 電子發(fā)燒友App
電子發(fā)燒友App


本文主要分享英特爾和京東在基于Spark和BigDL的深度學(xué)習(xí)技術(shù)在搭建大規(guī)模圖片特征提取框架上的實(shí)戰(zhàn)經(jīng)驗。
背景
圖像特征提取被廣泛地應(yīng)用于相似圖片檢索,去重等。在使用BigDL框架(下文即將提到)之前,我們嘗試過在多機(jī)多GPU卡、GPU集群上分別開發(fā)并部署特征抽取應(yīng)用。但以上框架均存在比較明顯的缺點(diǎn):
在GPU集群中,以GPU卡為單位的資源分配策略非常復(fù)雜,資源分配容易出問題,如剩余顯存不夠而導(dǎo)致OOM和應(yīng)用崩潰。
在單機(jī)情況下,相對集群方式,需要開發(fā)者手動做數(shù)據(jù)分片、負(fù)載和容錯。
GPU模式的應(yīng)用以Caffe為例有很多依賴,包括CUDA等等,增加了部署和維護(hù)的難度,如碰到不同操作系統(tǒng)版本和GCC版本有問題時,都需要重新編譯打包。
以上問題使得基于GPU的前向程序從架構(gòu)上面臨諸多技術(shù)應(yīng)用挑戰(zhàn)。
再來看看場景本身。因為很多圖片的背景復(fù)雜,主體物體占比通常較小,所以為了減少背景對特征提取準(zhǔn)確性的干擾,需要將主體從圖片中分離出來。自然地,圖片特征提取的框架分為兩步,先用目標(biāo)檢測算法檢測出目標(biāo),然后用特征提取算法提取目標(biāo)特征。在這里,我們采用SSD[1] (Single shot multibox detector) 進(jìn)行目標(biāo)檢測,并用DeepBit[2]網(wǎng)絡(luò)進(jìn)行特征提取。
京東內(nèi)部有海量的(數(shù)億張以上)商品圖片存在于主流的分布式的開源數(shù)據(jù)庫里。因此如何高效地在大規(guī)模分布式環(huán)境下進(jìn)行數(shù)據(jù)檢索和處理,是圖片特征提取流水線一個很關(guān)鍵的問題。現(xiàn)有的基于GPU的方案在解決上述場景的需求中面臨著另外一些挑戰(zhàn):
數(shù)據(jù)下載耗費(fèi)很長的時間,基于GPU的方案不能很好地對其進(jìn)行優(yōu)化。
針對分布式的開源數(shù)據(jù)庫中的圖片數(shù)據(jù),GPU方案的前期數(shù)據(jù)處理過程很復(fù)雜,沒有一個成熟的軟件框架用于資源管理,分布式數(shù)據(jù)處理和容錯性管理等。
因為GPU軟件和硬件框架的限制,擴(kuò)展GPU方案去處理大規(guī)模圖片有很大的挑戰(zhàn)性。
BigDL集成方案
在生產(chǎn)環(huán)境中,利用現(xiàn)有的軟件和硬件設(shè)施,將大幅提高生產(chǎn)效率(如減少新產(chǎn)品的研發(fā)時間),同時降低成本。基于在這個案例中,數(shù)據(jù)存儲在大數(shù)據(jù)集群中主流的分布式開源數(shù)據(jù)庫上,如果深度學(xué)習(xí)應(yīng)用能利用已有的大數(shù)據(jù)集群(如Hadoop或Spark集群)進(jìn)行計算,便可非常容易地解決上述的挑戰(zhàn)。
Intel開源的BigDL項目[3],是在Spark上的一個分布式深度學(xué)習(xí)框架,提供了全面的深度學(xué)習(xí)算法支持。BigDL借助Spark平臺的分布式擴(kuò)展性,可以方便地擴(kuò)展到上百或上千個節(jié)點(diǎn)。同時BigDL利用了Intel MKL數(shù)學(xué)計算庫以及并行計算等技術(shù),在Intel Xeon服務(wù)器上可以達(dá)到很高的性能(計算能力可取得媲美主流GPU的性能)。
在我們的場景中,BigDL為支持各種模型(檢測,分類)進(jìn)行定制開發(fā);模型從原來只適用于特定 環(huán)境移植到了支持通用模型(Caffe,Torch,Tensorflow)BigDL大數(shù)據(jù)環(huán)境 ;整個pipeline全流程獲得了優(yōu)化提速。
通過BigDL在spark環(huán)境進(jìn)行特征提取的流水線如Figure 1所示 :
使用Spark從分布式開源數(shù)據(jù)庫中讀入上億張原始圖片,構(gòu)建成RDD
使用Spark預(yù)處理圖片,包括調(diào)整大小,減去均值,將數(shù)據(jù)組成Batch
使用BigDL加載SSD模型,通過Spark對圖片進(jìn)行大規(guī)模、分布式的目標(biāo)檢測,得到一系列的檢測坐標(biāo)和對應(yīng)的分?jǐn)?shù)
保留分?jǐn)?shù)最高的檢測結(jié)果作為主題目標(biāo),并根據(jù)檢測坐標(biāo)對原始圖片進(jìn)行裁剪得到目標(biāo)圖片
對目標(biāo)圖片RDD進(jìn)行預(yù)處理,包括調(diào)整大小,組成Batch
使用BigDL加載DeepBit模型,通過Spark對檢測到的目標(biāo)圖片進(jìn)行分布式特征提取,得到對應(yīng)的特征
將檢測結(jié)果(提取的目標(biāo)特征RDD)存儲在HDFS上
?
整個數(shù)據(jù)分析流水線,包括數(shù)據(jù)讀取,數(shù)據(jù)分區(qū),預(yù)處理,預(yù)測和結(jié)果的存儲,都能很方便地通過BigDL在Spark中實(shí)現(xiàn)。在現(xiàn)有的大數(shù)據(jù)集群(Hadoop/Spark)上,用戶不需要修改任何集群配置,即可使用BigDL運(yùn)行深度學(xué)習(xí)應(yīng)用。并且,BigDL利用Spark平臺的高擴(kuò)展性,可以很容易地擴(kuò)展到大量的節(jié)點(diǎn)和任務(wù)上,因此極大地加快數(shù)據(jù)分析流程。
除了分布式深度學(xué)習(xí)的支持,BigDL也提供了很多易用的工具,如圖片預(yù)處理庫,模型加載工具(包括加載第三方深度學(xué)習(xí)框架的模型)等,更方便用戶搭建整個流水線。
圖片預(yù)處理
BigDL提供了基于OpenCV[5]的圖像預(yù)處理庫[4], 支持各種常見的圖像轉(zhuǎn)換和圖像增強(qiáng)的功能,用戶可以很容易地使用這些基本功能搭建圖像預(yù)處理的流水線。此外,用戶也可以調(diào)用該庫所提供的OpenCV操作自定義圖像轉(zhuǎn)換的功能。
這個樣例的預(yù)處理流水線將一個原始RDD通過一系列的轉(zhuǎn)換,轉(zhuǎn)成一個Batch的RDD。其中,ByteToMat把Byte圖片轉(zhuǎn)換成OpenCV的Mat存儲格式,Resize將圖片的調(diào)整為300x300的大小,MatToFloats將Mat里的像素存成Float數(shù)組的格式,并減去對應(yīng)通道的均值。最后,RoiImageToBatch把數(shù)據(jù)組成Batch,作為模型的輸入,用于預(yù)測或訓(xùn)練。
加載模型
用戶可以方便地使用BigDL加載預(yù)訓(xùn)練好的模型,在Spark程序中直接使用。給定BigDL模型文件,即可調(diào)用Module.load得到模型。
另外,BigDL也支持第三方深度學(xué)習(xí)框架模型的導(dǎo)入,如Caffe,Torch,TensorFlow。
用戶可以很方便地加載已經(jīng)訓(xùn)練好的模型,用于數(shù)據(jù)預(yù)測,特征提取,模型微調(diào)等。以Caffe為例,Caffe的模型由兩個文件組成,模型prototxt定義文件和模型參數(shù)文件。如下所示,用戶可以很容易地將預(yù)訓(xùn)練好的Caffe模型加載到Spark和BigDL程序中。
性能
我們對基于Caffe的GPU集群解決方案和基于BigDL的Xeon集群解決方案進(jìn)行了性能基準(zhǔn)測試,測試均運(yùn)行在京東的內(nèi)部集群環(huán)境里。
測試標(biāo)準(zhǔn)
端到端的圖片處理和分析流水線,包括:
從分布式的開源數(shù)據(jù)庫中讀取圖片(從圖片源下載圖片到內(nèi)存)
輸入到目標(biāo)檢測模型和特征提取模型進(jìn)行特征抽取
將結(jié)果(圖片路徑和特征)保存到文件系統(tǒng)
注:下載因素成為端到端總體吞吐率的重要影響因素,在這個案例里面,這部分耗時占處理總耗時(下載+檢測+特征)約一半。GPU服務(wù)器對下載這部分的處理是無法利用GPU加速的。
測試環(huán)境
GPU: NVIDIA Tesla K40,20張卡并發(fā)執(zhí)行
CPU: Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz,共1200個邏輯核 (每臺服務(wù)器有24個物理核,啟用超線程,配置成YARN的50個邏輯核)
測試結(jié)果
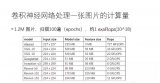
Figure 2顯示了Caffe在20個K40并發(fā)處理圖片的吞吐量約為540圖片/秒,而BigDL在1200個邏輯核的YARN(Xeon)集群上對應(yīng)的吞吐量約為2070圖片/秒。BigDL在Xeon集群上吞吐量上約是GPU集群的3.83倍,極大地縮短了大規(guī)模圖片的處理時間。
測試結(jié)果表明,BigDL在大規(guī)模圖片特征提取應(yīng)用中提供了更好的支持。BigDL的高擴(kuò)展性,高性能和易用性,幫助京東更輕松地應(yīng)對海量,爆炸式增長的圖片規(guī)模。基于這樣的測試結(jié)果,京東正在將基于GPU集群的Caffe圖片特征提取實(shí)現(xiàn),升級為基于Xeon集群的BigDL方案部署到Spark集群生產(chǎn)環(huán)境中。
Figure 2比較 K40和Xeon在圖片特征提取流水線的吞吐量 結(jié)論
BigDL的高擴(kuò)展性,高性能和易用性,幫助京東更容易地使用深度學(xué)習(xí)技術(shù)處理海量圖片。京東會繼續(xù)將BigDL應(yīng)用到更廣泛的深度學(xué)習(xí)應(yīng)用中,如分布式模型訓(xùn)練等。
引用
[1]. Liu, Wei, et al. “SSD: Single Shot Multibox Detector.” European conference on computer vision. Springer, Cham, 2016.
[2]. Lin, Kevin, et al. “Learning compact binary descriptors with unsupervised deep neural networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[3]. https://github.com/intel-analytics/BigDL
[4]. https://github.com/intel-analytics/analytics-zoo/tree/master/transform/vision
[5].

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論