 電子發(fā)燒友App
電子發(fā)燒友App


第一部分
模型預(yù)測(cè)控制
01
最優(yōu)控制理論處理的問(wèn)題通常是找到一個(gè)滿(mǎn)足容許控制的 u*,把它作用于系統(tǒng)(被控對(duì)象)?(t)=f(x(t),u(t),t) 從而可以得到系統(tǒng)的狀態(tài)軌跡 x(t),使得目標(biāo)函數(shù)最優(yōu)。對(duì)于軌跡跟蹤問(wèn)題,那目標(biāo)函數(shù)就是使得這個(gè)軌跡在一定的時(shí)間范圍[t0tf]內(nèi)與我們期望的軌跡(目標(biāo))x*(t) 越近越好。最優(yōu)控制問(wèn)題更一般的表達(dá)如下:在被控對(duì)象符合動(dòng)力學(xué)原理(狀態(tài)方程)和狀態(tài)約束
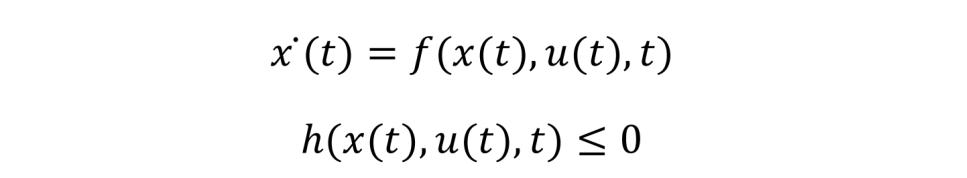
的條件下,求解控制函數(shù) u(t) 以使得連續(xù)時(shí)間性能指標(biāo)
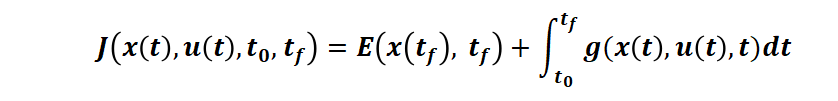
最小。其中 t0?是初始時(shí)刻,tf?是終端時(shí)刻,E 是終端時(shí)刻代價(jià),g 是運(yùn)行時(shí)刻代價(jià)。例如,更具體的場(chǎng)景,對(duì)于時(shí)間最短問(wèn)題(例如控制電流使得最短時(shí)間充電到 SOC100%),性能指標(biāo)即:
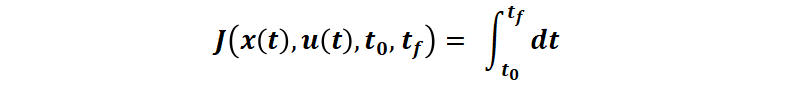
對(duì)于最小燃料消耗問(wèn)題(接下來(lái)本文中主要使用的例子,假設(shè)燃料消耗與控制量 u 成正比,并且 u∈[0 1]),性能指標(biāo)變?yōu)椋?/p>
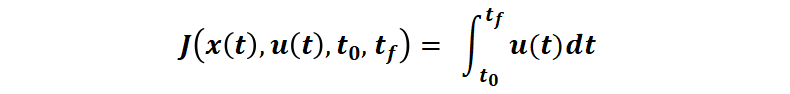
最優(yōu)控制的性能指標(biāo)函數(shù)和約束函數(shù)都是泛函,因?yàn)樗麄兊淖宰兞?u(t) 本身也是個(gè)函數(shù)。于是,求解性能指標(biāo)函數(shù)最優(yōu)的問(wèn)題是一個(gè)求泛函極值的問(wèn)題,類(lèi)比于函數(shù)極值通過(guò)求導(dǎo)來(lái)獲得極值條件,泛函極值則通過(guò)變分法來(lái)獲得極值條件。而基于變分的兩大方法: 龐特里亞金極小值原理和動(dòng)態(tài)規(guī)劃(求解 Hamilton-Jacobi-Bellman 方程),則是最優(yōu)控制問(wèn)題求解的主要方法。對(duì)于簡(jiǎn)化的最優(yōu)控制問(wèn)題,例如被控對(duì)象為線性系統(tǒng)
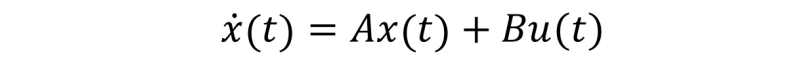
性能指標(biāo)是二次型的無(wú)限時(shí)域的連續(xù)時(shí)間泛函:
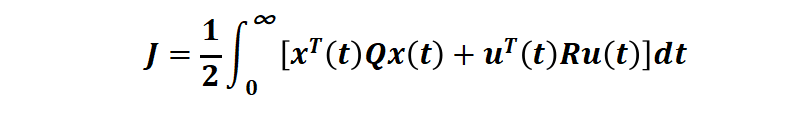
(其中第一項(xiàng)是對(duì)狀態(tài)(例如追蹤誤差)的要求,第二項(xiàng)是對(duì)控制能量的要求,Q 和 R 是權(quán)重矩陣),優(yōu)化區(qū)間考慮整個(gè)時(shí)間域 [t0=0 tf=∞](也就是 Linear-Quadratic Regulator (LQR)?), 可以使用極小值原理或動(dòng)態(tài)規(guī)劃或 Ricatti 代數(shù)方程求得閉環(huán)形式的最優(yōu)控制。例如,對(duì)一個(gè)車(chē)載倒立擺系統(tǒng)[1]:
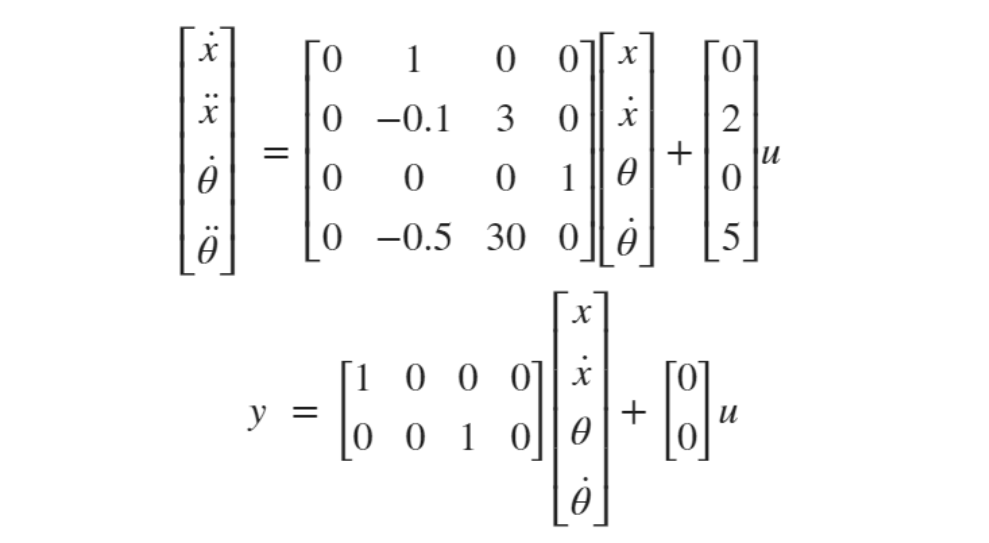
其中系統(tǒng)輸出是車(chē)輛位移 x 和倒立擺角度 θ,控制輸出 u 是作用在車(chē)上的水平力。控制是標(biāo)量,狀態(tài)是 4 維
Q = [1,0,0,0;...?
0,0,0,0;...?
0,0,1,0;...
0,0,0,0];
R = 1;?
[K,S,P] = lqr(sys,Q,R)
利用 lqr 函數(shù)就可以求得最優(yōu)增益矩陣 K。但對(duì)于更一般的非線性系統(tǒng),使用極小值原理或動(dòng)態(tài)規(guī)劃求解解析解幾乎不可能,數(shù)值解計(jì)算復(fù)雜度較高,所以可以考慮一定的問(wèn)題簡(jiǎn)化,僅考慮未來(lái)的一小段時(shí)間最優(yōu)(而非全時(shí)間域“最優(yōu)”),將最優(yōu)控制問(wèn)題轉(zhuǎn)化未來(lái)幾個(gè)時(shí)間步的在線數(shù)值優(yōu)化問(wèn)題,例如 MPC,可以大大降低“最優(yōu)”控制計(jì)算的復(fù)雜度。
我們通過(guò)和人的行為進(jìn)行類(lèi)比來(lái)解釋 MPC 的思想[2]:設(shè)想開(kāi)車(chē)的場(chǎng)景,我們的目標(biāo)是讓車(chē)按一定的軌跡行駛,人的控制方式和模型預(yù)測(cè)控制器的工作方式很像,司機(jī)的大腦中可能有一些經(jīng)驗(yàn)( 類(lèi)似虛擬的動(dòng)力學(xué)模型),于是他會(huì)利用這些經(jīng)驗(yàn)(虛擬模型)在大腦中去預(yù)先“仿真”這個(gè)過(guò)程,可以預(yù)測(cè)假如他采取了某些動(dòng)作(油門(mén),剎車(chē),轉(zhuǎn)向等等)之后的一段時(shí)間內(nèi)汽車(chē)會(huì)有多快或有多少轉(zhuǎn)向,從而他會(huì)從這些可選的一系列動(dòng)作中選擇一個(gè)最能使汽車(chē)在未來(lái)一段時(shí)間內(nèi)接近期望軌跡的控制動(dòng)作作為當(dāng)前時(shí)刻的行為,例如踩油門(mén),剎車(chē)等等,并在每個(gè)時(shí)刻不斷重復(fù)類(lèi)似的思想,從而驅(qū)動(dòng)車(chē)輛到期望的軌跡。
算法介紹
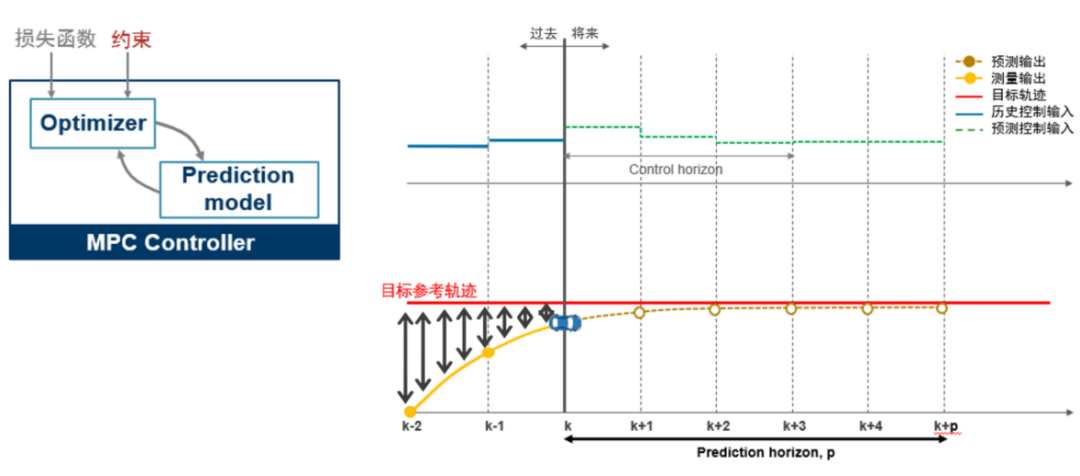
(圖表1)
模型預(yù)測(cè)控制 (MPC) 是一種最優(yōu)控制技術(shù),在每個(gè)控制周期 tk , MPC 控制器獲得系統(tǒng)(被控對(duì)象)當(dāng)前的狀態(tài)。接下來(lái)它利用基于系統(tǒng)當(dāng)前狀態(tài)和系統(tǒng)動(dòng)態(tài)模型通過(guò)在有限時(shí)間上預(yù)測(cè)系統(tǒng)未來(lái) p 步狀態(tài)軌跡,并與目標(biāo)軌跡構(gòu)建代價(jià)函數(shù)和約束,進(jìn)行一次開(kāi)環(huán)優(yōu)化問(wèn)題(要優(yōu)化的變量是作用在被控對(duì)象上的控制輸入序列)求解,得到未來(lái)一段時(shí)間 [tk,tk+1,···,tk+p] 的控制輸入序列?[uk,uk+1,···,uk+p] 。當(dāng)然對(duì)于求解得到的控制輸入序列,控制器只將最近時(shí)刻 tk 的控制?uk 作用于系統(tǒng)(被控對(duì)象)而忽略掉控制序列的其他值[uk+1,···,uk+p], 在下一個(gè)時(shí)刻tk+1,MPC 控制器會(huì)重復(fù)上述優(yōu)化求解過(guò)程重新計(jì)算控制序輸入列并只將第一個(gè)控制值作為當(dāng)前時(shí)刻的控制量作用于系統(tǒng),依次類(lèi)推,重復(fù)上述過(guò)程進(jìn)行下一時(shí)刻的求解。所以 MPC 在每個(gè)時(shí)刻都在線進(jìn)行一個(gè)含約束的優(yōu)化問(wèn)題的求解(滾動(dòng)優(yōu)化,特殊情況除外)。接下來(lái)我們看一下這個(gè)優(yōu)化問(wèn)題是如何定義以及求解的。MPC 的優(yōu)化問(wèn)題 (更具體的二次規(guī)劃,QP) 包含這幾項(xiàng)主要內(nèi)容[3]:
代價(jià)函數(shù): 用于度量控制器性能,目標(biāo)是求它的最小值。
約束:目標(biāo)解必須滿(mǎn)足的條件,例如控制量(manipulated variables, MV)和被控對(duì)象狀態(tài)輸出的物理邊界。
控制與決策:得到優(yōu)化的控制量(MV)
代價(jià)函數(shù)
一個(gè)典型的代價(jià)函數(shù)由四部分組成,每一部分關(guān)注控制器性能的一個(gè)方面。
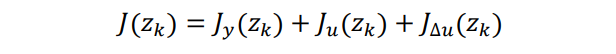
這里面的 zk?就是 QP 問(wèn)題的決策變量(控制變量)。其中每一項(xiàng)量化一個(gè)性能指標(biāo)。
Jy(zk) 量化系統(tǒng)輸出與目標(biāo)軌跡的跟蹤效果
Ju(zk) 用于量化控制輸入與目標(biāo)控制變量跟蹤效果(在很多應(yīng)用中,控制器還需要保證控制變量(MV)保持在某個(gè)目標(biāo)附近,尤其在控制量數(shù)目遠(yuǎn)多于系統(tǒng)輸出量數(shù)目的情況下)
JΔu(zk) 控制變量波動(dòng)約束(多數(shù)應(yīng)用場(chǎng)景下一般都希望控制變量有較小的變動(dòng)或調(diào)整,而不希望較大的突變)。
例如對(duì)于常用的 Jy(zk)?,即量化圖表1中黑色雙箭頭代表的區(qū)域。控制器的目標(biāo)是將被控對(duì)象保持在指定的參考軌跡附近。MPC 控制器通過(guò)如下計(jì)算得到一個(gè)標(biāo)量作為性能度量來(lái)實(shí)現(xiàn)目標(biāo)軌跡跟蹤:
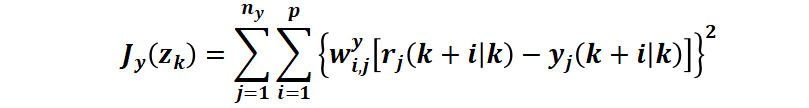
其中,底標(biāo) i 是對(duì) p 個(gè)預(yù)測(cè)步的循環(huán),j 是對(duì) ny 個(gè)輸出的循環(huán)。
k:當(dāng)前控制周期
p:預(yù)測(cè)區(qū)間(Prediction Horizon)
ny:被控對(duì)象輸出變量的數(shù)量
zk:QP 問(wèn)題決策變量,也就是對(duì)應(yīng)的時(shí)間步上的控制器輸出序列,其中
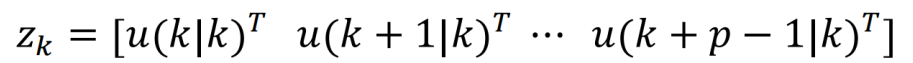
yj(k+i|k):從 k 時(shí)刻開(kāi)始的未來(lái)第 i 個(gè)(共 p 個(gè))時(shí)間步長(zhǎng)被控對(duì)象第 j 個(gè)(共 ny?個(gè))輸出的預(yù)測(cè)值
rj(k+i|k):從時(shí)刻開(kāi)始的未來(lái)第個(gè)(共個(gè))時(shí)間步長(zhǎng)被控對(duì)象第個(gè)(共個(gè))輸出的目標(biāo)參考值
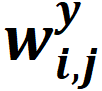
:未來(lái)第個(gè)時(shí)間步,被控對(duì)象第個(gè)(共個(gè))輸出的權(quán)重因子(無(wú)量綱)
約束
MPC 中最常見(jiàn)的約束就是邊界約束,例如針對(duì)被控對(duì)象、控制變量(MV)、控制變量變化量的邊界約束,如下:
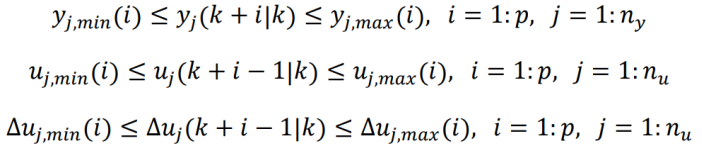
yj,min(i),yj,max(i):從 k 時(shí)刻開(kāi)始的未來(lái)第 i 個(gè)時(shí)間步長(zhǎng)被控對(duì)象第 j 個(gè)(共 ny?個(gè))輸出的下界和上界
uj,min(i),uj,max(i):從 k 時(shí)刻開(kāi)始的未來(lái)第 i 個(gè)時(shí)間步長(zhǎng)第 j 個(gè)(共 nu?個(gè))控制變量的下界和上界
Δuj,min(i),Δuj,max(i):從 k 時(shí)刻開(kāi)始的未來(lái)第 i 個(gè)時(shí)間步長(zhǎng)第 j 個(gè)(共 nu?個(gè))控制變量的下界和上界
預(yù)測(cè)與決策
每次滾動(dòng)優(yōu)化計(jì)算過(guò)程中,模型預(yù)測(cè)控制器可以獲得整個(gè)預(yù)測(cè)區(qū)間 p 時(shí)間步上的參考軌跡 rj(k+i|k)。模型預(yù)測(cè)控制器中的“模型”包括被控對(duì)象模型、擾動(dòng)模型和噪聲模型,如圖表2,控制器每次滾動(dòng)優(yōu)化計(jì)算過(guò)程中,使用這些模型加上可調(diào)(可優(yōu)化)的控制變量 zk?來(lái)預(yù)測(cè)被控對(duì)象的輸出?yj(k+i|k)。
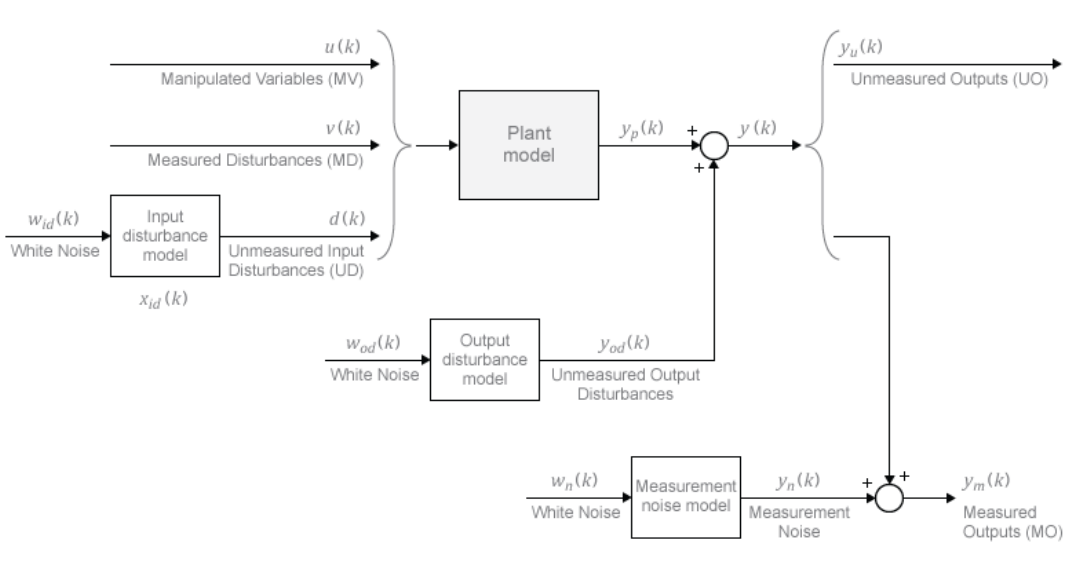
(圖表2)
上述預(yù)測(cè)過(guò)程可以通過(guò)簡(jiǎn)化的狀態(tài)空間離散預(yù)測(cè)模型表示:
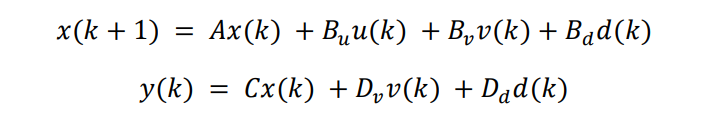
其中 v(k) 是可測(cè)干擾輸入,d(k) 是不可測(cè)干擾輸入白噪聲。
我們?cè)敿?xì)描述一下在 k=0 時(shí)刻預(yù)測(cè)模型在預(yù)測(cè)區(qū)間 p 上的軌跡預(yù)測(cè)過(guò)程:對(duì)所有預(yù)測(cè)瞬時(shí) i, 將 d(i) 設(shè)為0,可得,問(wèn)題變成一個(gè)遞歸計(jì)算問(wèn)題(從 k=1到 k=0)即可得到 y(i|0) 序列:
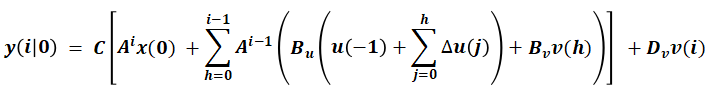
整理成矩陣形式:
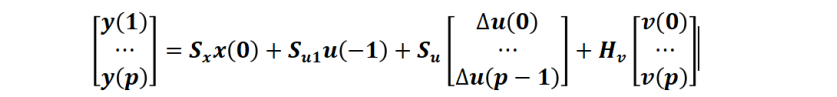
其中(此處不詳細(xì)列出這些矩陣表達(dá)式,可以根據(jù)上式遞歸自行推導(dǎo))
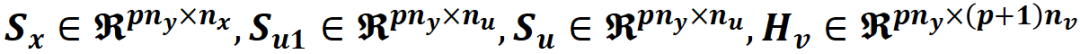
組合各個(gè)元素得到優(yōu)化問(wèn)題定義
將上述的代價(jià)函數(shù),約束,預(yù)測(cè)模型矩陣結(jié)合起來(lái)構(gòu)建 MPC 的開(kāi)環(huán)優(yōu)化問(wèn)題如下:
狀態(tài)變量 x(k)∈Rnx,控制變量 u(k)∈Rnu,滿(mǎn)足上述系統(tǒng)動(dòng)力學(xué)方程以及時(shí)域約束,通過(guò)預(yù)測(cè)計(jì)算,求解如下最小化性能指標(biāo)對(duì)應(yīng)的優(yōu)化變量zk
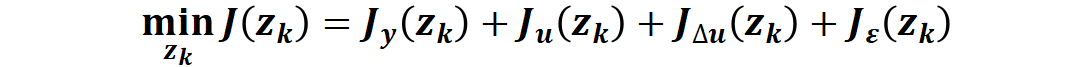
其中
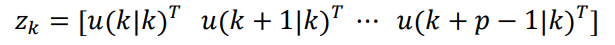
即在預(yù)測(cè)區(qū)間 p 上的待優(yōu)化的控制輸入序列。
示例:
非線性 MPC 的飛行機(jī)器人軌跡開(kāi)環(huán)規(guī)劃和閉環(huán)反饋控制?
我們通過(guò)一個(gè)非線性 MPC 的飛行機(jī)器人軌跡優(yōu)化與控制控制器設(shè)計(jì)示例來(lái)主要介紹介紹 MPC 設(shè)計(jì)方法[4]。MPC 即可以用于軌跡追蹤控制(在線實(shí)時(shí)),也可以用于規(guī)劃(進(jìn)行一次開(kāi)環(huán)的優(yōu)化)。本示例先用 MPC 進(jìn)行了一次開(kāi)環(huán)優(yōu)化求解完成了規(guī)劃,找到了從一個(gè)位置到另一個(gè)位置的最佳軌跡,然后再結(jié)合狀態(tài)估計(jì)器:擴(kuò)展卡爾曼濾波器,來(lái)控制機(jī)器人沿規(guī)劃的最優(yōu)軌跡進(jìn)行閉環(huán)控制。
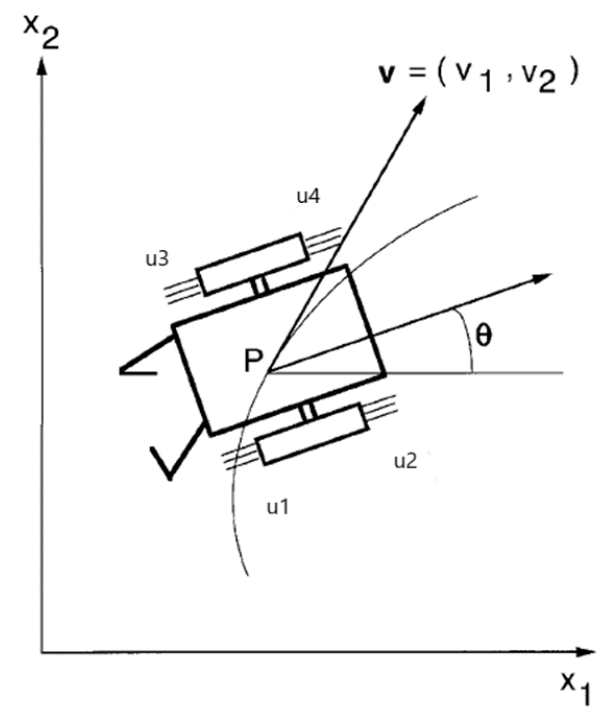
這個(gè)簡(jiǎn)化的例子中的飛行機(jī)器人有四個(gè)推進(jìn)器在平面空間中移動(dòng)。
該模型動(dòng)力學(xué)系統(tǒng)如下:
function dxdt = FlyingRobotStateFcn(x, u)
% 狀態(tài)方程:x 是六個(gè)狀態(tài),u是推力控制。
%x(1)???– 質(zhì)心x坐標(biāo)
%x(2)??– 質(zhì)心y坐標(biāo)
%x(3)? – theta, 機(jī)器人(推力)方向
%x(4)??– x方向的速度vx
%x(5)??– y方向的速度vy
%x(5)??– omega, 角速度
…
dxdt = zeros(6,1);
dxdt(1) = x(4);
dxdt(2) = x(5);
dxdt(3) = x(6);
dxdt(4) = (T1 + T2)*cos(theta);
dxdt(5) = (T1 + T2)*sin(theta);
dxdt(6) = alpha*T1 - beta*T2;
end
示例假設(shè)機(jī)器人有四個(gè)物理推力 [u(1)u(2)u(3)u(4)],范圍從0到1。
軌跡規(guī)劃
前面提到了,MPC 用于軌跡規(guī)劃其實(shí)是求解了一次開(kāi)環(huán)的帶約束的優(yōu)化問(wèn)題,區(qū)別于后面的針對(duì)規(guī)劃好的軌跡的路徑跟蹤(利用反饋狀態(tài)的滾動(dòng)優(yōu)化)。
先定義本示例的軌跡規(guī)劃問(wèn)題:機(jī)器人最初停留在 [-10, -10] 位置,方向角 theta 為 pi/2。本例中的飛行任務(wù)是在 12s 內(nèi)移動(dòng)機(jī)器人并停在最終位置 [0, 0],方向角 theta 為 0。目標(biāo)是找到最優(yōu)路徑,使推進(jìn)器在控制過(guò)程中消耗的燃料總量最小。
在此例中,對(duì)于規(guī)劃軌跡,我們開(kāi)環(huán)優(yōu)化需要使用全部時(shí)間長(zhǎng)度:12s。設(shè)定一個(gè)采樣時(shí)間 Ts=0.4s,所以對(duì)應(yīng)的預(yù)測(cè)區(qū)間為 30 步(12/0.4)。規(guī)劃的運(yùn)行周期通常可以比反饋控制周期更大,或更低頻,所以有更多計(jì)算資源允許計(jì)算一個(gè)相對(duì)較大的優(yōu)化問(wèn)題。對(duì)于軌跡規(guī)劃我們可以創(chuàng)建一個(gè)多級(jí)非線性MPC對(duì)象,它允許對(duì)每個(gè)預(yù)測(cè)步都定義不同的代價(jià)函數(shù)和約束。
% 具有 nx=6 個(gè)狀態(tài)和 nu=4 個(gè)控制輸入(mv)
% 預(yù)測(cè)區(qū)間 p = 30
nlobj=nlmpcMultistage(p,nx,nu);
nlobj.Ts=Ts;
for?ct=1:p
%并且每個(gè) stage/ 預(yù)測(cè)步有自己的代價(jià)函數(shù)
其中代價(jià)函數(shù)
包含 stage 這個(gè)參數(shù),
見(jiàn)下面 FlyingRobotCostFcn 函數(shù)
nlobj.Stages(ct).CostFcn='FlyingRobotCostFcn';
end
%?代價(jià)函數(shù)示例
function J=FlyingRobotCostFcn(stage, x, u)
%本例中因?yàn)橥屏εc燃油正相關(guān),所以這個(gè)示例每個(gè)預(yù)測(cè)步(1到p)簡(jiǎn)化燃油消耗的表達(dá)為上四個(gè)推力之
%和。本示例沒(méi)有直接使用 stage 參數(shù)。
J = u(1) + u(2) + u(3) + u(4);
end
指定預(yù)測(cè)模型的狀態(tài)轉(zhuǎn)移方程和對(duì)應(yīng)的雅可比函數(shù)解析形式,可以大幅提升計(jì)算效率
nlobj.Model.StateFcn="FlyingRobotStateFcn";
nlobj.Model.StateJacFcn=@
FlyingRobotStateJacobianFcn;
控制目標(biāo)是在第12秒將機(jī)器人停在 [0,0] 處,角度為0弧度。將這個(gè)指定為終端狀態(tài)約束,其中最后一個(gè)預(yù)測(cè)步驟(第p+1步)的每個(gè)位置和速度狀態(tài)都應(yīng)該為零。
nlobj.Model.TerminalState = zeros(6,1);
如果可以為每個(gè) stage 都提供代價(jià)函數(shù)和約束函數(shù)的雅可比函數(shù)解析式會(huì)大大提升優(yōu)化效率。本例沒(méi)有提供,所以它們的雅可比矩陣由 MPC 控制器使用內(nèi)置的數(shù)值差分方法計(jì)算。
每個(gè)推力的工作范圍在0到1之間,也就是 MV 的下限和上限。
for?ct = 1:nu
nlobj.MV(ct).Min = 0;
nlobj.MV(ct).Max = 1;
end
指定飛行器初始條件:
x0=[-10;-10;pi/2;0;0;0];% 機(jī)器人停在 [-10, -10], 方向角為 pi/2
u0 = zeros(nu,1);????%初始推力為0
通過(guò)調(diào)用 nlmpcmove 命令,就可以完成一次優(yōu)化,找到最佳狀態(tài)和控制(MV)軌跡。
[~,~,info] = nlmpcmove(nlobj,x0,u0);
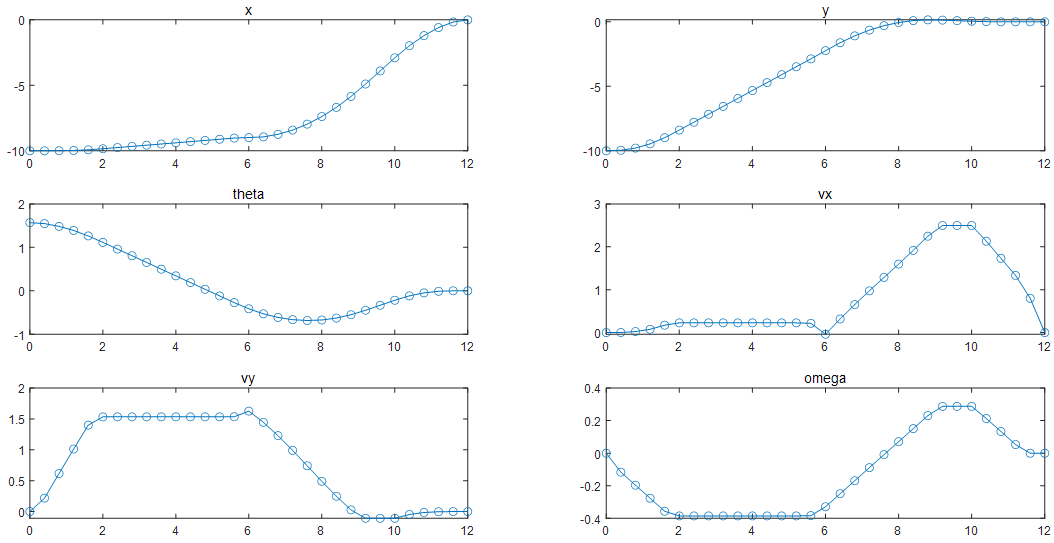
圖表 3規(guī)劃(優(yōu)化求解)的最優(yōu)軌跡對(duì)應(yīng)六個(gè)狀態(tài)量的預(yù)測(cè)值
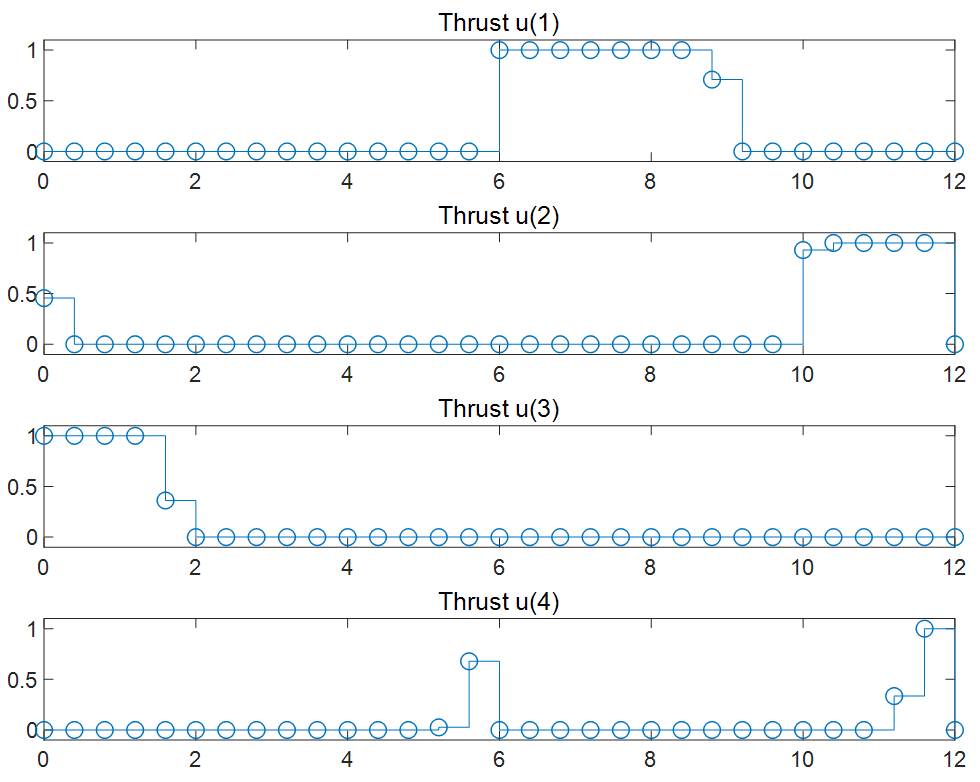
圖表4對(duì)應(yīng)的4個(gè)推力在最優(yōu)軌跡規(guī)劃求解時(shí)的最優(yōu)解序列(MV)
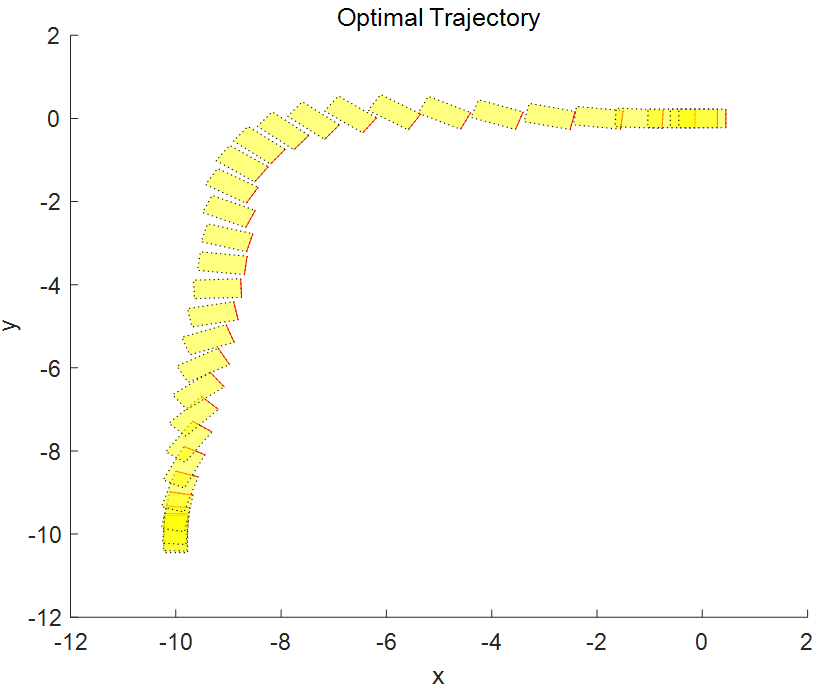
圖表5 機(jī)器人最優(yōu)軌跡的坐標(biāo)和方位信息,從?[-10 -10 pi/2]?到?[0 0 0].
軌跡跟蹤的反饋控制
在通過(guò)開(kāi)環(huán)規(guī)劃得到最優(yōu)軌跡后,需要一個(gè)反饋控制器來(lái)使機(jī)器人沿著路徑移動(dòng)。理論上,可以將開(kāi)環(huán)規(guī)劃的到的最優(yōu)控制輸入 MV(圖表4)直接應(yīng)用于推進(jìn)器實(shí)現(xiàn)前饋控制。但在實(shí)際應(yīng)用中,通常會(huì)需要一個(gè)反饋控制器修正規(guī)劃時(shí)的建模誤差和抑制干擾,如下圖,所以接下來(lái)的任務(wù)我們就是設(shè)計(jì) MPC Controller 和 State Estimator
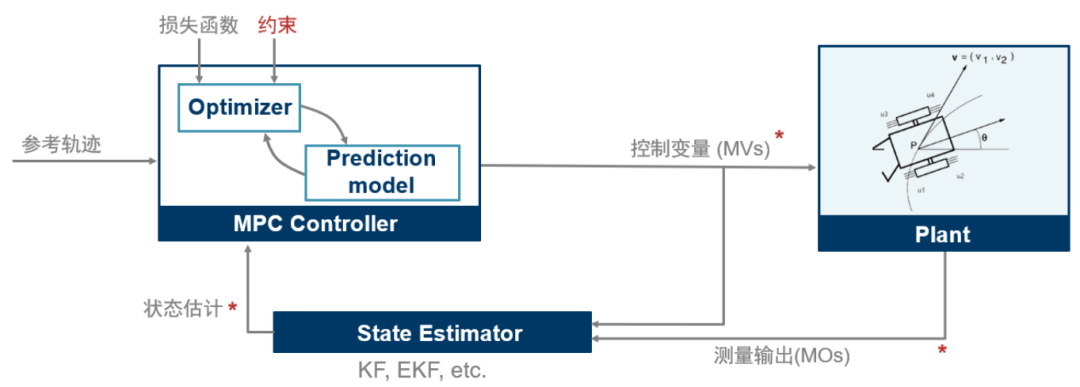
圖表 6
設(shè)計(jì)MPC控制器?
本示例使用典型的非線性 MPC 控制器將機(jī)器人沿著參考軌跡移動(dòng)到最終目標(biāo)位置。在這個(gè)軌跡跟蹤問(wèn)題中,參考軌跡包含所有六個(gè)狀態(tài)的軌跡(輸出的數(shù)量等于狀態(tài)的數(shù)量,ny=nx)。
ny = 6;
nlobj_tracking = nlmpc(nx,ny,nu);
% 對(duì)于狀態(tài)方程和雅可比函數(shù),我們和上面用于軌跡規(guī)劃的MPC中使用同樣的動(dòng)力學(xué)模型
nlobj_tracking.Model.StateFcn=nlobj.、Model.StateFcn;
nlobj_tracking.Jacobian.StateFcn = nlobj.Model.StateJacFcn;
% 指定滾動(dòng)優(yōu)化的預(yù)測(cè)區(qū)間 Prediction Horizon (不需要考慮太遠(yuǎn)的未來(lái)時(shí)間)和控制區(qū)間 Control
% Horizon (例如,僅在前幾個(gè)預(yù)測(cè)區(qū)間允許變量可優(yōu)化 來(lái)減少計(jì)算量)。
nlobj_tracking.PredictionHorizon = 10;
nlobj_tracking.ControlHorizon = 4;
非線性 MPC 的默認(rèn)代價(jià)函數(shù)是一個(gè)適合軌跡跟蹤的標(biāo)準(zhǔn)二次函數(shù)。對(duì)于軌跡跟蹤問(wèn)題,代價(jià)函數(shù)中就 J(zk)=Jy(zk)+Ju(zk)+JΔu(zk), ?本示例對(duì)于跟蹤誤差 Jy(zk) 更看重,所以代價(jià)函數(shù)中的懲罰權(quán)重設(shè)置的大一些,控制抖動(dòng)項(xiàng) JΔu(zk)(MV 率)上的懲罰權(quán)重設(shè)置的小一些,如下:
nlobj_tracking.Weights.ManipulatedVariablesRate = 0.2*ones(1,nu);
nlobj_tracking.Weights.OutputVariables=5*ones(1,nx);
此外,在控制過(guò)程中,u1 和 u2 上下限的約束設(shè)定在 [0,1] 范圍內(nèi),因?yàn)閮蓚€(gè)是同側(cè)相反的方向,所以不需要同時(shí)工作,因此加一個(gè)等式約束,使 u(1)*u(2) 對(duì)所有預(yù)測(cè)區(qū)間都為 0,u3 和 u4 也是同樣。
nlobj_tracking.Optimization.CustomEqConFcn = ...
@(X,U,data) [U(1:end-1,1).*U(1:end-1,2); U(1:end-1,3).*U(1:end-1,4)];
▼
設(shè)計(jì)狀態(tài)估計(jì)器?
在這個(gè)例子中,只測(cè)量了三個(gè)位置狀態(tài) (x、y 和角度)。速度狀態(tài)是沒(méi)有測(cè)量,需要估計(jì)。此處使用擴(kuò)展卡爾曼濾波器 (EKF) 進(jìn)行非線性狀態(tài)估計(jì)。因?yàn)?EKF 需要離散時(shí)間模型,但我們之前的狀態(tài)空間模型是連續(xù)模型,所以使用梯形規(guī)則
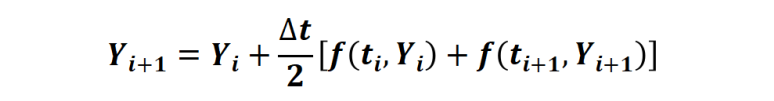
通過(guò)解 nx 個(gè)非線性代數(shù)方程,對(duì)連續(xù)模型進(jìn)行轉(zhuǎn)換,得到離散狀態(tài)方程模型FlyingRobotStateFcnDiscreteTime.m。
其中m中的梯形規(guī)則如下實(shí)現(xiàn):
% 利用上述梯形法則計(jì)算待定系數(shù)xk1
FUN=@(xk1) TrapezoidalRule(xk,xk1,uk,Ts,fk,ffun);
Options=optimoptions('fsolve','Display','none');
xk1 = fsolve(FUN,xk1,Options);
% 梯形法則函數(shù)
function f=TrapezoidalRule(xk,xk1,uk,Ts,fk,ffun)
% 計(jì)算梯形法則中的 f(ti+1,Yi+1)
fk1=ffun(xk1,uk);
% 通過(guò)使 f=0,求得待定系數(shù) xk1.
f=xk1-(xk + (Ts/2)*(fk1+fk));
接下來(lái)將上述離散后的模型給到 EKF 估計(jì)器用于狀態(tài)估計(jì)。
DStateFcn=@(xk,uk,Ts) FlyingRobotStateFcnDiscreteTime(xk,uk,Ts);
DMeasFcn = @(xk) xk(1:3);
% 創(chuàng)建EKF,并設(shè)定測(cè)量噪聲
EKF=extendedKalmanFilter(DStateFcn,DMeasFcn,x0);
EKF.MeasurementNoise = 0.01;
▼
閉環(huán)仿真?
現(xiàn)在圖表6中 MPC Controller, Plant, State Estimator 都有了,可以進(jìn)行追蹤控制的閉環(huán)仿真
設(shè)置好初始條件,仿真 32 個(gè)時(shí)間步,參考軌跡就是在規(guī)劃階段計(jì)算出來(lái)的最優(yōu)狀態(tài)軌跡。使用 nlmpcmove 和 nlmpcmoveopt 命令進(jìn)行閉環(huán)仿真。
Tsteps = 32;
for?k = 1:Tsteps
%獲取被控對(duì)象當(dāng)前時(shí)刻測(cè)量輸出(3維輸出數(shù)據(jù):x、y和角度,含噪聲).
yk = xHistory(k,1:3)' + randn*0.01;
%基于k時(shí)刻的測(cè)量值估計(jì) k 時(shí)刻的狀態(tài)(得到6維狀態(tài)).
xk = correct(EKF, yk);
%nlmpcmove 使用參考軌跡 Xref 進(jìn)行一次 p 個(gè)未來(lái)步長(zhǎng)的優(yōu)化求解,得到當(dāng)前時(shí)刻的優(yōu)化控制uk.
[uk,options]=nlmpcmove(nlobj_tracking,xk,
lastMV,Xref(k:min(k+9,Tsteps),:),[],options);
%預(yù)測(cè)下一時(shí)刻的狀態(tài)和協(xié)方差矩陣,用于下步correct.
predict(EKF,uk,Ts);
%保存控制量并更新控制量用于作用在被控對(duì)象上
uHistory(k,:) = uk'; %#ok<*SAGROW>
lastMV = uk;
%基于當(dāng)前的狀態(tài) xk, 將求解的最優(yōu)的uk作用在被控對(duì)象上(連續(xù)時(shí)間 ODE)并求解 ODE 得到下一時(shí)刻的狀態(tài).
ODEFUN=@(t,xk) FlyingRobotStateFcn(xk,uk);
[TOUT,YOUT] = ode45(ODEFUN,[0 Ts], xHistory(k,:)');
%將狀態(tài)結(jié)果保留下來(lái)用于下個(gè)循環(huán)進(jìn)行測(cè)量.
xHistory(k+1,:) = YOUT(end,:);
end
將規(guī)劃的參考軌跡和實(shí)際的閉環(huán)控制軌跡進(jìn)行比較。
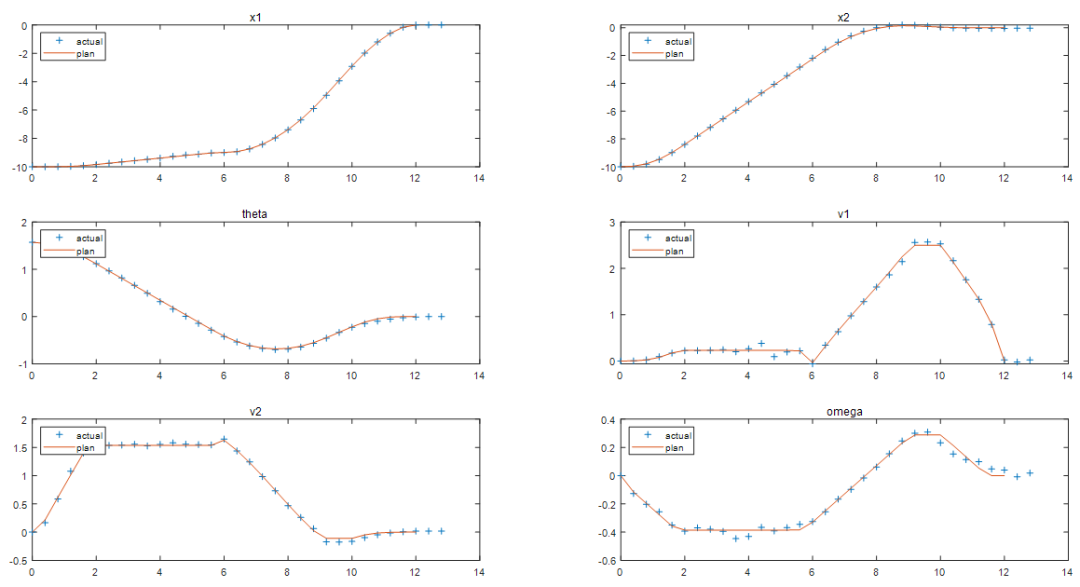
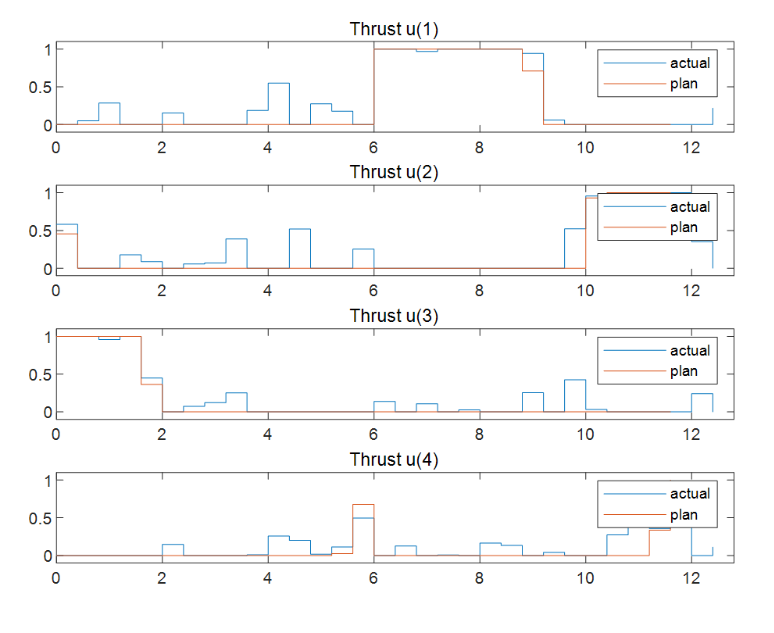
?
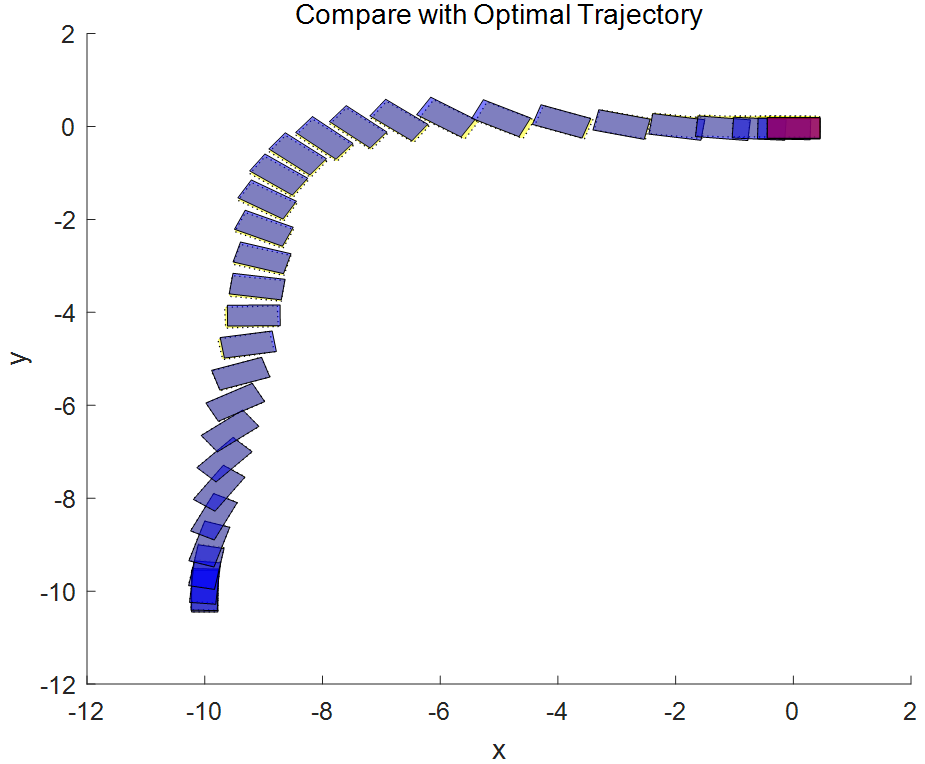
非線性 MPC 反饋控制器成功地移動(dòng)機(jī)器人(藍(lán)色塊),沿著最優(yōu)軌跡(黃色塊),并將其停在最后一個(gè)圖中的最終位置(紅色塊)。當(dāng)然計(jì)算出的實(shí)際燃油損失高于規(guī)劃的油量。產(chǎn)生此結(jié)果的主要原因是,由于我們?cè)诜答伩刂破髦惺褂昧烁r(shí)間域的預(yù)測(cè)和控制范圍最優(yōu)求解,因此與規(guī)劃階段使用全時(shí)間域優(yōu)化問(wèn)題相比,每個(gè)區(qū)間的控制決策都是次優(yōu)的。
第二部分
為被控對(duì)象辨識(shí)神經(jīng)網(wǎng)絡(luò)狀態(tài)
空間模型并用于 MPC
02
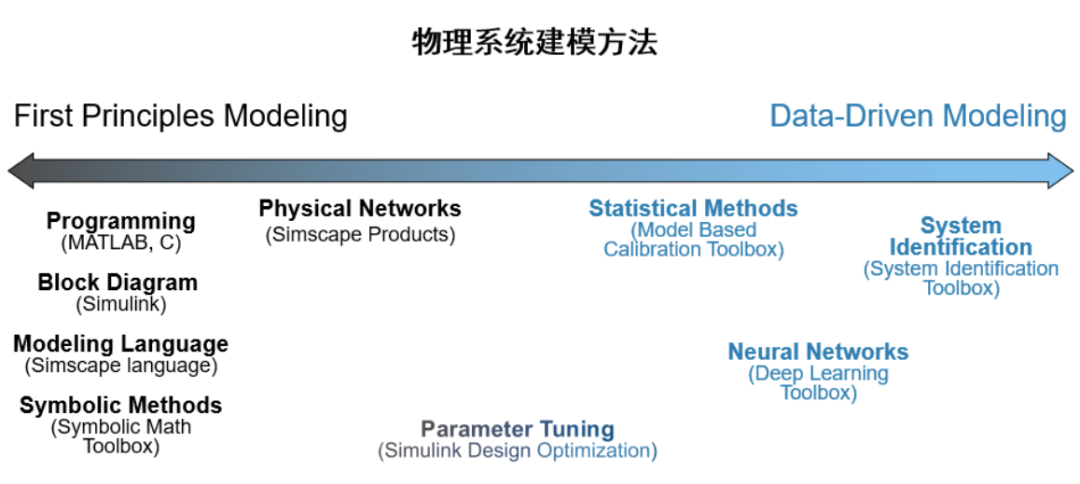
區(qū)別于第一性原理建模的另一種方法是基于實(shí)驗(yàn)數(shù)據(jù)的黑盒建模。對(duì)于動(dòng)態(tài)系統(tǒng)(被控對(duì)象)進(jìn)行數(shù)據(jù)建模的方式有很多,包括系統(tǒng)辨識(shí)(線性系統(tǒng),Grey-Box, Nonlinear 等等,具體見(jiàn)前面文章[5] 數(shù)據(jù)驅(qū)動(dòng)的動(dòng)態(tài)系統(tǒng)建模-系統(tǒng)辨識(shí)),以及深度學(xué)習(xí)(LSTM, Neural ODE 等等,具體見(jiàn)前面的文章[6] 數(shù)據(jù)驅(qū)動(dòng)的動(dòng)態(tài)系統(tǒng)建模-深度學(xué)習(xí))。
我們前面看到 MPC 控制器中進(jìn)行預(yù)測(cè)時(shí)需要被控對(duì)象的狀態(tài)空間方程(Plant Model),也就是飛行器的狀態(tài)空間方程腳本。在工業(yè)應(yīng)用中,有時(shí)很難利用第一性原理手動(dòng)推導(dǎo)得到形如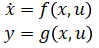 ?的非線性狀態(tài)空間動(dòng)態(tài)模型。在這種情況下我們可以訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型,
?的非線性狀態(tài)空間動(dòng)態(tài)模型。在這種情況下我們可以訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型,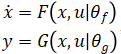 ,其中 F 和 G 是兩個(gè)神經(jīng)網(wǎng)絡(luò)模型,然后作為對(duì)象模型放到 MPC 中用于預(yù)測(cè)過(guò)程。示意如下
,其中 F 和 G 是兩個(gè)神經(jīng)網(wǎng)絡(luò)模型,然后作為對(duì)象模型放到 MPC 中用于預(yù)測(cè)過(guò)程。示意如下
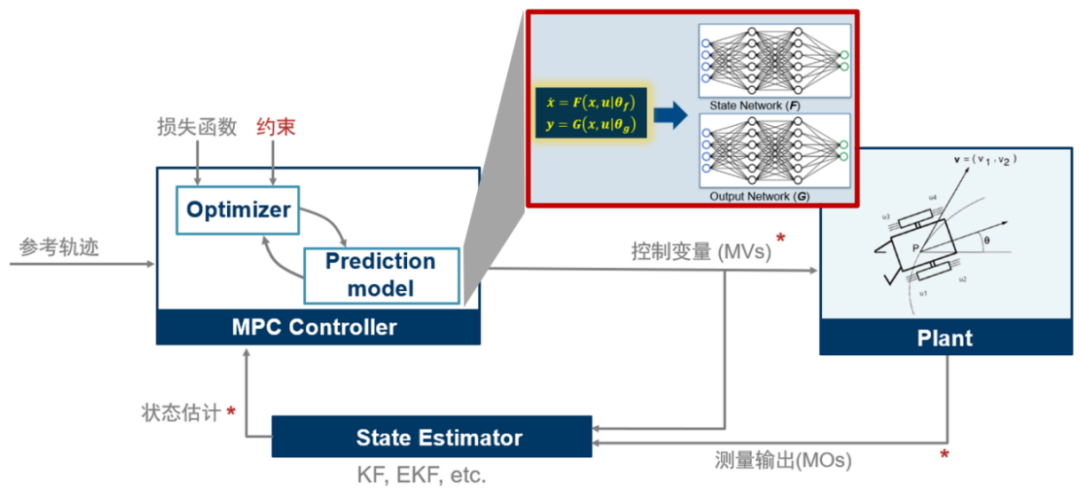
神經(jīng)網(wǎng)絡(luò) ODE 算法與訓(xùn)練
Neural ODE 思想介紹
神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型是基于神經(jīng)網(wǎng)絡(luò) ODE 實(shí)現(xiàn)的,這里可以簡(jiǎn)單介紹一下實(shí)現(xiàn)思路(在前面的文章 數(shù)據(jù)驅(qū)動(dòng)的動(dòng)態(tài)系統(tǒng)建模-深度學(xué)習(xí)中簡(jiǎn)單介紹了訓(xùn)練的思想。在視頻[7]
https://www.bilibili.com/video/BV1sU4y1z7Qb/中介紹了實(shí)現(xiàn)過(guò)程)。
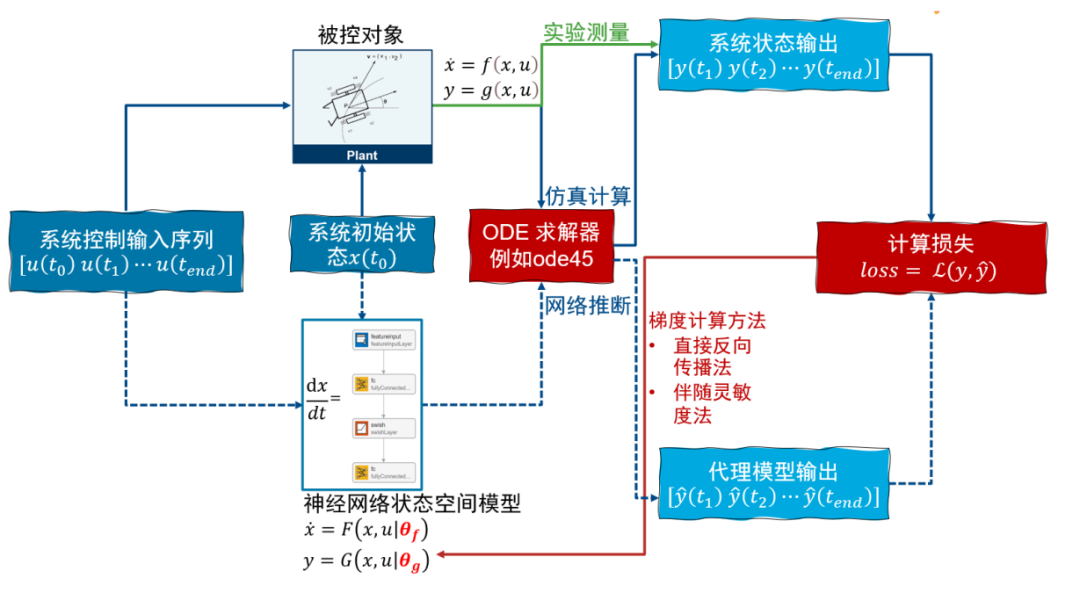
對(duì)于一個(gè)被控對(duì)象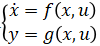 初始狀態(tài) x(t0),作用一個(gè)控制輸入序列 [u(t0)u(t1)···u(tend)],通過(guò)實(shí)驗(yàn)測(cè)量或者仿真計(jì)算(使用 ode 求解器,例如 ode45),可以得到系統(tǒng)的輸出 [y(t1)y(t2)···y(tend)],作為真值。我們的目的是訓(xùn)練神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型的參數(shù)?[θf(wàn),θg] 使得在相同的初始狀態(tài)和作用相同的控制輸入序列的情況下,通過(guò)對(duì)神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型
初始狀態(tài) x(t0),作用一個(gè)控制輸入序列 [u(t0)u(t1)···u(tend)],通過(guò)實(shí)驗(yàn)測(cè)量或者仿真計(jì)算(使用 ode 求解器,例如 ode45),可以得到系統(tǒng)的輸出 [y(t1)y(t2)···y(tend)],作為真值。我們的目的是訓(xùn)練神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型的參數(shù)?[θf(wàn),θg] 使得在相同的初始狀態(tài)和作用相同的控制輸入序列的情況下,通過(guò)對(duì)神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型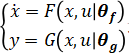
進(jìn)行計(jì)算得到的輸出序列 [?(t1)?(t2)···?(tend)] 與系統(tǒng)的真值 [y(t1)y(t2)···y(tend)] 盡量接近,也就是loss=L{?(t),y(t)} 越小越好,其中 L 可以是任何自定義的損失函數(shù)。計(jì)算神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型系統(tǒng)輸出的過(guò)程可以使用 ode 求解器,例如 ode45, 先計(jì)算狀態(tài)轉(zhuǎn)移方程
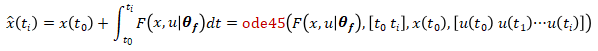
然后計(jì)算測(cè)量輸出方程
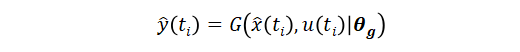
這樣就可以計(jì)算損失函數(shù),接下來(lái)可以按神經(jīng)網(wǎng)絡(luò)的訓(xùn)練步驟對(duì)參數(shù)?[θf(wàn),θg]?進(jìn)行訓(xùn)練。
Neural ODE 訓(xùn)練過(guò)程實(shí)現(xiàn)
我們通過(guò)示意腳本來(lái)介紹訓(xùn)練的過(guò)程,主要包含六步。
將整個(gè)數(shù)據(jù)集?(一輪 /epoch) 分成小的 chrunk(minibatches).
在每次迭代 (each minibatch), 進(jìn)行預(yù)處理.
將輸入數(shù)據(jù)傳給網(wǎng)絡(luò)進(jìn)行前饋計(jì)算?(inference).
和真值進(jìn)行比較?(i.e. compute loss function).
自動(dòng)微分?(compute gradients of each layer or operation
in the network w.r.t. loss)
%遍歷輪數(shù)
for?epoch= 1:numEpochs
%每一輪的迭代數(shù),一次迭代一個(gè)minibatch用于更新一次模型參數(shù)
for i= 1:numIterperEpoch ? ?
iter=iter + 1;
????????%創(chuàng)建每次迭代用于訓(xùn)練模型參數(shù)的 minibatch?
????????數(shù)據(jù)集,包含控制序列和輸出序列(真值)
[dlU,dlY,timeIds]=
createMiniBatch(neuralOdeTimesteps,?
UtrainCell,YtrainCell);
…
%@modelGradients 函數(shù)為了計(jì)算損失對(duì)模型
參數(shù)的梯度,總共完成了三個(gè)任務(wù):
· 將輸入數(shù)據(jù)傳給網(wǎng)絡(luò)進(jìn)行前饋計(jì)算(inference).
· 和真值進(jìn)行比較計(jì)算loss
(i.e. compute loss function).
· 計(jì)算梯度
[grads,loss]=dlfeval(@modelGradients,
dlX0,dlYTarge,dlU(或者插值體),
parameters,tspan);
%利用計(jì)算得到的梯度使用優(yōu)化求解器 adam?
更新模型權(quán)重和偏置
[parameters,averageGrad2,averageSqGrad2]=
adamupdate(parameters,grads,averageGrad,
averageSqGrad,iter,learnRate,gradDecay,
sqGradDecay);
end
end
%modelGradient 函數(shù)完成三個(gè)任務(wù)
function[grad,loss]=modelGradients(dlTarget,
dlX0, dlU, params, tspan)
%neuralStateMode l 函數(shù)(接下來(lái)列出來(lái)的函數(shù))
就是利用初始狀態(tài)和控制序列進(jìn)行網(wǎng)絡(luò)推斷計(jì)算。
dlY= neuralStateModel(dlX0, dlU, params, tspan);
%利用模型推斷結(jié)果和真值進(jìn)行損失計(jì)算
loss= huber(dlY, dlTarget);
%利用損失進(jìn)行梯度計(jì)算
grad= dlgradient(loss, params);
end
function Y= neuralStateModel(stateX0, controlX, Params, tspan)
%odeModel 函數(shù)對(duì)應(yīng)著狀態(tài)方程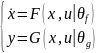 中的F(x,u|θf(wàn)),基于初始狀態(tài),和當(dāng)前神經(jīng)網(wǎng)絡(luò)參數(shù)下的狀態(tài)方程,利用 dlode45 進(jìn)行積分求解,得到對(duì)應(yīng)的模型推斷的狀態(tài)序列 stateX
中的F(x,u|θf(wàn)),基于初始狀態(tài),和當(dāng)前神經(jīng)網(wǎng)絡(luò)參數(shù)下的狀態(tài)方程,利用 dlode45 進(jìn)行積分求解,得到對(duì)應(yīng)的模型推斷的狀態(tài)序列 stateX
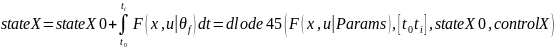
%odeModel 對(duì)應(yīng) F
stateX= dlode45(@(t,y,p)odeModel
(t,y,p,controlX),[0tspan],
stateX0,Params.neuralode);
% 下面的代碼利用計(jì)算的狀態(tài)序列和輸入的控制序列,通過(guò)構(gòu)造G(x,u|θg)來(lái)計(jì)算得到測(cè)量輸出Y
stateControl = cat(1,stateX,controlX);
…(此處省去多層連接)
Y = fullyconnect(stateControl,Param.fc1.Weights,);
end
function dxdt = odeModel(t,y,thetaODE,controlu)
% 這個(gè)函數(shù)就是構(gòu)造狀態(tài)方程 ?=F(x,u|θf(wàn)) 中的右半部分 F(x,u|θf(wàn))
dxdt = cat(1,u,y);
dxdt = thetaODE.fc1.Weights*dxdt + thetaODE.fc1.Bias;
… (可以自定義層邏輯)
end
其中利用損失進(jìn)行梯度計(jì)算時(shí),可以直接用反向傳播方法進(jìn)行自動(dòng)微分,根據(jù) BP 算法原理,要保留在前向計(jì)算過(guò)程中模型中的激活值,尤其進(jìn)行 ode 積分求解時(shí),積分時(shí)長(zhǎng) tspan 較長(zhǎng),或者積分步長(zhǎng)較小導(dǎo)致積分步數(shù)過(guò)多,都會(huì)使網(wǎng)絡(luò)前向計(jì)算保留較多的激活值(用于反向傳播進(jìn)行自動(dòng)微分),這就對(duì)內(nèi)存有了較高的要求。為了解決這個(gè)問(wèn)題,計(jì)算梯度的時(shí)候,原文[8]使用了伴隨梯度算法(adjoint method), 把梯度的計(jì)算變成了求解帶初值的另外一個(gè)常微分方程問(wèn)題,只需要當(dāng)前激活作為初值,直接可以使用 ODE 求解器計(jì)算這個(gè)新的常微分方程得到各個(gè)時(shí)刻損失對(duì)網(wǎng)絡(luò)參數(shù)的梯度,而不需要保留前向過(guò)程中的激活。具體的細(xì)節(jié)可以看原論文[8]證明。具體使用哪種微分計(jì)算可以通過(guò)設(shè)置 dlode45 這個(gè)針對(duì)神經(jīng)網(wǎng)絡(luò)微分方程的 ODE 求解器的屬性來(lái)實(shí)現(xiàn)[9]。?
工程師更友好的神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型辨識(shí)
通過(guò)上述腳本實(shí)現(xiàn)模型的訓(xùn)練,可以得到一個(gè)訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型。對(duì)于領(lǐng)域工程師,MATLAB 提供了一種更集成的方式實(shí)現(xiàn)上述過(guò)程,將上述的六個(gè)步驟集成在一個(gè) nlssest 函數(shù)中,我們通過(guò)這種簡(jiǎn)單易用的方式對(duì)飛行機(jī)器人被控對(duì)象模型進(jìn)行神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型的辨識(shí)。?
%創(chuàng)建一個(gè) idNeuralStateSpace 對(duì)象,包含6個(gè)狀態(tài)量和4個(gè)控制輸入.
obj=idNeuralStateSpace(6,NumInputs=4);
%系統(tǒng)因?yàn)闋顟B(tài)量就是測(cè)量輸出,所以只需要?jiǎng)?chuàng)建一個(gè)狀態(tài)方程 ?=F(x,u|θf(wàn)),測(cè)量方程是個(gè)恒等式 (G(x,u|θg)=I,即 Y=I*X),自定義狀態(tài)方程的網(wǎng)絡(luò)節(jié)點(diǎn)數(shù)和層數(shù).
obj.StateNetwork = createMLPNetwork(obj,'state',...
LayerSizes=[32 32 32],...
Activations='tanh',...
WeightsInitializer="glorot",...
BiasInitializer="zeros");
% 設(shè)置訓(xùn)練選項(xiàng)
options = nssTrainingOptions('adam');
% 使用nlssest利用實(shí)驗(yàn)數(shù)據(jù)/仿真數(shù)據(jù)對(duì)構(gòu)建的進(jìn)行參數(shù)的訓(xùn)練
% 完成了上述六個(gè)步驟
nss=nlssest(U,X,obj,options,'UseLastExperimentForValidation',true);
訓(xùn)練完成得到狀態(tài)空間模型 nss 后,可以使用 generateMATLABFunction 自動(dòng)為這個(gè)神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型生成狀態(tài)方程和雅可比函數(shù)解析式。
generateMATLABFunction(nss,'nssStateFcn');
function [A, B] = nssStateFcnJacobian(x,u)
% 這是自動(dòng)生成的神經(jīng)網(wǎng)絡(luò)狀態(tài)模型的雅可比函數(shù)
? ? %# codegen
persistent StateNetwork
MATname = 'nssStateFcnData';
if isempty(StateNetwork)
StateNetwork = coder.load(MATname);
end
out = [x;u];
J = eye(length(out));
% 第一層隱含層
Jfc=StateNetwork.fc1.Weights;
out=StateNetwork.fc1.Weights*out+StateNetwork.fc1.Bias;
Jac = deep.internal.coder.jacobian.tanh(out);
…
% output layer
J = StateNetwork.output.Weights*J;
end
將訓(xùn)練的神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型作為MPC中的預(yù)測(cè)模型
我們把自動(dòng)生成生成的狀態(tài)方程和雅可比函數(shù)賦給 MPC 的模型。
nlobj_tracking.Model.StateFcn =
'nssStateFcn';
nlobj_tracking.Jacobian.StateFcn=
'nssStateFcnJacobian';
使用含有神經(jīng)網(wǎng)絡(luò)狀態(tài)空間模型的 MPC 再次進(jìn)行閉環(huán)仿真,代碼跟上述使用第一原理的 MPC 一樣,查看追蹤效果。?
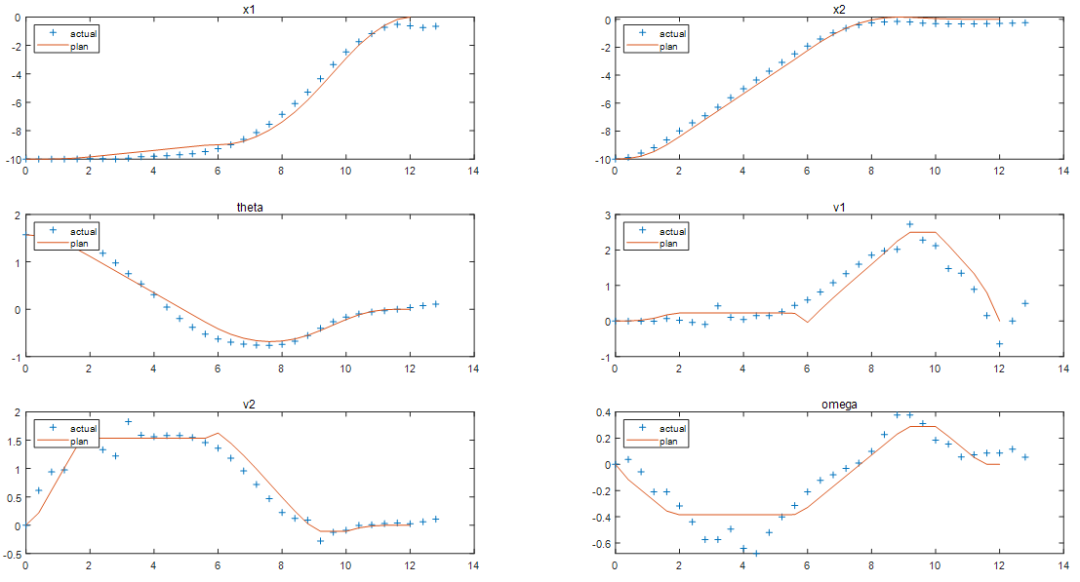
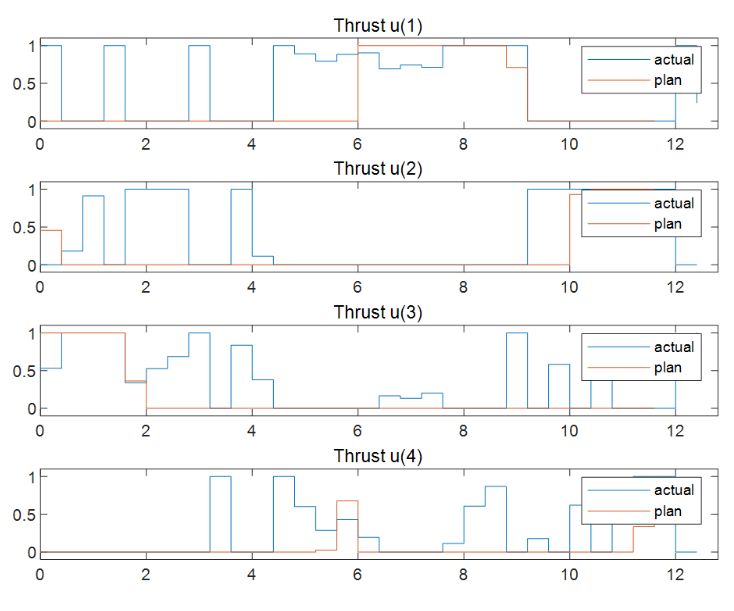
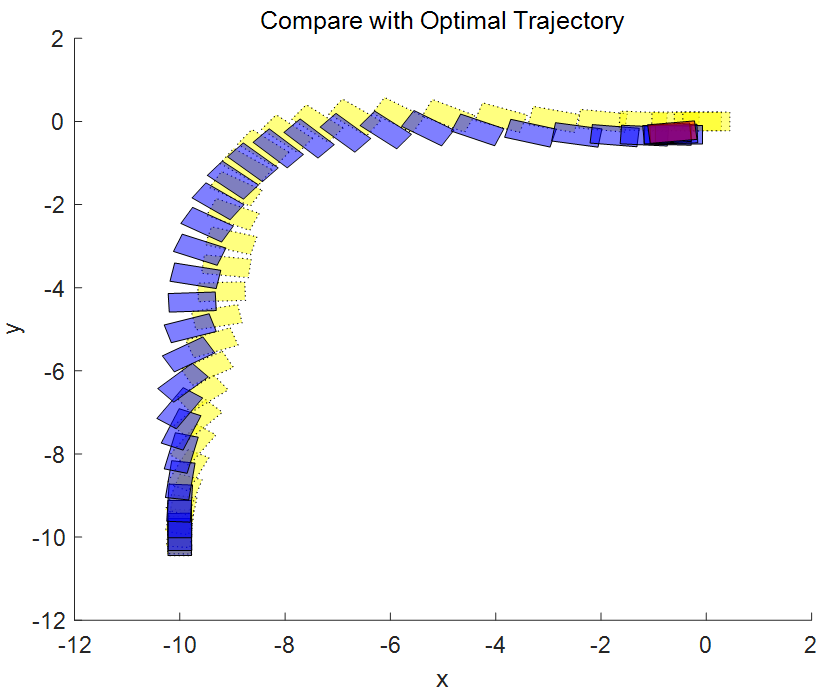
將計(jì)劃的閉環(huán)軌跡與實(shí)際的閉環(huán)軌跡進(jìn)行比較。響應(yīng)與基于第一性原理的預(yù)測(cè)模型結(jié)果相對(duì)接近。
總結(jié)
本文旨在提供一種將 AI 和模型預(yù)測(cè)控制結(jié)合的方法,可以將訓(xùn)練的神經(jīng)網(wǎng)絡(luò)狀態(tài)空間方程的模型給到模型預(yù)測(cè)控制器中使用,從而在第一原理模型不存在的情況下也可以實(shí)現(xiàn)預(yù)測(cè)控制。對(duì)于模型預(yù)測(cè)控制本身比較復(fù)雜,包括類(lèi)型選擇和加速等等。
編輯:黃飛
?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論