 電子發燒友App
電子發燒友App


近年來,深度學習在很多機器學習領域都有著非常出色的表現,在圖像識別、語音識別、自然語言處理、機器人、網絡廣告投放、醫學自動診斷和金融等領域有著廣泛應用。面對繁多的應用場景,深度學習框架有助于建模者節省大量而繁瑣的外圍工作,更聚焦業務場景和模型設計本身。
使用深度學習框架完成模型構建有如下兩個優勢:
節省編寫大量底層代碼的精力:屏蔽底層實現,用戶只需關注模型的邏輯結構。同時,深度學習工具簡化了計算,降低了深度學習入門門檻。
省去了部署和適配環境的煩惱:具備靈活的移植性,可將代碼部署到CPU/GPU/移動端上,選擇具有分布式性能的深度學習工具會使模型訓練更高效。
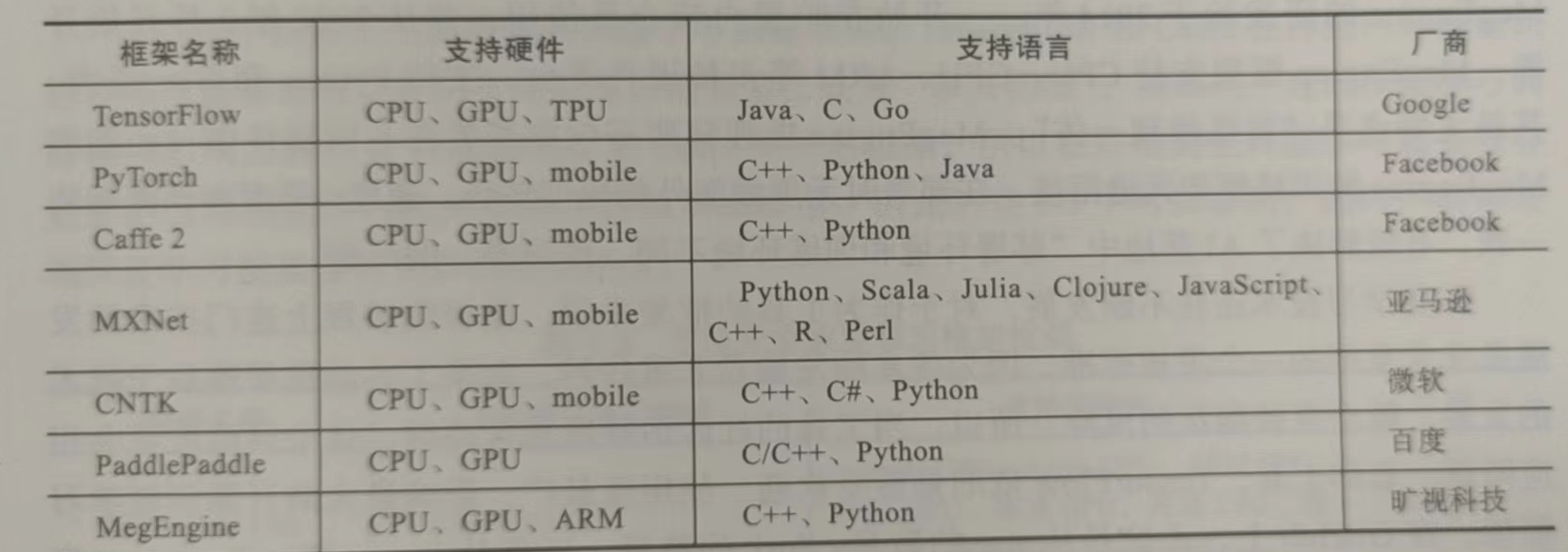
因此,在開始深度學習項目之前,選擇一個合適的框架是非常重要的。目前,全世界最為流行的深度學習框架有PaddlePaddle、Tensorflow、Caffe、Theano、MXNet、Torch和PyTorch等。下面我們就來介紹一下目前主流的、以及一些剛開源但表現非常優秀的深度學習框架的各自特點,希望能夠幫助大家在學習工作時作出合適的選擇。
Theano
作為深度學習框架的祖師爺,Theano 的誕生為人類叩開了新時代人工智能的大門。Theano 的開發始于 2007 年的蒙特利爾大學,早期雛形由兩位傳奇人物 Yoshua Bengio 和 Ian Goodfellow 共同打造,并于開源社區中逐漸壯大。
Theano 基于 Python,是一個擅長處理多維數組的庫,十分適合與其它深度學習庫結合起來進行數據探索。它設計的初衷是為了執行深度學習中大規模神經網絡算法的運算。其實,Theano 可以被更好地理解為一個數學表達式的編譯器:用符號式語言定義你想要的結果,該框架會對你的程序進行編譯,在 GPU 或 CPU 中高效運行。
Theano 的出現為人工智能在新時代的發展打下了強大的基礎,在過去的很長一段時間內,Theano 都是深度學習開發與研究的行業標準。往后也有大量基于 Theano 的開源深度學習庫被開發出來,包括 Keras、Lasagne 和 Blocks,甚至后來火遍全球的 TensorFlow 也有很多與 Theano 類似的功能。
隨著更多優秀的深度學習開源框架陸續涌現,Theano 逐漸淡出了人們的視野。2013 年,Theano 創始者之一 Ian Goodfellow 加入 Google 開發 TensorFlow,標志著 Theano 正式退出歷史舞臺。目前僅有部分研究領域的學者會使用 Theano 進行一些學術研究。
Caffe&Caffe2
Caffe 是一個優先考慮表達、速度和模塊化來設計的框架,它由賈揚清和伯克利人工智能實驗室研究開發。支持 C、C++、Python等接口以及命令行接口。它以速度和可轉性以及在卷積神經網絡建模中的適用性而聞名。Caffe可以每天處理超過六千萬張圖像,只需單個NVIDIA K40 GPU,其中 1毫秒/圖像用于推理,4毫秒/圖像用于學習。
使用Caffe庫的好處是從深度網絡存儲庫“Caffe 模型Zoo”訪問可用網絡,這些網絡經過預先培訓,可以立即使用。通過Caffe Model Zoo框架可訪問用于解決深度學習問題的預訓練網絡、模型和權重。這些模型可完成簡單的遞歸、大規模視覺分類、用于圖像相似性的SiameSE網絡、語音和機器人應用等。
不過,Caffe 不支持精細粒度網絡層,給定體系結構,對循環網絡和語言建模的總體支持相當差,必須用低級語言建立復雜的層類型,使用門檻很高。Caffe2是由Facebook組織開發的深度學習模型,雖然使用門檻不像Caffe那樣高,但仍然讓不那么看重性能的開發者望而卻步。另外,Caffe2繼承了Caffe的優點,在速度上令人印象深刻。Facebook 人工智能實驗室與應用機器學習團隊合作,利用Caffe2大幅加速機器視覺任務的模型訓練過程,僅需 1 小時就訓練完ImageNet 這樣超大規模的數據集。2018 年 3 月底,Facebook 將 Caffe2 并入 PyTorch,一度引起轟動。
Tensorflow
TensorFlow 是 Google 于 2015 年開源的深度學習框架。TensorFlow前身是谷歌的神經網絡算法庫 DistBelief,由谷歌人工智能團隊谷歌大腦(Google Brain)開發和維護,擁有包括 TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud 在內的多個項目以及各類應用程序接口。
TensorFlow 讓用戶可以快速設計深度學習網絡,將底層細節進行抽象,而不用耗費大量時間編寫底層 CUDA 或 C++ 代碼。TensorFlow 在很多方面擁有優異的表現,比如設計神經網絡結構的代碼的簡潔度,分布式深度學習算法的執行效率,還有部署的便利性(能夠全面地支持各種硬件和操作系統)。
TensorFlow在很大程度上可以看作是Theano的后繼者,不僅因為它們有很大一批共同的開發者,而且它們還擁有相近的設計理念,都是基于計算圖實現自動微分系統。TensorFlow 使用數據流圖進行數值計算,圖中的節點代表數學運算,而圖中的邊則代表在這些節點之間傳遞的多維數組(張量)。
TensorFlow編程接口支持Python、C++、Java、Go、R和Haskell API的alpha版本。此外,TensorFlow還可在GoogleCloud和AWS中運行。TensorFlow還支持 Windows 7、Windows 10和Windows Server 2016。由于TensorFlow使用C++ Eigen庫,所以庫可在ARM架構上編譯和優化。這也就意味著用戶可以在各種服務器和移動設備上部署自己的訓練模型,無須執行單獨的模型解碼器或者加載Python解釋器。
TensorFlow構建了活躍的社區,完善的文檔體系,大大降低了我們的學習成本,不過社區和文檔主要以英文為主,中文支持有待加強。另外,TensorFlow有很直觀的計算圖可視化呈現。模型能夠快速的部署在各種硬件機器上,從高性能的計算機到移動設備,再到更小的更輕量的智能終端。
不過,對于深度學習的初學者而言,TensorFlow的學習曲線太過陡峭,需要不斷練習、探索社區并繼續閱讀文章來掌握TensorFlow的訣竅。
Keras
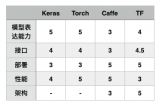
Keras用Python編寫,可以在TensorFlow(以及CNTK和Theano)之上運行。TensorFlow的接口具備挑戰性,因為它是一個低級庫,新用戶可能會很難理解某些實現。而Keras是一個高層的API,它為快速實驗而開發。因此,如果希望獲得快速結果,Keras會自動處理核心任務并生成輸出。Keras支持卷積神經網絡和遞歸神經網絡,可以在CPU和GPU上無縫運行。
深度學習的初學者經常會抱怨:無法正確理解復雜的模型。如果你是這樣的用戶,Keras便是你的正確選擇。它的目標是最小化用戶操作,并使其模型真正容易理解。Keras的出現大大降低了深度學習應用的門檻,通過Keras的API可以通過數行代碼就構建一個網絡模型,曾幾何時,Keras+Theano,Keras+CNTK的模式深得開發者喜愛。目前Keras整套架構已經封裝進了TensorFlow,在TF.keras上可以完成Keras的所有事情。
如果你熟悉Python,并且沒有進行一些高級研究或開發某種特殊的神經網絡,那么Keras適合你。Keras的重點更多地放在取得成果上,而不是被模型的復雜之處所困擾。因此,如果有一個與圖像分類或序列模型相關的項目,可以從Keras開始,很快便可以構建出一個工作模型。Keras也集成在TensorFlow中,因此也可以使用Tf.keras構建模型。
Pytorch
2017年1月,Facebook人工智能研究院(FAIR)團隊在GitHub上開源了PyTorch,并迅速占領GitHub熱度榜榜首。PyTorch的歷史可追溯到2002年就誕生于紐約大學的Torch。Torch使用了一種不是很大眾的語言Lua作為接口。Lua簡潔高效,但由于其過于小眾,用的人不是很多。在2017年,Torch的幕后團隊推出了PyTorch。PyTorch不是簡單地封裝Lua Torch提供Python接口,而是對Tensor之上的所有模塊進行了重構,并新增了最先進的自動求導系統,成為當下最流行的動態圖框架。
Pytorch官網的標題語簡明地描述了Pytorch的特點以及將要發力的方向。Pytorch在學術界優勢很大,關于用到深度學習模型的文章,除了Google的,其他大部分都是通過Pytorch進行實驗的,究其原因,一是Pytorch庫足夠簡單,跟NumPy,SciPy等可以無縫連接,而且基于tensor的GPU加速非常給力,二是訓練網絡迭代的核心——梯度的計算,Autograd架構(借鑒于Chainer),基于Pytorch,我們可以動態地設計網絡,而無需笨拙地定義靜態網絡圖,才能去進行計算,想要對網絡有任務修改,都要從頭開始構建靜態圖。基于簡單,靈活的設計,Pytorch快速成為了學術界的主流深度學習框架。
Pytorch的缺點則是前期缺乏對移動端的支持,因此在商用領域的普及度不及 TensorFlow 。在 2019 年,Facebook 推出 PyTorch Mobile 框架,彌補了 PyTorch 在移動端的不足,使得其在商用領域的發展有望趕超 TensorFlow 。不過現在,如果稍微深入了解TensorFlow和Pytorch,就會發現他們越來越像,TF加入了動態圖架構,Pytorch致力于其在工業界更加易用。打開各自的官網,你也會發現文檔風格也越發的相似。
PyTorch Lightning
PyTorch非常易于使用,可以構建復雜的AI模型。但是一旦研究變得復雜,并且將諸如多GPU訓練,16位精度和TPU訓練之類的東西混在一起,用戶很可能會引入錯誤。PyTorch Lightning就可以完全解決這個問題。Lightning會構建你的PyTorch代碼,以便可以抽象出訓練的細節。這使得AI研究可擴展且可快速迭代。這個項目在GitHub上斬獲了6.6k星。
Lightning將DL/ML代碼分為三種類型:研究代碼、工程代碼、非必要代碼。使用Lightning就只需要專注于研究代碼,不需要寫一大堆的 .cuda() 和 .to(device),Lightning會幫你自動處理。如果要新建一個tensor,可以使用type_as來使得新tensor處于相同的處理器上。此外,它會將工程代碼參數化,減少這部分代碼會使得研究代碼更加清晰,整體也更加簡潔。
PyTorch Lightning 的創建者WilliamFalcon,現在在紐約大學的人工智能專業攻讀博士學位,并在《福布斯》擔任AI特約作者。他表示,PyTorch Lightning是為從事AI研究的專業研究人員和博士生創建的。該框架被設計為具有極強的可擴展性,同時又使最先進的AI研究技術(例如TPU訓練)變得微不足道。
PaddlePaddle
PaddlePaddle 的前身是百度于 2013 年自主研發的深度學習平臺Paddle,且一直為百度內部工程師研發使用。PaddlePaddle 在深度學習框架方面,覆蓋了搜索、圖像識別、語音語義識別理解、情感分析、機器翻譯、用戶畫像推薦等多領域的業務和技術。在 2016 年的百度世界大會上,前百度首席科學家 Andrew Ng首次宣布將百度深度學習平臺對外開放,命名 PaddlePaddle,中文譯名“飛槳”。
PaddlePaddle同時支持稠密參數和稀疏參數場景的超大規模深度學習并行訓練,支持千億規模參數、數百個幾點的高效并行訓練,也是最早提供如此強大的深度學習并行技術的深度學習框架。PaddlePaddle擁有強大的多端部署能力,支持服務器端、移動端等多種異構硬件設備的高速推理,預測性能有顯著優勢。PaddlePaddle已經實現了API的穩定和向后兼容,具有完善的中英雙語使用文檔,形成了易學易用、簡潔高效的技術特色。
2019 年,百度還推出了多平臺高性能深度學習引擎Paddle Lite(Paddle Mobile 的升級版),為 PaddlePaddle 生態完善了移動端的支持。
Deeplearning4j
DL4J 是由來自舊金山和東京的一群開源貢獻者協作開發的。2014 年末,他們將其發布為 Apache 2.0 許可證下的開源框架。主要是作為一種平臺來使用,通過這種平臺來部署商用深度學習算法。創立于 2014 年的 Skymind 是 DL4J 的商業支持機構。2017 年 10 月,Skymind 加入了 Eclipse 基金會,并且將 DL4J 貢獻給開源 Java Enterprise Edition 庫生態系統。
DL4J是為java和jvm編寫的開源深度學習庫,支持各種深度學習模型。它具有為 Java 和 Scala 語言編寫的分布式深度學習庫,并且內置集成了 Apache Hadoop 和 Spark。Deeplearning4j 有助于彌合使用Python 語言的數據科學家和使用 Java 語言的企業開發人員之間的鴻溝,從而簡化了在企業大數據應用程序中部署深度學習的過程。
DL4J主要有三大優勢:
1. Python 可與 Java、Scala、Clojure 和 Kotlin 實現互操作性。Python為數據科學家所廣泛采用,而大數據編程人員則在 Hadoop 和 Spark 上使用 Java 或 Scala 來開展工作。DL4J 填補了之間的鴻溝,開發人員因而能夠在 Python 與 JVM 語言(例如,Java、Scala、Clojure 和 Kotlin)之間遷移。通過使用 Keras API,DL4J 支持從其他框架(例如,TensorFlow、Caffe、Theano 和 CNTK)遷移深度學習模型。甚至有人建議將 DL4J 作為 Keras 官方貢獻的后端之一。
2. 分布式處理。DL4J 可在最新分布式計算平臺(例如,Hadoop 和 Spark)上運行,并且可使用分布式 CPU 或 GPU 實現加速。通過使用多個 GPU,DL4J 可以實現與 Caffe 相媲美的性能。DL4J 也可以在許多云計算平臺上運行。
3. 并行處理。DL4J 包含單線程選項和分布式多線程選項。這種減少迭代次數的方法可在集群中并行訓練多個神經網絡。因此,DL4J 非常適合使用微服務架構來設計應用程序。
CNTK
2015年8月,微軟公司在CodePlex上宣布由微軟研究院開發的計算網絡工具集CNTK將開源。5個月后,2016年1月25日,微軟公司在他們的GitHub倉庫上正式開源了CNTK。早在2014年,在微軟公司內部,黃學東博士和他的團隊正在對計算機能夠理解語音的能力進行改進,但當時使用的工具顯然拖慢了他們的進度。于是,一組由志愿者組成的開發團隊構想設計了他們自己的解決方案,最終誕生了CNTK。
根據微軟開發者的描述,CNTK的性能比Caffe、Theano、TensoFlow等主流工具都要強。CNTK支持CPU和GPU模式,和TensorFlow/Theano一樣,它把神經網絡描述成一個計算圖的結構,葉子節點代表輸入或者網絡參數,其他節點代表計算步驟。CNTK 是一個非常強大的命令行系統,可以創建神經網絡預測系統。
CNTK 最初是出于在 Microsoft 內部使用的目的而開發的,一開始甚至沒有Python接口,而是使用了一種幾乎沒什么人用的語言開發的,而且文檔有些晦澀難懂,推廣不是很給力,導致現在用戶比較少。但就框架本身的質量而言,CNTK表現得比較均衡,沒有明顯的短板,并且在語音領域效果比較突出。
MindSpore
MindSpore是華為在今年3月召開的開發者大會上正式開源,MindSpore是一款支持端邊云全場景的深度學習訓練推理框架,當前主要應用于計算機視覺、自然語言處理等AI領域,旨在為數據科學家和算法工程師提供設計友好、運行高效的開發體驗,提供昇騰AI處理器原生支持及軟硬件協同優化。
MindSpore的特性是可以顯著減少訓練時間和成本(開發態)、以較少的資源和最高能效比運行(運行態),同時適應包括端、邊緣與云的全場景(部署態),強調了軟硬件協調及全場景部署的能力。因此,使用MindSpore的優勢可以總結為四點:
簡單的開發體驗。幫助開發者實現網絡自動切分,只需串行表達就能實現并行訓練,降低門檻,簡化開發流程;
靈活的調試模式。具備訓練過程靜態執行和動態調試能力,開發者通過變更一行代碼即可切換模式,快速在線定位問題;
充分發揮硬件潛能。最佳匹配昇騰處理器,最大程度地發揮硬件能力,幫助開發者縮短訓練時間,提升推理性能;
全場景快速部署。支持云、邊緣和手機上的快速部署,實現更好的資源利用和隱私保護,讓開發者專注于AI應用的創造。
MegEngine(天元)
MegEngine(天元)是今年3月正式開源的工業級深度學習框架,曠世也成為國內第一家開源AI框架的AI企業。天元可幫助開發者用戶借助友好的編程接口,進行大規模深度學習模型訓練和部署。架構上天元具體分為計算接口、圖表示、優化與編譯、運行時管理和計算內核五層,可極大簡化算法開發流程,實現了模型訓練速度和精度的無損遷移,支持動靜態的混合編程和模型導入,內置高性能計算機視覺算子,尤其適用于大模型算法訓練。
若說谷歌TensorFlow采用利于部署的靜態圖更適用于工業界,而Facebook PyTorch采用靈活且方便調試的動態圖更適合學術科研。那么曠視的天元則在兼具了雙方特性的過程中,找到了一個的平衡點。天元是一個訓練和推理在同一個框架、同一個體系內完整支持的設計。基于這些創新性的框架設計,天元深度學習框架擁有推理訓練一體化、動靜合一、兼容并包和靈活高效四大優勢:
訓練推理:一體化天元既能夠支持開發者進行算法訓練,同時其訓練得到的模型,還可以直接用于產品的推理和封裝,無需進行多余的模型轉換。這極大地簡化了算法開發流程,實現速度和精度的無損遷移。與此同時,天元在模型部署時還能夠自動優化模型,自動幫助開發者刪除冗余代碼。
動靜合一:天元將動態圖的簡單靈活,與靜態圖的高性能優勢進行整合,能在充分利用動態圖模型訓練優勢的同時,通過動靜態一鍵轉換功能,以靜態圖的形式完成生產和部署。此外,天元還支持動靜態的混合編程,進一步提高其靈活性。
兼容并包:天元部署了Pythonic的API和PyTorchModule功能,支持模型直接導入,進一步降低框架遷移的入門門檻和學習成本。同時,它內置高性能計算機視覺算子和算法,能夠深度優化計算機視覺相關模型訓練和應用。
靈活高效:在部署方面,天元擁有多平臺多設備適應能力,其內置算子能夠在推理或生產環境中充分利用多核優勢,靈活調用設備算力,十分適用于大模型算法訓練。
3月,曠視推出的天元是Alpha版本,其中包括曠視前期整理的代碼和關鍵步驟。今年6月曠視推出了Beta版本,添加對ARM系列CPU的支持,以及更多加速芯片的支持。而天元的正式版本將于今年9月發布,除了添加對主流計算設備的支持外,還將升級其動態計算能力,進一步優化訓練推理全流程的使用體驗。與此同時,曠視天元已在GitHub和國內新一代人工智能開源開放社區OpenI上同步開源。
Jittor(計圖)
Jittor 出自清華大學,開發團隊來自清華大學計算機系圖形學實驗室,牽頭者是清華大學計算機系胡事民教授。Jittor 是國內第一個由高校開源的深度學習框架,同時也是繼 Theano、Caffe 之后,又一個由高校主導的框架。
與主流的深度學習框架TensorFlow、Pytorch不同,Jittor是一個完全基于動態編譯(Just-in-time)、使用元算子和統一計算圖的深度學習框架。Jittor 前端語言為 Python,使用了模塊化的設計,類似于 PyTorch、Keras;后端則使用高性能語言編寫,如 CUDA、C++。元算子和 Numpy 一樣易于使用,而統一計算圖則是融合了靜態計算圖和動態計算圖的諸多優點,在易于使用的同時,提供高性能的優化。基于元算子開發的深度學習模型,可以被計圖實時地自動優化并且運行在指定的硬件上,如 CPU、GPU。
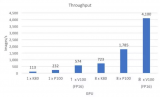
Jittor開發團隊提供了實驗數據。在ImageNet數據集上,使用Resnet50模型,GPU圖像分類任務性能比PyTorch相比,提升32%;CPU圖像分類任務提升11%。在CelebA數據集上,使用LSGAN模型,使用GPU處理圖像生成任務,Jittor比PyTorch性能提升達51%。
此外,為了方便更多人上手Jittor,開發團隊采用了和PyTorch較為相似的模塊化接口,并提供輔助轉換腳本,可以將PyTorch的模型自動轉換成Jittor的模型。他們介紹稱,在參數保存和數據傳輸上,Jittor使用和PyTorch一樣的 Numpy+pickle 協議,所以Jittor和PyTorch的模型可以相互加載和調用。
當然, Jittor作為一個新興深度學習框架,在一些功能上,仍舊需要持續迭代完善。比如生態的建設,以及更大范圍的推廣,仍舊需要很多的努力。Jittor開發團隊介紹稱,就目前來看,Jittor框架的模型支持還待完善,分布式功能待完善。這也是他們下一階段研發的重點。
總的來說,各家的深度學習框架各有千秋,重要的是找到適合自己團隊的,能夠快速匹配團隊的技術棧,快速試驗以期發揮深度學習技術應用落地的商業價值。
編輯:hfy



















 工商網監
工商網監
評論