨在利用降維的思想,把多指標轉化為少數幾個綜合指標(即主成分),其中每個主成分都能夠反映原始變量的大部分信息,且所含信息互不重復。這種方法在引進多方面變量的同時將復雜因素歸結為幾個主成分,使問題簡單化,同時得到的結果更加科學有效的數據信息。
圖19 ?PCA算法
②局部線性嵌入(Locally linear embeddingLLE)LLE降維算法:一種非線性降維算法,它能夠使降維后的數據較好地保持原有 流形結構 。該算法是針對非線性信號特征矢量維數的優化方法,這種維數優化并不是僅僅在數量上簡單的約簡,而是在保持原始數據性質不變的情況下,將高維空間的信號映射到低維空間上,即特征值的二次提取。
圖20 ?LLE降維算法
3.強化學習(Reinforcement Learning)
? ? 該算法與動態環境相互作用,把環境的反饋作為輸入,通過學習選擇能達到其目標的最優動作。強化學習這一方法背后的數學原理與監督/非監督學習略有差異。監督/非監督學習更多地應用了統計學,而強化學習更多地結合了離散數學、隨機過程這些數學方法。常見的算法有:
①TD(λ)算法:TD(temporal differenee)學習是強化學習技術中最主要的學習技術之一.TD學習是蒙特卡羅思想和動態規劃思想的結合,即一方面TD算法在不需要系統模型情況下可以直接從agent經驗中學習;另一方面TD算法和動態規劃一樣,利用估計的值函數進行迭代。
圖21 ?TD(λ)算法
②Q_learning算法:Q_learning學習是一種模型無關的強化學習算法 ,又稱為離策略TD學習(off-policy TD).不同于TD算法,Q_learning迭代時采用狀態_動作對的獎賞和Q (s,a)作為估計函數,在Agent每一次學習迭代時都需要考察每一個行為,可確保學習過程收斂。
圖22 ? Q_learning算法
(六)機器學習過程舉例說明
所謂機器學習過程,是指觀察有n個樣本數據組成的集合,并根據這些數據來預測未知數據的性質,那么在給定數據集(所謂大數據)和具體問題的前提下,一般解決問題的步驟可以概括如下:
1.數據抽象
將數據集和具體問題抽象成數學語言,以恰當的數學符號表示。這樣做自然是為了方便表述和求解問題,而且也更加直觀。
2.設定性能度量指標
機器學習是產生模型的算法,一般來說模型都有誤差。如果模型學的太好,把訓練樣本自身的一些特點當成所有潛在樣本具有的一般性質,這種情況稱為過擬合,這樣的模型在面對新樣本時就會出現較大誤差,專業表述就是導致模型的泛化性能下降。與之相對的是欠擬合,模型對樣本的一般性質都沒學好,這種情況一般比較好解決,擴充數據集或者調整模型皆可。
3.數據預處理
之所以要做數據預處理,是因為提供的數據集往往很少是可以直接拿來用的。例如:如果樣本的屬性太多,一般有兩種方法: 降維和特征選擇。特征選擇比較好理解,就是選擇有用相關的屬性,或者用另外一種表達方式:選擇樣本中有用、跟問題相關的特征。
4.選定模型
在數據集完美的情況下,接下來就是根據具體問題選定恰當的模型了。一種方式是根據有沒有標記樣本考慮。如果是有標記樣本,可以考慮有監督學習,反之則是無監督學習,兼而有之就看半監督學習是否派的上用場。
5.訓練及優化
選定了模型,如何訓練和優化也是一個重要問題。如果要評估訓練集和驗證集的劃分效果,常用的有留出法、交叉驗證法、自助法、模型調參等如果模型計算時間太長,可以考慮剪枝如果是過擬合,則可通過引入正則化項來抑制(補償原理)如果單個模型效果不佳,可以集成多個學習器通過一定策略結合,取長補短(集成學習)
6.機器學習舉例分析
在機器學習領域特征比模型(學習算法)更重要。舉個例子,如果我們的特征選得很好,可能我們用簡單的規則就能判斷出最終的結果,甚至不需要模型。比如,要判斷一個人是男還是女,假設由計算機來完成這個任務,首先采集到各種數據(特征:姓名、身高、頭發長度,籍貫、是否吸煙等等。因為根據統計我們知道男人一般比女人高,頭發比女人短,并且會吸煙;所以這些特征都有一定的區分度,但是總有反例存在。我們用最好的算法可能準確率也達不到100%。然后再進行特征提取,提出對目標有意義的特征,刪除無關的(籍貫),然后進行預處理,對特征提取結果的再加工,目的是增強特征的表示能力,防止模型(分類器)過于復雜和學習困難。接下來就是訓練數據,這里我們通過監督學習或無監督的方法來擬合分類器模型。學習器通過分析數據的規律嘗試擬合出這些數據和學習目標間的函數,使得定義在訓練集上的總體誤差盡可能的小,從而利用學得的函數來預測未知數據的學習方法預測出結果,最后對結果進行評價和改進。
圖23 機器學習過程舉例說明
(七)機器學習覆蓋的范圍
從范圍上來說,機器學習跟模式識別,統計學習,數據挖掘是類似的,同時,機器學習與其他領域的處理技術的結合,形成了計算機視覺、語音識別、自然語言處理等交叉學科。因此,一般說數據挖掘時,可以等同于說機器學習。同時,我們平常所說的機器學習應用,應該是通用的,不僅僅局限在結構化數據,還有圖像,音頻等應用。
(1)模式識別
模式識別=機器學習。兩者的主要區別在于前者是從工業界發展起來的概念,后者則主要源自計算機學科。在著名的《Pattern Recognition And Machine Learning》這本書中,Christopher M. Bishop在開頭是這樣說的:“模式識別源自工業界,而機器學習來自于計算機學科。不過,它們中的活動可以被視為同一個領域的兩個方面,同時在過去的十年間,它們都有了長足的發展”。
(2)數據挖掘
數據挖掘=機器學習+數據庫。數據挖掘僅僅是一種方式,不是所有的數據都具有價值,數據挖掘思維方式才是關鍵,加上對數據深刻的認識,這樣才可能從數據中導出模式指引業務的改善。大部分數據挖掘中的算法是機器學習的算法在數據庫中的優化。
(3)統計學習
統計學習近似等于機器學習。統計學習是個與機器學習高度重疊的學科。因為機器學中的大多數方法來自統計學,甚至可以認為,統計學的發展促進機器學習的繁榮昌盛。例如著名的支持向量機算法,就是源自統計學科。兩者的區別在于:統計學習者重點關注的是統計模型的發展與優化,偏數學,而機器學習者更關注的是能夠解決問題,偏實踐,因此機器學習研究者會重點研究學習算法在計算機上執行的效率與準確性的提升。
(4)計算機視覺
計算機視覺=圖像處理+機器學習。圖像處理技術用于將圖像處理為適合進入機器學模型中的輸入,機器學習則負責從圖像中識別出相關的模式。計算機視覺相關的應用非常的多,例如百度識圖、手寫字符識別、車牌識別等等應用。這個領域將是未來研究的熱門方向。隨著機器學習的新領域深度學習的發展,大大促進了計算機圖像識別的效果,因此未來計算機視覺界的發展前景不可估量。
(5)語音識別
語音識別=語音處理+機器學習。語音識別就是音頻處理技術與機器學習的結合。語音識別技術一般不會單獨使用,一般會結合自然語言處理的相關技術。目前的相關應用有蘋果的語音助手siri等。
(6)自然語言處理
自然語言處理=文本處理+機器學習。自然語言處理技術主要是讓機器理解人類的語言的一門領域。在自然語言處理技術中,大量使用了編譯原理相關的技術,例如詞法分析,語法分析等等,除此之外,在理解這個層面,則使用了語義理解,機器學習等技術。作為唯一由人類自身創造的符號,自然語言處理一直是機器學習界不斷研究的方向。
圖24 ? 機器學習覆蓋的范圍
(八)機器學習在工業生產中的主要應用場景
機器學習作為人工智能的最有效的實現方法,已經在工業制造等眾多場景中得到了廣泛應用,以下是機器學習在工業生產中的五個應用場景。
1.代替肉眼檢查作業,實現制造檢查智能化和無人化
例如工程巖體的分類,目前主要是通過有經驗的工程師通過仔細鑒別來判斷,效率比較低,并且因人而異會產生不同的判斷偏差。通過采用人工智能,把工程師的經驗轉化為深度學習算法,判斷的準確率和人工判斷相當,得到對應的權值后開發出APP,這樣工程人員在使用平板拍照后,就可以通過APP自動得到工程巖體分類的結果,高效而且準確率高。
2.大幅改善工業機器人的作業性能,提升制造流程的自動化和無人化
工業上有許多需要分撿的作業,如果采用人工的作業,速度緩慢且成本高,而且還需要提供適宜的工作溫度環境。如果采用工業機器人的話,可以大幅減低成本,提高速度。例如圖25所示的Bin Picking機器人。
圖25 Bin Picking(零件分檢)機器人
但是,一般需要分撿的零件并沒有被整齊擺放,機器人雖然有攝像機看到零件,但卻不知道如何把零件成功的撿起來。在這種情況下,利用機器學習,先讓工業機器人隨機的進行一次分撿動作,然后告訴它這次動作是成功分撿到零件還是抓空了,經過多次訓練之后,機器人就會知道按照怎樣的順序來分撿才有更高的成功率,如圖26所示。
圖26 利用機器學習進行散堆拾取
如圖27所示,經過機器學習后,機器人知道了分撿時夾圓柱的哪個位置會有更高的撿起成功率。
圖27 學習次數越多準確性越高
如圖28表明通過機器學習后,機器人知道按照怎樣的順序分撿,成功率會更高,圖中數字是分撿的先后次序。
圖28 機器人確定分揀順序
如圖29所示,經過8個小時的學習后,機器人的分撿成功率可以達到90%,和熟練工人的水平相當。
圖29 分撿成功率得到大幅提升
3.工業機器人異常的提前檢知,從而有效避免機器故障帶來的損失和影響
在制造流水線上,有大量的工業機器人。如果其中一個機器人出現了故障,當人感知到這個故障時,可能已經造成大量的不合格品,從而帶來不小的損失。如果能在故障發生以前就檢知的話,就可以有效得做出預防,減少損失。如圖30中的工業機器人減速機,如果給它們配上傳感器,并提前提取它們正常/不正常工作時的波形,電流等信息,用于訓練機器學習系統,那么訓練出來的模型就可以用來提前預警,實際數據表明,機器人會比人更早地預知到故障,從而降低損失。
圖30 ? 工業機器人故障預測
如圖9所示,經過機器學習后,模型通過觀測到的波形,可以檢知到人很難感知到的細微變化,并在機器人徹底故障之前的數星期,就提出有效的預警。圖31是利用機器學習來提前預警主軸的故障,一般情況下都是主軸出現問題后才被發現。
圖31 主軸故障預測
4.PCB電路板的輔助設計
任何一塊印制板,都存在與其他結構件配合裝配的問題,所以印制板的外形和尺寸必須以產品整機結構為依據,另外還需要考慮到生產工藝,層數方面也需要根據電路性能要求、板型尺寸和線路的密集程度而定。如果不是經驗豐富的技術人員,很難設計出合適的多層板。利用機器學習,系統可以將技術人員的經驗轉化為模型,從而提升PCB設計的效率與成功率,如圖32所示。
圖32 PCB板輔助設計
5.快速高效地找出符合3D模型的現實零件
例如工業上的3D模型設計完成后,需要根據3D模型中參數,尋找可對應的現實中的零件,用于制造實際的產品。利用機器學習來完成這個任務的話,可以快速,高匹配率地找出符合3D模型參數的那些現實零件。
圖33是根據3D模型設計的參數,機器學習模型計算各個現實零件與這些參數的類似度,從而篩選出匹配的現實零件。沒有使用機器學習時,篩選的匹配率大概是68%,也就是說,找出的現實零件中有1/3不能滿足3D模型設計的參數,而使用機器學習后,匹配率高達96%。
圖33 檢索匹配的零件
(九)機器學習中的日常生活場景
1. 市民出行選乘公交預測
基于海量公交數據記錄,希望挖掘市民在公共交通中的行為模式。以市民出行公交線路選乘預測為方向,期望通過分析公交線路的歷史公交卡交易數據,挖掘固定人群在公共交通中的行為模式,分析推測乘客的出行習慣和偏好,從而建立模型預測人們在未來一周內將會搭乘哪些公交線路,為廣大乘客提供信息對稱、安全舒適的出行環境,用數據引領未來城市智慧出行。
2. 商品圖片分類
電商網站含有數以百萬計的商品圖片,“拍照購”“找同款”等應用必須對用戶提供的商品圖片進行分類。同時,提取商品圖像特征,可以提供給推薦、廣告等系統,提高推薦/廣告的效果。希望通過對圖像數據進行學習,以達到對圖像進行分類劃分的目的。
3. 基于文本內容的垃圾短信識別
垃圾短信已日益成為困擾運營商和手機用戶的難題,嚴重影響到人們正常生活、侵害到運營商的社會形象以及危害著社會穩定。而不法分子運用科技手段不斷更新垃圾短信形式且傳播途徑非常廣泛,傳統的基于策略、關鍵詞等過濾的效果有限,很多垃圾短信“逃脫”過濾,繼續到達手機終端。希望基于短信文本內容,結合機器學習算法、大數據分析挖掘來智能地識別垃圾短信及其變種。
4. 國家電網客戶用電異常行為分析
隨著電力系統升級,智能電力設備的普及,國家電網公司可以實時收集海量的用戶用電行為數據、電力設備監測數據,因此,國家電網公司希望通過大數據分析技術,科學的開展防竊電監測分析,以提高反竊電工作效率,降低竊電行為分析的時間及成本。
5.自動駕駛場景中的交通標志檢測
在自動駕駛場景中,交通標志的檢測和識別對行車周圍環境的理解起著至關重要的作用。例如通過檢測識別限速標志來控制當前車輛的速度等;另一方面,將交通標志嵌入到高精度地圖中,對定位導航也起到關鍵的輔助作用。希望機遇完全真實場景下的圖片數據用于訓練和測試,訓練能夠實際應用在自動駕駛中的識別模型。
6.大數據精準營銷中用戶畫像挖掘
在現代廣告投放系統中,多層級成體系的用戶畫像構建算法是實現精準廣告投放的基礎技術之一。期望基于用戶歷史一個月的查詢詞與用戶的人口屬性標簽(包括性別、年齡、學歷)做為訓練數據,通過機器學習、數據挖掘技術構建分類算法來對新增用戶的人口屬性進行判定。
7. 監控場景下的行人精細化識別
隨著平安中國、平安城市的提出,視頻監控被廣泛應用于各種領域,這給維護社會治安帶來了便捷;但同時也帶來了一個問題,即海量的視頻監控流使得發生突發事故后,需要耗費大量的人力物力去搜索有效信息。希望基于監控場景下多張帶有標注信息的行人圖像,在定位(頭部、上身、下身、腳、帽子、包)的基礎上研究行人精細化識別算法,自動識別出行人圖像中行人的屬性特征。
8.需求預測與倉儲規劃方案
擁有海量的買家和賣家交易數據的情況下,利用數據挖掘技術,我們能對未來的商品需求量進行準確地預測,從而幫助商家自動化很多供應鏈過程中的決策。這些以大數據驅動的供應鏈能夠幫助商家大幅降低運營成本,更精確的需求預測,能夠大大地優化運營成本,降低收貨時效,提升整個社會的供應鏈物流效率,朝智能化的供應鏈平臺方向更加邁進一步。高質量的商品需求預測是供應鏈管理的基礎和核心功能。
9.股價走勢預測
隨著經濟社會的發展,以及人們投資意識的增強,人們越來越多的參與到股票市場的經濟活動中,股票投資也已經成為人們生活的一個重要組成部分。然而在股票市場中,眾多的指標、眾多的信息,很難找出對股價更為關鍵的因素;其次股市結構極為復雜,影響因素具有多樣性、相關性。這導致了很難找出股市內在的模式。希望在盡可能全面的收集股市信息的基礎上,建立股價預測模。
10.地震預報
根據歷史全球大地震的時空圖,找出與中國大陸大地震有關的14個相關區,對這些相關區逐一鑒別,選取較優的9個,再根據這9個相關區發生的大震來預測中國大陸在未來一年內會不會有大震發生。
11.穿衣搭配推薦
穿衣搭配是服飾鞋包導購中非常重要的課題,基于搭配專家和達人生成的搭配組合數據,百萬級別的商品的文本和圖像數據,以及用戶的行為數據。期待能從以上行為、文本和圖像數據中挖掘穿衣搭配模型,為用戶提供個性化、優質的、專業的穿衣搭配方案,預測給定商品的搭配商品集合。
12.依據用戶軌跡的商戶精準營銷
隨著用戶訪問移動互聯網的與日俱增,如何根據用戶的畫像對用戶進行精準營銷成為了很多互聯網和非互聯網企業的新發展方向。希望根據商戶位置及分類數據、用戶標簽畫像數據提取用戶標簽和商戶分類的關聯關系,然后根據用戶在某一段時間內的位置數據,判斷用戶進入該商戶地位范圍300米內,則對用戶推送符合該用戶畫像的商戶位置和其他優惠信息。
13.氣象關聯分析
在社會經濟生活中,不少行業,如農業、交通業、建筑業、旅游業、銷售業、保險業等,無一例外與天氣的變化息息相關。為了更深入地挖掘氣象資源的價值,希望基于共計60年的中國地面歷史氣象數據,推動氣象數據與其他各行各業數據的有效結合,尋求氣象要素之間、以及氣象與其它事物之間的相互關系,讓氣象數據發揮更多元化的價值。
14.交通事故成因分析
隨著時代發展,便捷交通對社會產生巨大貢獻的同時,各類交通事故也嚴重地影響了人們生命財產安全和社會經濟發展。希望通過對事故類型、事故人員、事故車輛、事故天氣、駕照信息、駕駛人員犯罪記錄數據以及其他和交通事故有關的數據進行深度挖掘,形成交通事故成因分析方案。
15.基于興趣的實時新聞推薦
隨著近年來互聯網的飛速發展,個性化推薦已成為各大主流網站的一項必不可少服務。提供各類新聞的門戶網站是互聯網上的傳統服務,但是與當今蓬勃發展的電子商務網站相比,新聞的個性化推薦服務水平仍存在較大差距。希望通過對帶有時間標記的用戶瀏覽行為和新聞文本內容進行分析,挖掘用戶的新聞瀏覽模式和變化規律,設計及時準確的推薦系統預測用戶未來可能感興趣的新聞。
四、深度學習:機器學習的更高智能進階
1.深度學習的背景
2006年,加拿大多倫多大學教授、機器學習領域的泰斗Geoffrey Hinton和學生Salakhutdinov在Science上發表文章 《Reducing the Dimensionalitg of Data with Neural Neworks》,這篇文章有兩個主要觀點:1)多隱層神經網絡有更厲害的學習能力,可以表達更多特征來描述對象;2)訓練深度神經網絡時,可通過降維(pre-training)來實現,老教授設計出來的Autoencoder網絡能夠快速找到好的全局最優點,采用無監督的方法先分開對每層網絡進行訓練,然后再來微調。該文章的發表翻開了深度學習的新篇章。2013年4月,深度學習技術被《麻省理工學院技術評論》(MIT TechnologyReview)雜志列為2013年十大突破性技術(Breakthrough Technology) 之首。與淺層學習模型依賴人工經驗不同,深層學習模型通過構建機器學習模型和海量的訓練數據,來學習更有用的特征,從而最終提升分類或預測的準確性。
圖34 ?深度學習的發展歷程
2.深度學習的定義
深度學習是機器學習研究領域的分支,隸屬于神經網絡體系。深度學習通過建立、模擬人腦的信息處理神經結構來實現對外部輸入的數據進行從低級到高級的特征提取,從而能夠使機器理解學習數據,獲得信息,因具有多個隱藏層的神經網絡又被稱為深度神經網絡。深度學習將數據輸入系統后,通過建模及模擬人腦的神經網從而進行學習的技術,像生物神經元一樣,神經網絡系統中有系列分層排列的模擬神經元(信息傳遞的連接點),且經過每個神經元的響應函數都會分配一個相應的“權值”,表示彼此之間的連接強度。通過每層神經元相互“連接”,計算機就可以由達到最佳方案時所有神經元的加權和,從而可以實現這一決策方案。
3.深度學習的基礎和實現
①深度學習的思想基礎一誤差逆傳播算法(BP算法)
BP神經網絡(如圖35) 是1986年Rumelhart和McClelland等人提出的,是一種按誤差逆傳播算法訓練的多層前饋神經網絡,它存儲大量映射模式關系,無需揭示其映射方程。BP算法的核心思想是采用最速下降法(梯度下降法),通過反向傳播調試網絡的權值和閾值,使得其誤差平方和最小。
圖35 BP神經網絡
②圖像處理領域的里程碑一卷積神經網絡(CNN)
20世紀60年代,Hubel和Wiesel在研究貓腦皮層中用于局部敏感和方向選擇的神經元時發現網絡結構可以降低反饋神經網絡的復雜性,進而提出了卷積神經網絡的概念。由于其避免了對圖像的前期預處理,可以直接輸入原始圖像,CNN已經成為神經網絡的標志性代表之一。
圖36 ?卷積神經網絡(CNN)
③深度神經網絡的實現基礎一玻爾茲曼機和受限玻爾茲曼機
玻爾茲曼機 是Hinton和Sejnowski提出的隨機遞歸神經網絡,也可以看做是隨機的Hopfield網絡,因樣本分布遵循玻爾茲曼分布而命名為BM。
圖37 ?玻爾茲曼機
4.深度學習的重大成就
利用機器學習,人工智能系統獲得了歸納推理和決策能力;而深度學習更將這一能力推向了更高的層次。目前,在深度學習中,卷積神經網絡(Convolutional Neural Network,簡稱CNN)作為最有效的深層神經網絡,現在已經被越來越多地應用到許多智能領域之中,并且它們越來越像人類了,例如AlphaGo、SIRI和FACEBOOK等都應用了卷積神經網絡。在中國目前非常關注的智能制造領域中,制造機器人是深度學習的經典案例,深度學習的機器人能夠自動適應外部環境的變化,面對新型任務時可以自動重新調整算法和技術,
5.深度學習的發展展望
深度學習必將成為人工智能發展的核心驅動力。雖然深度學習在實際應用中取得了許多成就,但是仍有局限性:理論研究缺乏、無監督學習能力弱、缺少邏輯推理和記憶能力等。深度學習的研究多是基于實驗訓練進行的,但是對其內部原理,學習本質研究很少。現在的研究多是在網絡架構、參數選擇等方面,而且深度學習的還有進一步提升空間,也需要更加完備深入的理論支撐其發展。
目前主流應用還是以監督學習為主的,但在實際生活中,無標簽未知的數據占主體,所以更應該應用可以發現事物內在關系的無監督學習,未來還有更廣闊的發展空間。深度學習是人工智能發展的巨大推力,目前階段中深度學習更側重于處理數據,在面對更復雜的任務時,則需要更多記憶能力和邏輯推理能力。
五:機器學習的未來:挑戰與機遇并存
機器學習是人工智能應用的又一重要研究領域。當今,盡管在機器學習領域已經取得重大技術進展,但就目前機器學習發展現狀而言,自主學習能力還十分有限,還不具備類似人那樣的學習能力,同時機器學習的發展也面臨著巨大的挑戰,諸如泛化能力、速度、可理解性以及數據利用能力等技術性難關必須克服。但令人可喜的是,在某些復雜的類人神經分析算法的開發領域,計算機專家已經取得了很大進展,人們已經可以開發出許多自主性的算法和模型讓機器展現出高效的學習能力。對機器學習的進一步深入研究,勢必推動人工智能技術的深化應用與發展。

















 工商網監
工商網監
評論