 電子發燒友App
電子發燒友App


目前看到的最通俗易懂、由淺入深的圖解機器學習和GPT原理的系列文章,這是第一篇,由我和 GPT-4共同翻譯完成,分享給大家。
原作者:@JayAlammar 翻譯:成江東
我不是一個機器學習專家,本來是一名軟件工程師,與人工智能的互動很少。我一直渴望深入了解機器學習,但一直沒有找到適合自己的入門方式。這就是為什么,當谷歌在2015年11月開源TensorFlow時,我非常興奮,知道是時候開始學習之旅了。不想過于夸張,但對我來說,這就像是普羅米修斯從機器學習的奧林匹斯山上將火種贈予人類。在我腦海中,整個大數據領域,以及像Hadoop這樣的技術,都得到了極大的加速,當谷歌研究人員發布他們的Map Reduce論文時。這一次不僅是論文,而是實際的軟件,是他們在多年的發展之后所使用的內部工具。
因此,我開始學習機器學習基礎知識,發現初學者需要更通俗易懂的資源。這是我嘗試提供的。
從這里開始
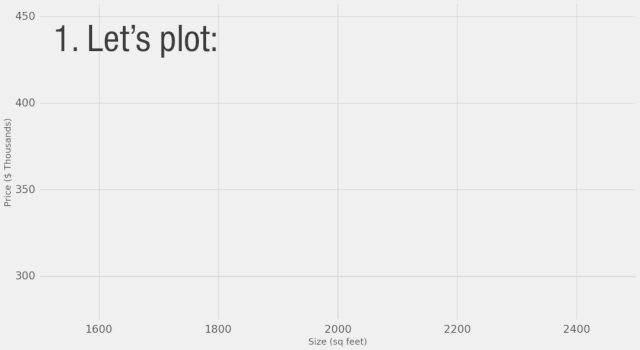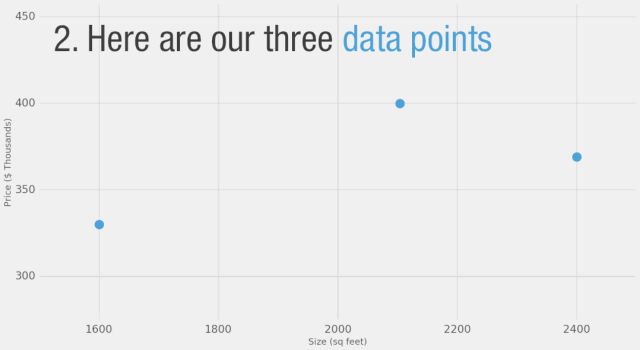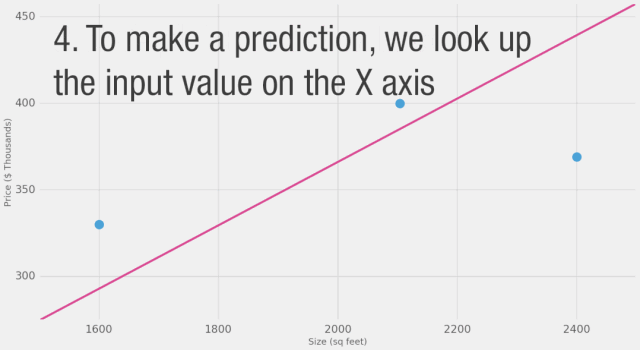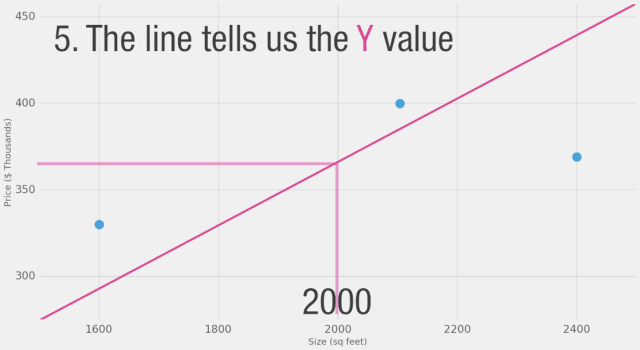
讓我們從一個簡單的例子開始。假設你正在幫助一個想買房子的朋友。她被報價40萬美元購買一個2000平方英尺(185平方米)的房子。這個價格合適嗎?在沒有參照物的情況下,這很難判斷。所以你詢問了在同一個社區購買過房子的朋友們,最后得到了三個數據點:
面積(平方英尺)(x) 價格(y)
2,104 ???????????????????????????399,900
1,600 ???????????????????????????329,900
2,400 ???????????????????????????369,000
就我個人而言,我的第一反應是計算每平方英尺的平均價格。這個價格是每平方英尺180美元。
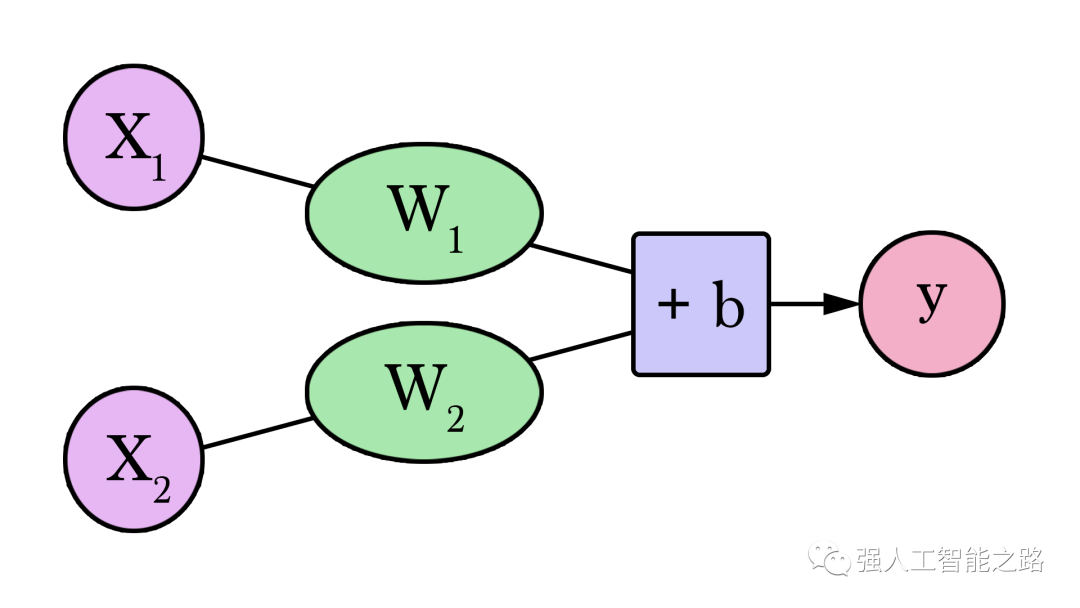
歡迎來到你的第一個神經網絡!雖然它還沒有達到Siri的水平,但現在你已經了解了基本的構建模塊。它看起來是這樣的:
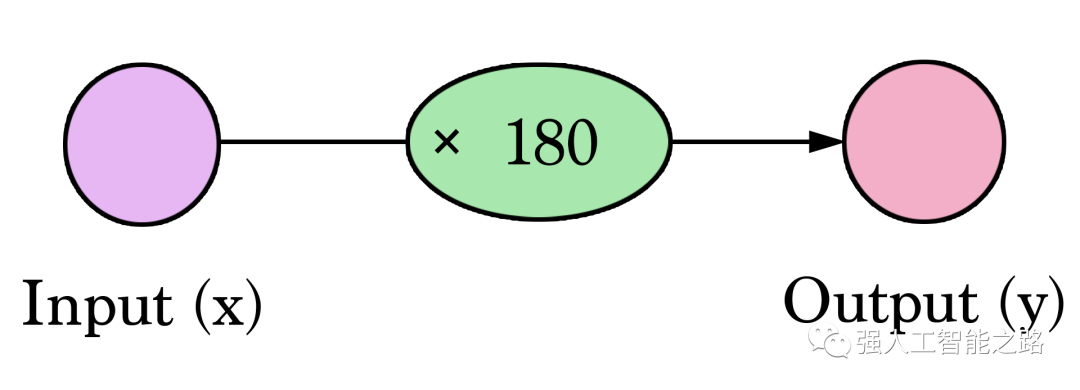
這樣的圖表展示了網絡的結構以及如何計算預測。計算從左側的輸入節點開始。輸入值向右流動。它乘以權重,結果就成為我們的輸出。將2,000平方英尺乘以180,我們得到360,000美元。在這個層面上,計算預測就是簡單的乘法。但在此之前,我們需要考慮我們將要乘以的權重。這里我們從平均值開始,稍后我們將研究更好的算法,以便在獲得更多輸入和更復雜模型時進行擴展。找到權重就是我們的“訓練”階段。所以,每當你聽到有人在“訓練”神經網絡時,它只是指找到我們用來計算預測的權重。
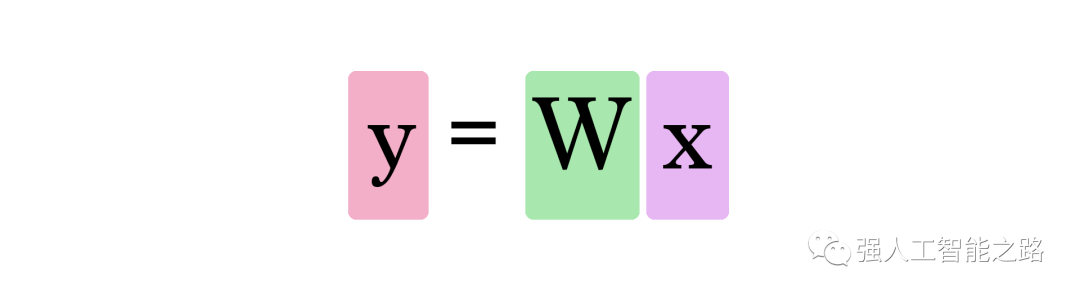
這是一個簡單的預測模型,它接受輸入,進行計算,并給出輸出(由于輸出可以是連續值,我們所擁有的技術名稱是“回歸模型”)
注:回歸模型是一種用于預測因果關系的統計模型,它通常用于研究與某些因素有關的連續變量。它基于已知數據的線性或非線性方程,通過最小化誤差或損失函數來擬合數據,并通過該方程對未知數據進行預測。回歸模型可以用于分析多種因素對某一變量的影響,例如在經濟學、社會學、醫學、工程學等領域中,它經常被用于探索因果關系和預測未來趨勢。常見的回歸模型包括線性回歸、多項式回歸、邏輯回歸等。
讓我們將這個過程可視化(為了簡化,讓我們將價格單位從1美元換成1000美元。現在我們的權重是0.180而不是180):
更難、更好、更快、更強
我們能否在估計價格方面做得比基于數據點平均值更好呢?讓我們試試。首先,讓我們定義在這種情況下更好的意義。如果我們將模型應用于我們擁有的三個數據點,它會做得多好?
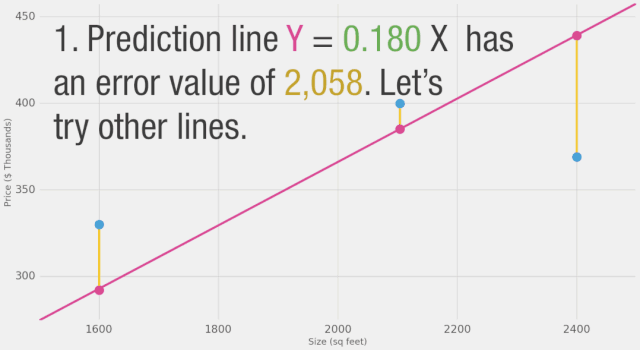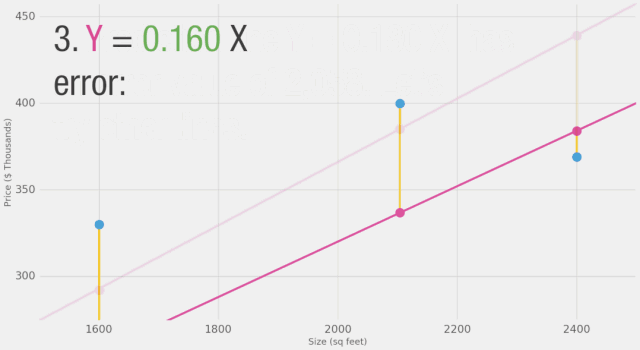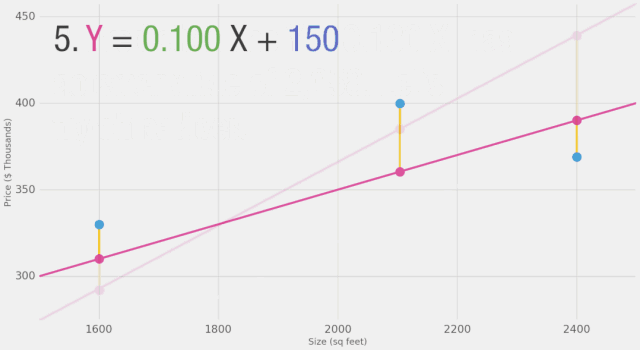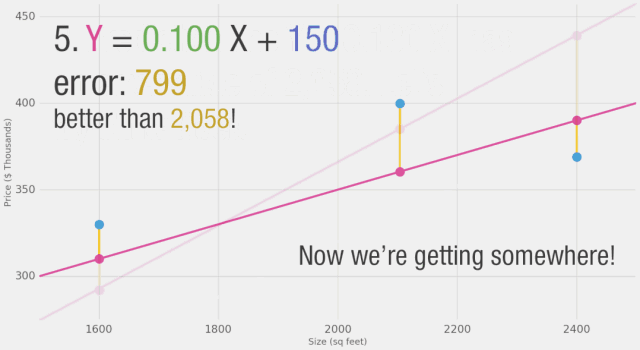
如圖所示,黃線是誤差值,黃線長是不好的,我們希望盡可能減小黃線的長度。
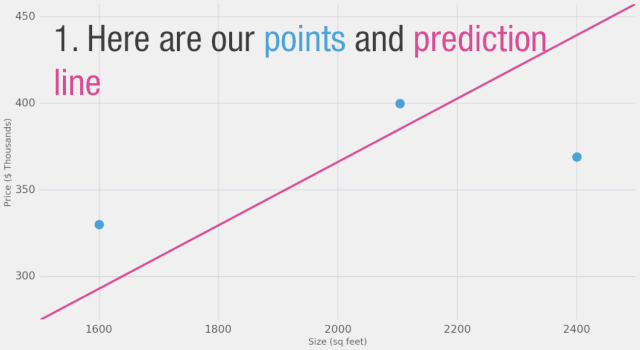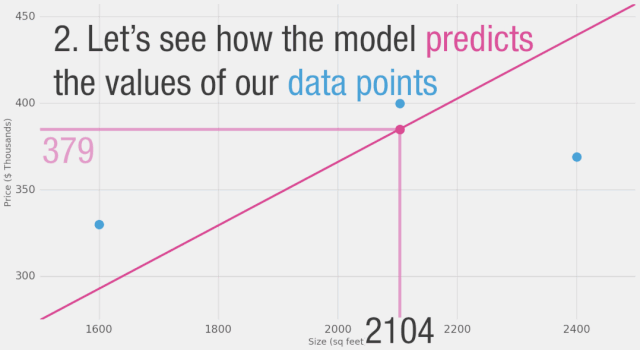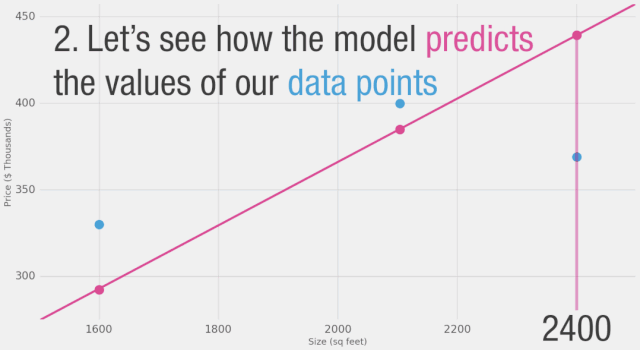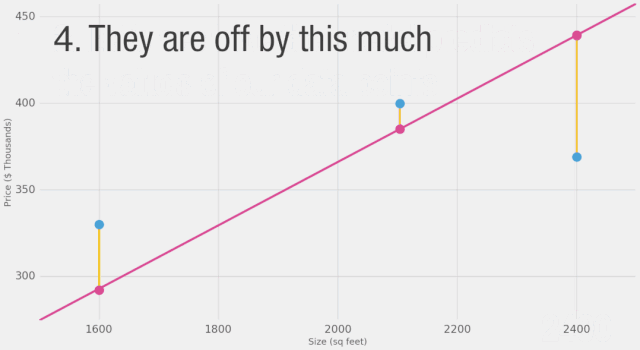
面積?(x) 價格?($1000)?(y_) 預測值?(y) y_-y (y_-y)2
2,104 ????399.9 ????????????379 ????????????????21 ?????449
1,600 ????329.9 ????????????288 ????????????????42 ????1756
2,400 ????369 ????????????? ?432 ????????????????-63 ???3969
平均值:2,058
在這里,我們可以看到實際價格值、預測價格值以及它們之間的差異。然后我們需要對這些差異求平均,以便得到一個表示預測模型中有多少錯誤的數字。問題是,第3行的值為-63。如果我們想用預測值和價格之間的差異作為衡量誤差的標準,我們必須處理這個負值。這就是為什么我們引入了一個額外的列,顯示誤差的平方,從而消除了負值。這就是我們定義更好模型的標準?-?更好的模型是誤差較小的模型。誤差是數據集中每個點誤差的平均值。對于每個點,誤差是實際值和預測值之間的差異的平方。這稱為均方誤差。將其作為指導來訓練我們的模型使其成為我們的損失函數(也稱為成本函數)。

現在我們已經定義了衡量更好模型的標準,讓我們嘗試一些其它權重值,并將它們與我們的平均值進行比較:
通過改變權重,我們無法在模型上做出太多改進。但是,如果我們添加一個偏置值,我們可以找到改進模型的值。現在我們添加了這個b值到線性公式中,我們的預測值可以更好地逼近我們的實際值。在這種情境下,我們稱之為“偏置”。這使得我們的神經網絡看起來像這樣:
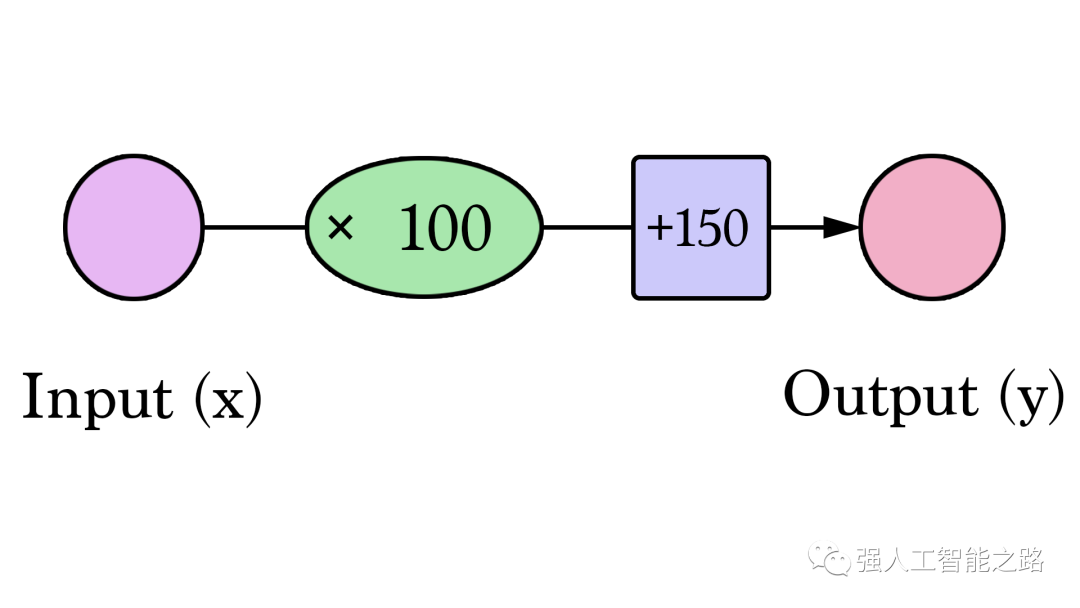
我們可以概括地說,一個具有一個輸入和一個輸出的神經網絡(劇透警告:沒有隱藏層)看起來像這樣:
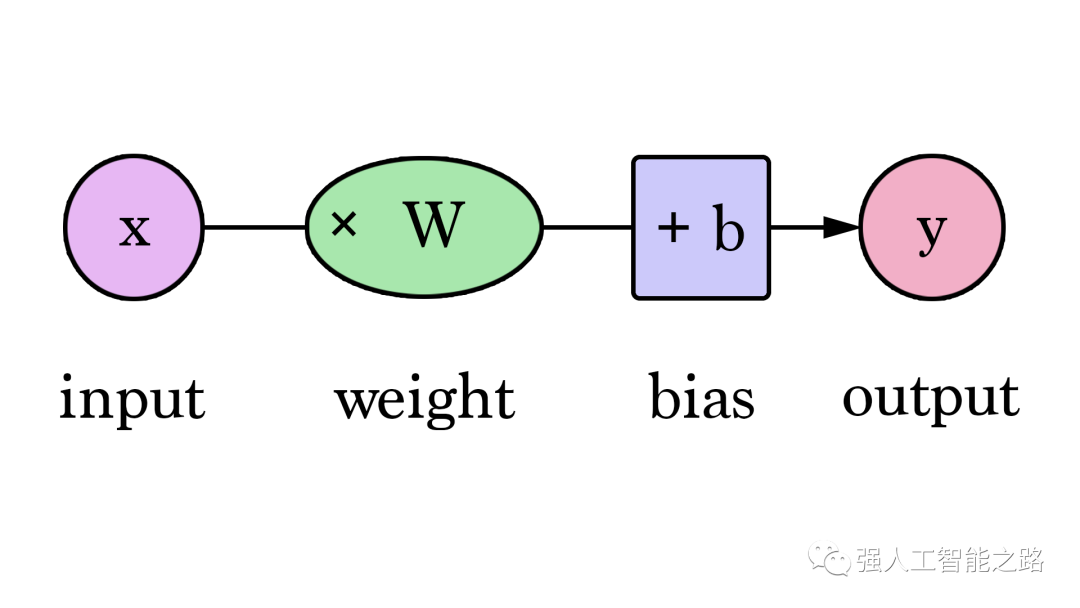
在這個圖中,W 和 b 是我們在訓練過程中找到的值,X 是我們輸入到公式中的值(例如,我們的示例中的房屋面積(平方英尺))。Y 是預測的價格。現在,計算預測使用這個公式:
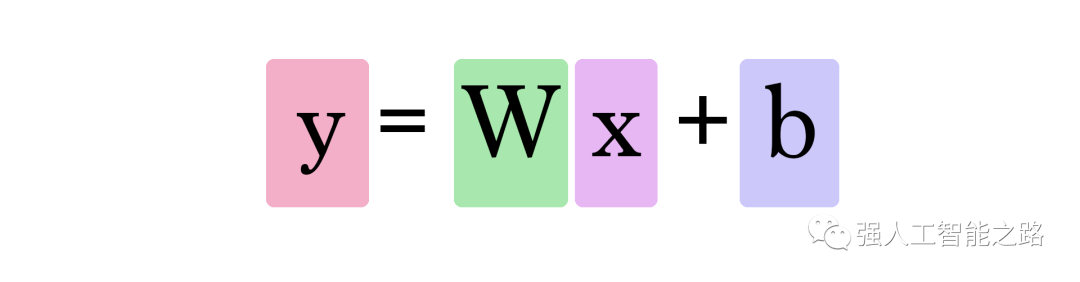
因此,我們當前的模型通過將房屋面積作為 x 插入,使用這個公式來計算預測:
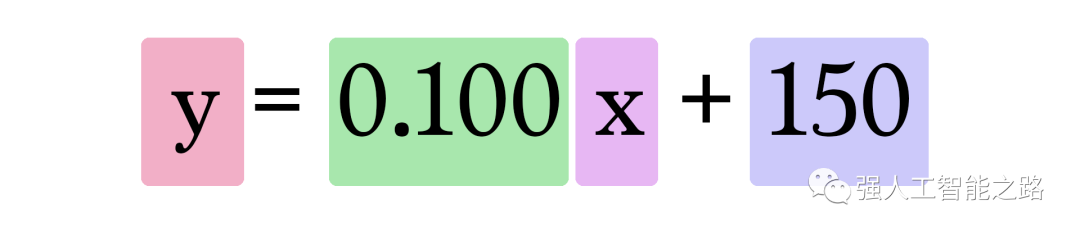
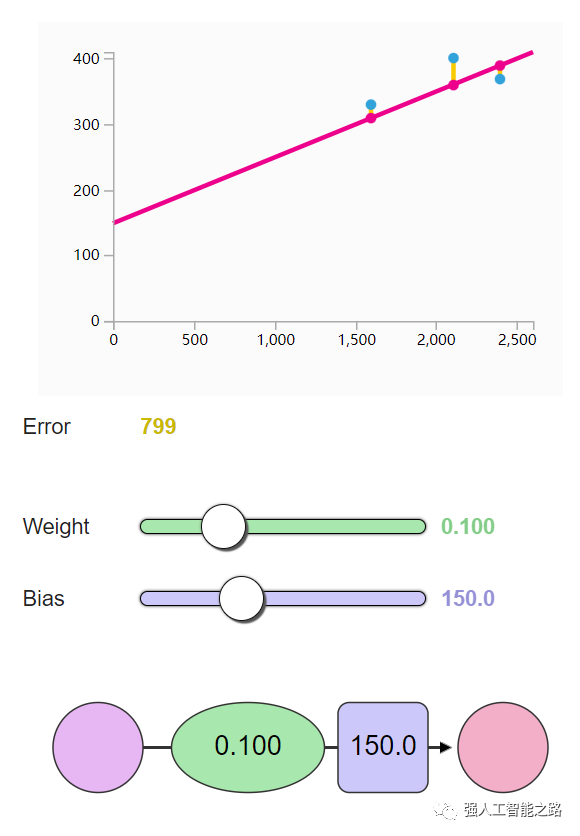
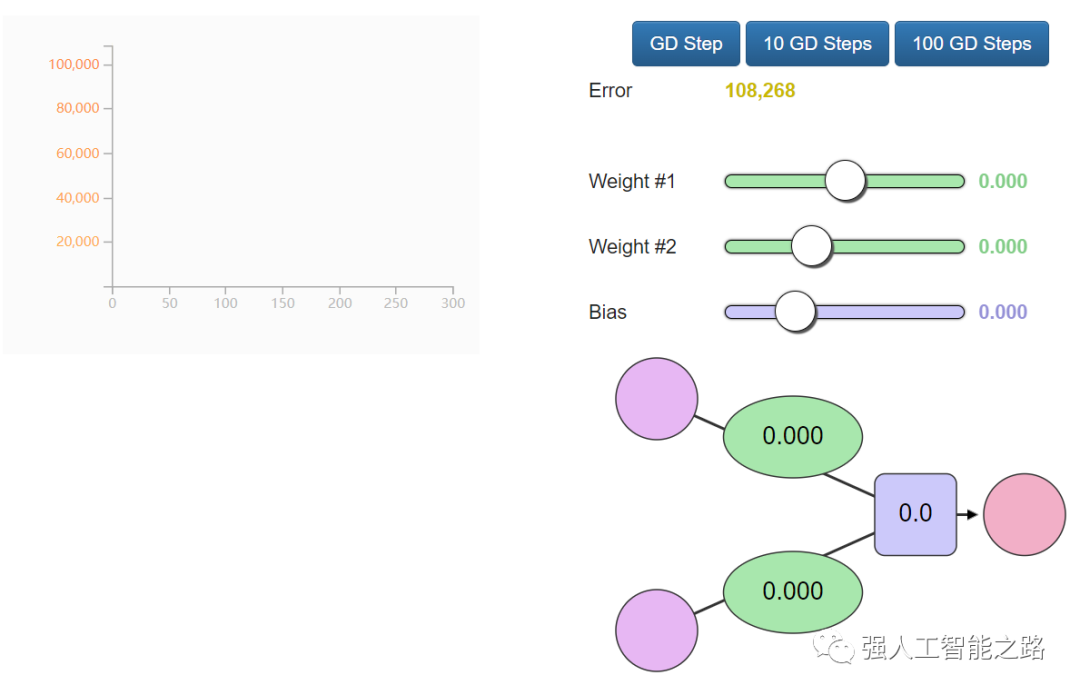
訓練? 你想嘗試訓練我們的玩具神經網絡嗎?通過調整權重和偏置來最小化損失函數。你能讓誤差值低于799嗎?
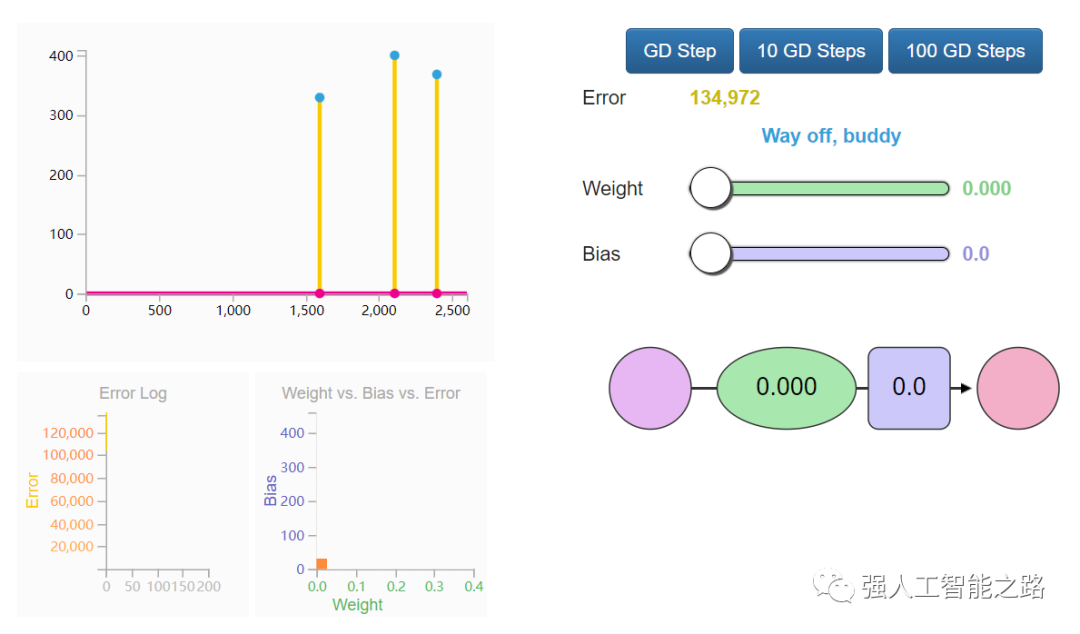
自動化?恭喜你手動訓練了你的第一個神經網絡!讓我們看看如何自動化這個訓練過程。下面是另一個帶有自動駕駛功能的示例。這些是 GD Step 按鈕。它們使用一種稱為“梯度下降”的算法,嘗試向正確的權重和偏置值邁進,以最小化損失函數。
?

這兩個新圖表可以幫助你在調整模型參數(權重和偏置)時跟蹤誤差值。跟蹤誤差非常重要,因為訓練過程就是盡可能減少這個誤差。梯度下降如何知道它的下一步應該在哪里?可以利用微積分。你看,我們知道我們要最小化的函數(損失函數,所有數據點的(y_?- y)2的平均值),也知道當前輸入的值(當前的權重和偏置),損失函數的導數告訴我們應該如何調整 W 和 b 以最小化誤差。想了解更多關于梯度下降以及如何使用它來計算新的權重和偏置的信息,請觀看 Coursera 機器學習課程的第一講。
引入第二變量
房子的大小是決定房價的唯一變量嗎?顯然還有很多其他因素。讓我們添加另一個變量,看看我們如何調整神經網絡來適應它。假設你的朋友做了更多的研究,找到了更多的數據點。她還發現了每個房子有多少個浴室:
面積(平方英尺)浴室數量?價格
2,104 ????????????????? 3 ???????????399,900
1,600 ????????????????? 3 ????????? ?329,900
2,400 ????????????????? 3? ? ? ? ? ? 369,000
1,416 ??????????????????2 ???????????232,000
3,000 ??????????????????4 ????????? ?539,900
1,985 ????????????????? 4? ? ? ? ? ? 299,900
1,534 ????????????? ? ? 3? ? ? ? ? ? 314,900
1,427????????????????? ?3? ? ? ? ? ? 198,999
1,380 ????????????? ? ? 3? ? ? ? ? ? 212,000
1,494 ????????????????? 3? ? ? ? ? ? 242,500
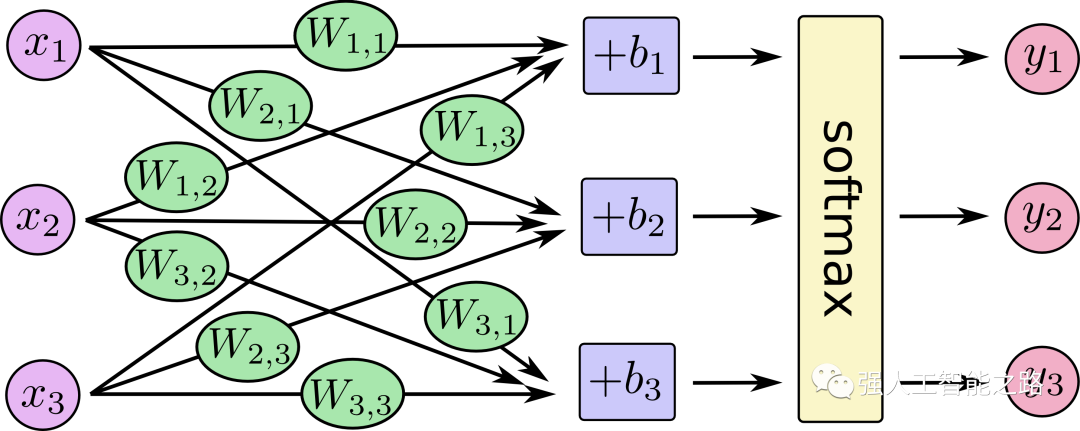
我們的兩變量神經網絡如下所示:
現在我們需要找到兩個權重(每個輸入一個)和一個偏置來創建我們的新模型。計算Y的公式如下:
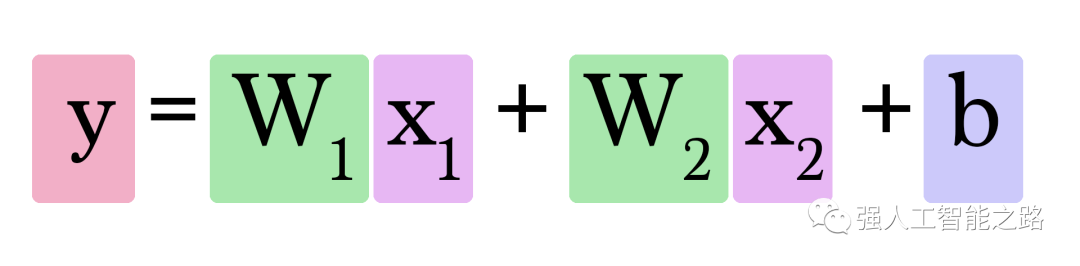
但是我們如何找到w1和w2呢?這比我們只需要考慮一個權重值時要復雜一些。多一個浴室對我們預測房價的影響有多大呢?嘗試找到合適的權重和偏置。從這里開始,你會看到隨著輸入數量的增加,我們面臨的復雜性也在增加。我們開始失去創建簡單二維形狀的能力,這使得我們不能一眼就能看出模型的特點。相反,我們主要依賴于在調整模型參數時,誤差值是如何變化的。
我們再次依靠可靠的梯度下降法來幫助我們找到合適的權重和偏置。
特征
現在你已經了解了具有一個和兩個特征的神經網絡,你可以嘗試添加更多特征并使用它們來計算預測值。權重的數量將繼續增長,當我們添加每個新特征時,我們需要調整梯度下降的實現,以便它能夠更新與新特征相關的新權重。這里需要注意的是,我們不能盲目地將我們所知道的所有信息都輸入到網絡中。我們必須在輸入模型的特征上有所選擇。特征選擇/處理是一個擁有自己一套最佳實踐和注意事項的獨立學科。如果你想看一個關于檢查數據集以選擇輸入預測模型的特征的過程的例子,請查看《泰坦尼克號之旅》。這是一個筆記本,Omar EL Gabry在其中講述了他解決Kaggle泰坦尼克挑戰的過程。Kaggle提供了泰坦尼克號上乘客的名單,包括姓名、性別、年齡、船艙以及該人是否幸存等數據。挑戰的目標是建立一個模型,根據其他信息預測一個人是否幸存。
分類
讓我們繼續調整我們的例子。假設你的朋友給你一份房子清單。這次,她標注了哪些房子在她看來具有合適的大小和浴室數量:
面積(平方英尺)浴室數量 標簽
2,104 ????????????????? 3 ????????? ?Good
1,600 ????????????????? 3? ? ? ? ? ? Good
2,400 ????????????????? 3 ???????????Good
1,416 ????????????????? 2 ???????????Bad
3,000 ??????????????????4 ???????????Bad
1,985 ????????????????? 4 ???????????Good
1,534 ????????????????? 3 ???????????Bad
1,427 ????????????????? 3 ???????????Good
1,380 ??????????????????3? ? ? ? ? ? Good
1,494 ????????????? ? ? 3 ????????? ?Good
她需要你使用這個方法來創建一個模型,根據房子的大小和浴室數量來預測她是否會喜歡這個房子。你將使用上面的列表來構建模型,然后她將使用這個模型來對許多其他房子進行分類。在這個過程中還有一個額外的改變,那就是她還有另一個包含10個房子的列表,她已經對這些房子進行了標記,但她沒有告訴你。這個另外的列表將在你訓練模型后用來評估你的模型,從而確保你的模型能夠把握她實際喜歡的房子特征。我們迄今為止所嘗試的神經網絡都是進行“回歸”操作的,它們計算并輸出一個“連續”的值(輸出可以是4,或100.6,或2143.342343)。然而,在實踐中,神經網絡更常用于“分類”類型的問題。在這些問題中,神經網絡的輸出必須是一組離散值(或“類別”),如“好”或“壞”。實踐中的工作原理是,我們將會得到一個模型,該模型會表明某個房屋是“好”的可能性為75%,而不僅是簡單地輸出“好”或“壞”。
在實踐中,我們可以將我們已經看到的網絡轉換成一個分類網絡,讓它輸出兩個值——一個值代表某個個類別(我們現在的類別是“好”和“壞”)。然后我們將這些值通過一個叫做“softmax”的操作。softmax的輸出是每個類別的概率。例如,假設網絡的這一層輸出“好”為2,“壞”為4,如果我們將[2, 4]輸入到softmax中,它將返回[0.11, 0.88]作為輸出。這意味著網絡有88%的把握認為輸入的值是“壞”的,我們的朋友可能不喜歡那個房子。
Softmax函數接受一個數組作為輸入,并輸出一個相同長度的數組。注意到它的輸出都是正數,并且總和為1,這在輸出概率值時非常有用。另外,盡管4是2的兩倍,但它的概率不僅是2的兩倍,而且是2的八倍。這是一個有用的特性,它可以夸大輸出之間的差異,從而改善我們的訓練過程。

如您在最后兩行中所看到的,softmax可以擴展到任意數量的輸入。所以現在如果我們的朋友添加了第三個標簽(比如說“不錯,但我得把一間房子租給airbnb”),softmax可以擴展以適應這種變化。花點時間探索一下網絡的形狀,看看當您改變特征數量(x1、x2、x3等)(可以是面積、浴室數量、價格、靠近學校/工作的距離等)和類別數量(y1、y2、y3等)(可以是“太貴了”、“性價比高”、“如果我把一間房子租給airbnb就好了”、“太小了”)時,網絡是如何變化的。
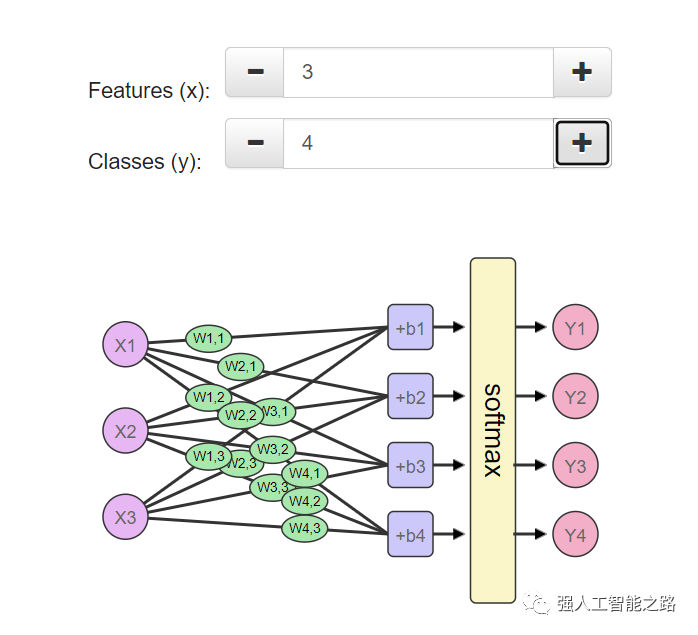
您可以在我為本文創建的這個筆記本中看到如何使用 TensorFlow 創建和訓練這個網絡的示例。真正的動力?如果您已經讀到這里了,我必須向您揭示我寫這篇文章的另一個動力。這篇文章旨在作為一個更加溫和的 TensorFlow 教程入門。如果您現在開始學習《MNIST 機器學習初學者》,并遇到了這張圖:
我寫這篇文章是為了讓沒有機器學習經驗的人們為 TensorFlow 入門教程中的這張圖做好準備。這就是為什么我模擬了它的視覺風格。我希望您會覺得準備充分,并且了解這個系統以及它的工作原理。如果您想開始嘗試編寫代碼,請隨時從入門教程開始,它教一個神經網絡如何識別手寫數字。您還應該通過學習我們在這里討論的概念的理論和數學基礎來繼續您的學習。現在可以提出的好問題包括:
其他類型的損失函數有哪些?
哪些損失函數更適用于哪些應用?
使用梯度下降實際計算新權重的算法是什么?
在您已經了解的領域中,機器學習的應用有哪些?
通過將這個技能與您技能庫中的其他技能相結合,您可以創造出什么新奇的魔法?
以下是一些很好的學習資源:
Coursera上的機器學習課程,由Andrew Ng主講。這是我開始學習的課程。從回歸開始,然后轉向分類和神經網絡。
Coursera上的神經網絡與機器學習課程,由Geoffrey Hinton主講。更側重于神經網絡及其視覺應用。
斯坦福大學的CS231n課程:卷積神經網絡與視覺識別,由Andrej Karpathy主講。了解一些高級概念以及使用深度神經網絡進行視覺識別的最新技術。
神經網絡社區是一個很好的資源,可以了解不同類型的神經網絡。
致謝:
感謝Yasmine Alfouzan、Ammar Alammar、Khalid Alnuaim、Fahad Alhazmi、Mazen Melibari和Hadeel Al-Negheimish在審查本文的早期版本時提供的幫助。如有任何更正或反饋,請在Twitter上聯系我。
編輯:黃飛
















 工商網監
工商網監
評論