") 喜訊 | 京東聯(lián)合地瓜機(jī)器人等多家企業(yè)高校,推出業(yè)內(nèi)首個(gè)具身智能原子技能庫(kù)架構(gòu)
喜訊 | 京東聯(lián)合地瓜機(jī)器人等多家企業(yè)高校,推出業(yè)內(nèi)首個(gè)具身智能原子技能庫(kù)架構(gòu)

概述
隨著大模型技術(shù)的進(jìn)步,具身智能也迎來(lái)了快速的發(fā)展。但在國(guó)內(nèi)眾多企業(yè)與高校推動(dòng)相關(guān)技術(shù)發(fā)展的過(guò)程中,核心挑戰(zhàn)仍在于具身操作泛化能力,即如何在有限的具身數(shù)據(jù)下,使機(jī)器人適應(yīng)復(fù)雜場(chǎng)景并實(shí)現(xiàn)技能高效遷移。
為此,京東探索研究院李律松、李東江博士團(tuán)隊(duì)聯(lián)合地瓜機(jī)器人秦玉森團(tuán)隊(duì)、中科大徐童團(tuán)隊(duì)、深圳大學(xué)鄭琪團(tuán)隊(duì)、松靈機(jī)器人及睿爾曼智能吳波團(tuán)隊(duì)共同提出具身智能原子技能庫(kù)架構(gòu),并得到了清華 RDT 團(tuán)隊(duì)在baseline 方法上的技術(shù)支持。
該方案是業(yè)界首個(gè)基于三輪數(shù)據(jù)驅(qū)動(dòng)的具身智能原子技能庫(kù)構(gòu)建框架,突破了傳統(tǒng)端到端具身操作的數(shù)據(jù)瓶頸,可動(dòng)態(tài)自定義和更新原子技能,并結(jié)合數(shù)據(jù)收集與 VLA 少樣本學(xué)習(xí)構(gòu)建高效技能庫(kù)。
與此同時(shí),這也將是首個(gè)面向具身產(chǎn)業(yè)應(yīng)用的數(shù)據(jù)采集新范式,旨在形成數(shù)據(jù)標(biāo)準(zhǔn),解決當(dāng)前具身智能領(lǐng)域數(shù)據(jù)匱乏的問(wèn)題,特別是在高校與產(chǎn)業(yè)之間數(shù)據(jù)和范式的流動(dòng)上,從而加速具身大模型研究的推進(jìn)與實(shí)際落地。

論文標(biāo)題:An Atomic Skill Library Construction Method for Data-Efficient EmbodiedManipulation
原文鏈接:https://arxiv.org/pdf/2501.15068
研究背景
具身智能,即具身人工智能,在生成式 AI 時(shí)代迎來(lái)重要突破。通過(guò)跨模態(tài)融合,將文本、圖像、語(yǔ)音等數(shù)據(jù)映射到統(tǒng)一的語(yǔ)義向量空間,為具身智能技術(shù)發(fā)展提供新契機(jī)。VLA(視覺(jué)-語(yǔ)言-動(dòng)作)模型在數(shù)據(jù)可用性與多模態(tài)技術(shù)推動(dòng)下不斷取得進(jìn)展。然而,現(xiàn)實(shí)環(huán)境的復(fù)雜性使具身操作模型在泛化性上仍面臨挑戰(zhàn)。端到端訓(xùn)練依賴海量數(shù)據(jù),會(huì)導(dǎo)致“數(shù)據(jù)爆炸”問(wèn)題,限制 VLA 發(fā)展。將任務(wù)分解為可重用的原子技能降低數(shù)據(jù)需求,但現(xiàn)有方法受限于固定技能集,無(wú)法動(dòng)態(tài)更新。
為解決此問(wèn)題,團(tuán)隊(duì)提出了基于三輪數(shù)據(jù)驅(qū)動(dòng)的原子技能庫(kù)構(gòu)建方法,可在仿真或真實(shí)環(huán)境的模型訓(xùn)練中減少數(shù)據(jù)需求。如圖所示,VLP(視覺(jué)-語(yǔ)言-規(guī)劃)模型將任務(wù)分解為子任務(wù),高級(jí)語(yǔ)義抽象模塊將子任務(wù)定義為通用原子技能集,并通過(guò)數(shù)據(jù)收集與VLA微調(diào)構(gòu)建技能庫(kù)。隨著三輪更新策略的動(dòng)態(tài)擴(kuò)展,技能庫(kù)不斷擴(kuò)增,覆蓋任務(wù)范圍擴(kuò)大。該方法將重點(diǎn)從端到端技能學(xué)習(xí)轉(zhuǎn)向細(xì)顆粒度的原子技能構(gòu)建,有效解決數(shù)據(jù)爆炸問(wèn)題,并提升新任務(wù)適應(yīng)能力。
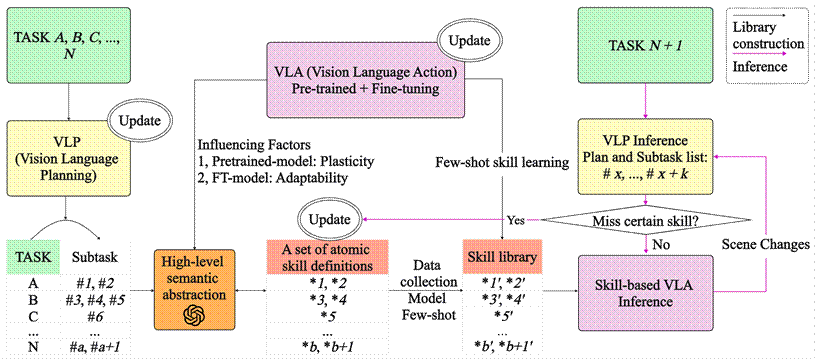 基于三輪數(shù)據(jù)驅(qū)動(dòng)的原子技能庫(kù)構(gòu)建與推理流程
基于三輪數(shù)據(jù)驅(qū)動(dòng)的原子技能庫(kù)構(gòu)建與推理流程為什么需要 VLP?
VLP 需要具有哪些能力?
從產(chǎn)業(yè)落地角度看,具身操作是關(guān)鍵模塊。目前,端到端 VLA 進(jìn)行高頻開(kāi)環(huán)控制,即便中間動(dòng)作失敗,仍輸出下一階段控制信號(hào)。因此,VLA 在高頻控制機(jī)器人/機(jī)械臂時(shí),強(qiáng)烈依賴VLP提供低頻智能控制,以指導(dǎo)階段性動(dòng)作生成,并協(xié)調(diào)任務(wù)執(zhí)行節(jié)奏。
為統(tǒng)一訓(xùn)練與推理的任務(wù)分解,本文構(gòu)建了集成視覺(jué)感知、語(yǔ)言理解和空間智能的VLP Agent。如圖所示,VLP Agent 接收任務(wù)指令文本與當(dāng)前觀察圖像,并利用Prismatic生成場(chǎng)景描述。考慮到 3D 世界的復(fù)雜性,我們?cè)O(shè)計(jì)了一種空間智能感知策略:首先,Dino-X檢測(cè)任務(wù)相關(guān)物體并輸出邊界框;然后,SAM-2提供精細(xì)分割掩碼,并基于規(guī)則判斷物體間的空間關(guān)系。最終,這些視覺(jué)與空間信息與任務(wù)指令一同輸入GPT-4,生成完整執(zhí)行計(jì)劃并指定下一個(gè)子任務(wù)。VLP Agent 通過(guò)該方法在原子技能庫(kù)構(gòu)建中有效分解端到端任務(wù),并在推理過(guò)程中提供低頻控制信號(hào),規(guī)劃并指導(dǎo)高頻原子技能的執(zhí)行。
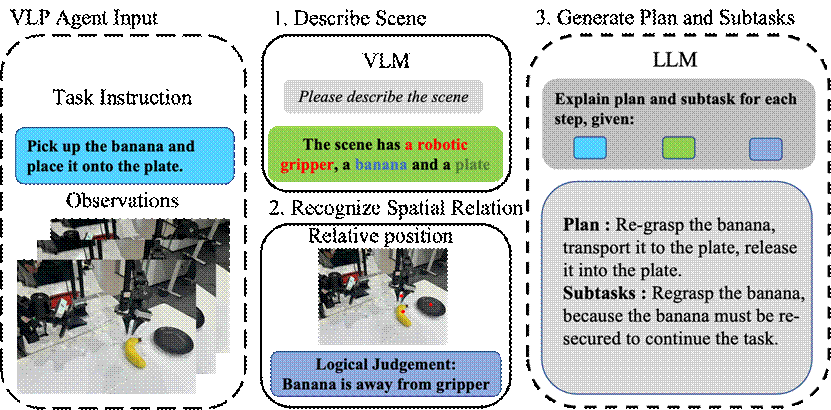 基于空間智能信息的 VLP Agent 具身思維鏈框架
基于空間智能信息的 VLP Agent 具身思維鏈框架VLA 存在的問(wèn)題是什么?
在框架中起什么作用?
VLA 技術(shù)從專用數(shù)據(jù)向通用數(shù)據(jù)演進(jìn),機(jī)器人軌跡數(shù)據(jù)已達(dá)1M episodes級(jí)別;模型參數(shù)規(guī)模從千億級(jí)向端側(cè)部署發(fā)展;性能上,VLA 從單一場(chǎng)景泛化至多場(chǎng)景,提升技能遷移能力。盡管端到端任務(wù)采集與訓(xùn)練有助于科研算法優(yōu)化,但在通用機(jī)器人應(yīng)用中,人為定義端到端任務(wù)易導(dǎo)致任務(wù)窮盡問(wèn)題。在單任務(wù)下,物品位置泛化、背景干擾、場(chǎng)景變化仍是主要挑戰(zhàn),即便強(qiáng)大預(yù)訓(xùn)練模型仍需大量數(shù)據(jù)克服;多任務(wù)下,數(shù)據(jù)需求呈指數(shù)級(jí)增長(zhǎng),面臨“數(shù)據(jù)爆炸”風(fēng)險(xiǎn)。
提出的三輪數(shù)據(jù)驅(qū)動(dòng)的原子技能庫(kù)方法可結(jié)合SOTA VLA模型,通過(guò)高級(jí)語(yǔ)義抽象模塊將復(fù)雜子任務(wù)映射為結(jié)構(gòu)化原子技能,并結(jié)合數(shù)據(jù)收集與 VLA 少樣本學(xué)習(xí)高效構(gòu)建技能庫(kù)。VLA 可塑性衡量模型從多本體遷移至特定本體的能力,泛化性則評(píng)估其應(yīng)對(duì)物體、場(chǎng)景、空間變化的表現(xiàn)。以RDT-1B作品為例,我們基于6000 條開(kāi)源數(shù)據(jù)及2000 條自有數(shù)據(jù)微調(diào)VLA 模型。測(cè)試結(jié)果表明,模型在物品和場(chǎng)景泛化上表現(xiàn)優(yōu)異,但在物品位置泛化方面存在一定局限,且訓(xùn)練步數(shù)對(duì)最終性能影響顯著。為進(jìn)一步優(yōu)化,團(tuán)隊(duì)進(jìn)行了兩項(xiàng)實(shí)驗(yàn)包括位置泛化能力提升及訓(xùn)練步長(zhǎng)優(yōu)化測(cè)試。這類VLA 模型性能測(cè)試對(duì)于原子技能庫(kù)構(gòu)建至關(guān)重要,測(cè)試結(jié)果不僅優(yōu)化了Prompt 設(shè)計(jì),也進(jìn)一步增強(qiáng)了高級(jí)語(yǔ)義抽象模塊在子任務(wù)映射與技能定義中的精準(zhǔn)性。
為什么構(gòu)建原子技能庫(kù)?
怎樣構(gòu)建?
具身操作技能學(xué)習(xí)數(shù)據(jù)源包括互聯(lián)網(wǎng)、仿真引擎和真實(shí)機(jī)器人數(shù)據(jù),三者獲取成本遞增,數(shù)據(jù)價(jià)值依次提升。在多任務(wù)多本體機(jī)器人技能學(xué)習(xí)中,OpenVLA和Pi0依托預(yù)訓(xùn)練VLM,再用真實(shí)軌跡數(shù)據(jù)進(jìn)行模態(tài)對(duì)齊并訓(xùn)練技能,而RDT-1B直接基于百萬(wàn)級(jí)機(jī)器人真實(shí)軌跡數(shù)據(jù)預(yù)訓(xùn)練,可適配不同本體與任務(wù)。無(wú)論模型架構(gòu)如何,真實(shí)軌跡數(shù)據(jù)仍是關(guān)鍵。原子技能庫(kù)的構(gòu)建旨在降低數(shù)據(jù)采集成本,同時(shí)增強(qiáng)任務(wù)適配能力,提升具身操作的通用性,以滿足產(chǎn)業(yè)應(yīng)用需求。
基于數(shù)據(jù)驅(qū)動(dòng)的原子技能庫(kù)構(gòu)建方法,結(jié)合端到端具身操作VLA與具身規(guī)劃VLP,旨在構(gòu)建系統(tǒng)化的技能庫(kù)。VLP 將TASK A, B, C, ..., N分解為Sub-task #1, #2, ..., #a+1。高級(jí)語(yǔ)義抽象模塊基于SOTAVLA模型測(cè)試可調(diào)整任務(wù)粒度,進(jìn)一步將子任務(wù)映射為通用原子技能定義*1, *2, ..., *b+1,并通過(guò)數(shù)據(jù)收集與 VLA 少樣本學(xué)習(xí),構(gòu)建包含*1', *2', ..., *b+1'的原子技能庫(kù)。面對(duì)新任務(wù)TASK N+1,若所需技能已在庫(kù)中,則可直接執(zhí)行;若缺失,則觸發(fā)高級(jí)語(yǔ)義抽象模塊,基于現(xiàn)有技能庫(kù)進(jìn)行原子技能定義更新,僅需對(duì)缺失的原子技能收集額外數(shù)據(jù)與 VLA 微調(diào)。隨著原子技能庫(kù)動(dòng)態(tài)擴(kuò)增,其適應(yīng)任務(wù)范圍不斷增加。相比傳統(tǒng)TASK 級(jí)數(shù)據(jù)采集,提出的原子技能庫(kù)所需要的數(shù)據(jù)采集量根據(jù)任務(wù)難度成指數(shù)級(jí)下降,同時(shí)提升技能適配能力。
實(shí)驗(yàn)與結(jié)果分析
驗(yàn)證問(wèn)題
- 在相同物體點(diǎn)位下采集軌跡數(shù)據(jù),所提方法能否以更少數(shù)據(jù)達(dá)到端到端方法性能?
- 在收集相同數(shù)量的軌跡數(shù)據(jù)下,所提方法能否優(yōu)于端到端方法?
- 面對(duì)新任務(wù),所提方法是否能夠在不依賴或者少依賴新數(shù)據(jù)的條件下仍然有效?
- 所提方法是否適用于不同VLA模型,并保持有效性和效率?
實(shí)驗(yàn)設(shè)置
針對(duì)上述問(wèn)題,我們?cè)O(shè)計(jì)了四個(gè)挑戰(zhàn)性任務(wù),并在RDT-1B和Octo基準(zhǔn)模型上,以Agilex 雙臂機(jī)器人進(jìn)行測(cè)試。實(shí)驗(yàn)采用端到端方法和所提方法分別采集數(shù)據(jù),以對(duì)比兩者在數(shù)據(jù)利用效率和任務(wù)泛化能力上的表現(xiàn)。具體實(shí)驗(yàn)設(shè)置如下:
- 拿起香蕉并放入盤(pán)子
- 端到端方法:從4 個(gè)香蕉點(diǎn)位和2 個(gè)盤(pán)子點(diǎn)位采集24 條軌跡。
- 所提方法:保持?jǐn)?shù)據(jù)分布一致,分解為12 條抓取香蕉軌跡和6 條放置香蕉軌跡。
- 為匹配端到端數(shù)據(jù)量,進(jìn)一步擴(kuò)大采樣范圍,從8 個(gè)香蕉點(diǎn)位采集24 條抓取軌跡,3 個(gè)盤(pán)子點(diǎn)位采集24 條放置軌跡。
- 拿起瓶子并向杯中倒水
- 端到端方法:從3 個(gè)瓶子點(diǎn)位和3 個(gè)杯子點(diǎn)位采集27 條軌跡。
- 所提方法:分解為9 條抓取瓶子軌跡和9 條倒水軌跡,確保數(shù)據(jù)分布一致。
- 進(jìn)一步擴(kuò)大采樣范圍,從9 個(gè)瓶子點(diǎn)位采集27 條抓取軌跡,9 個(gè)杯子點(diǎn)位采集27 條倒水軌跡。
- 拿起筆并放入筆筒
- 端到端方法:從4 個(gè)筆點(diǎn)位和2 個(gè)筆筒點(diǎn)位采集24 條軌跡。
- 所提方法:分解為12 條抓取筆軌跡和6 條放置筆軌跡,保持?jǐn)?shù)據(jù)分布一致。
- 進(jìn)一步擴(kuò)大采樣范圍,從8 個(gè)筆點(diǎn)位采集24 條抓取軌跡,3 個(gè)筆筒點(diǎn)位采集24 條放置軌跡。
- 按指定順序抓取積木(紅、綠、藍(lán))
- 端到端方法:采集10 條軌跡,固定積木位置,按順序抓取紅色、綠色、藍(lán)色積木。
- 所提方法:為匹配端到端數(shù)據(jù)量,分別采集10 條抓取紅色、綠色、藍(lán)色積木軌跡,共30 條。
 任務(wù)定義與可視化
任務(wù)定義與可視化實(shí)驗(yàn)結(jié)果
前三個(gè)任務(wù)用于驗(yàn)證所提方法在數(shù)據(jù)效率和操作性能上的表現(xiàn),第四個(gè)任務(wù)則評(píng)估其新任務(wù)適應(yīng)能力。為確保公平性,每種實(shí)驗(yàn)設(shè)置均在Octo和RDT-1B上進(jìn)行10 次測(cè)試,對(duì)比端到端方法與所提方法(“Ours” 和 “Ours-plus”)。如表1所示,“End-To-End”:原始端到端VLA方法;“Ours”:保持?jǐn)?shù)據(jù)分布一致,但數(shù)據(jù)量更小;“Ours-plus”:保持?jǐn)?shù)據(jù)量一致,但采集更多點(diǎn)位;“ID”:任務(wù)點(diǎn)位在訓(xùn)練數(shù)據(jù)分布內(nèi);“OOD”:任務(wù)點(diǎn)位超出訓(xùn)練數(shù)據(jù)分布。在第四個(gè)任務(wù)中,設(shè)定紅-綠-藍(lán)順序抓取積木為已知任務(wù),并采集數(shù)據(jù)訓(xùn)練模型。針對(duì)其他顏色順序的未知任務(wù),直接調(diào)用已訓(xùn)練的技能進(jìn)行測(cè)試,以評(píng)估方法的泛化能力(見(jiàn)表 2)。結(jié)果分析如下:
Q1: 從表 1 可見(jiàn),Octo 和 RDT-1B在使用所提方法后,成功率與端到端方法相當(dāng)甚至更高。在拿起瓶子并向杯中倒水任務(wù)中,OOD 測(cè)試成功率提升 20%,表明該方法在相同點(diǎn)位分布下,減少數(shù)據(jù)需求同時(shí)提升性能。
Q2: 在相同數(shù)據(jù)量下,所提方法顯著提升成功率。例如,在拿起香蕉并放入盤(pán)子任務(wù)中,OOD 情況下成功率提高 40%,歸因于從更多點(diǎn)位采集數(shù)據(jù),增強(qiáng)模型泛化能力。
Q3: 從表 2 可見(jiàn),端到端方法僅適用于已知任務(wù),無(wú)法泛化新任務(wù),而所提方法能通過(guò)已有技能組合成功執(zhí)行不同的新任務(wù)。
Q4: 表 1 和表 2 進(jìn)一步驗(yàn)證,所提方法在多種VLA模型上均提升數(shù)據(jù)效率、操作性能和新任務(wù)適應(yīng)能力,適用于不同模型的泛化與優(yōu)化。
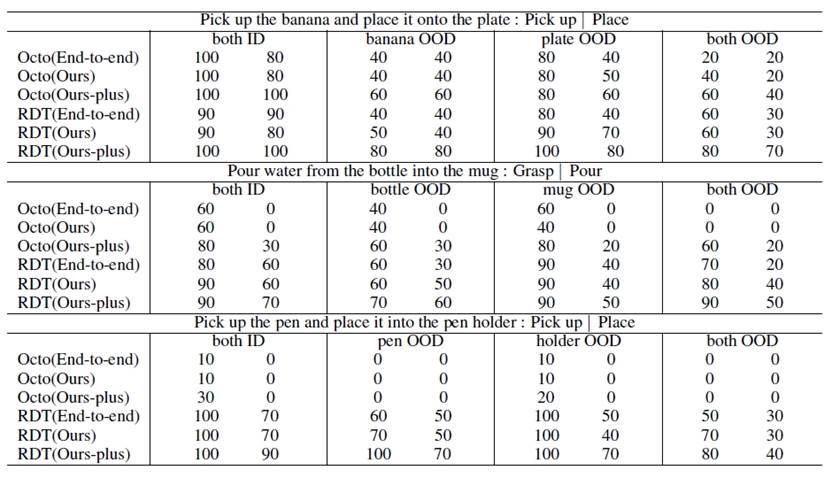 表1:與原始端到端方法實(shí)驗(yàn)結(jié)果對(duì)比
表1:與原始端到端方法實(shí)驗(yàn)結(jié)果對(duì)比 表2:與原始端到端方法方塊抓取任務(wù)實(shí)驗(yàn)結(jié)果對(duì)比
表2:與原始端到端方法方塊抓取任務(wù)實(shí)驗(yàn)結(jié)果對(duì)比小結(jié)
基于三輪數(shù)據(jù)驅(qū)動(dòng)的原子技能庫(kù)構(gòu)建框架,旨在解決傳統(tǒng)端到端具身操作策略帶來(lái)的“數(shù)據(jù)爆炸”問(wèn)題,為具身智能產(chǎn)業(yè)應(yīng)用提供創(chuàng)新解決方案。該框架具有廣泛價(jià)值,可用于提升物流倉(cāng)儲(chǔ)、智能制造、醫(yī)療輔助等領(lǐng)域的自動(dòng)化水平。例如,在醫(yī)療輔助和服務(wù)機(jī)器人領(lǐng)域,它能夠增強(qiáng)自主交互能力,助力精準(zhǔn)操作。希望此項(xiàng)工作能夠?yàn)樾袠I(yè)提供重要啟示,促進(jìn)學(xué)術(shù)界與產(chǎn)業(yè)界的深度合作,加速具身智能技術(shù)的實(shí)際應(yīng)用。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
29748瀏覽量
212931 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7256瀏覽量
91891 -
人工智能
+關(guān)注
關(guān)注
1807文章
49029瀏覽量
249584 -
具身智能
+關(guān)注
關(guān)注
0文章
143瀏覽量
477
發(fā)布評(píng)論請(qǐng)先 登錄
盤(pán)點(diǎn)#機(jī)器人開(kāi)發(fā)平臺(tái)
RDK全系賦能!點(diǎn)貓科技與地瓜機(jī)器人共建具身智能大中小貫通培養(yǎng)閉環(huán)要聞

樂(lè)聚機(jī)器人與地瓜機(jī)器人達(dá)成戰(zhàn)略合作,聯(lián)合發(fā)布Aelos Embodied具身智能

探索具身智能邊界,地瓜機(jī)器人邀你共戰(zhàn)ICRA 2025 Sim2Real挑戰(zhàn)賽

【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人的基礎(chǔ)模塊
《具身智能機(jī)器人系統(tǒng)》第10-13章閱讀心得之具身智能機(jī)器人計(jì)算挑戰(zhàn)
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】+兩本互為支持的書(shū)
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人大模型
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】1.初步理解具身智能
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】1.全書(shū)概覽與第一章學(xué)習(xí)
《具身智能機(jī)器人系統(tǒng)》第7-9章閱讀心得之具身智能機(jī)器人與大模型
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】+初品的體驗(yàn)
《具身智能機(jī)器人系統(tǒng)》第1-6章閱讀心得之具身智能機(jī)器人系統(tǒng)背景知識(shí)與基礎(chǔ)模塊
名單公布!【書(shū)籍評(píng)測(cè)活動(dòng)NO.51】具身智能機(jī)器人系統(tǒng) | 了解AI的下一個(gè)浪潮!
國(guó)內(nèi)首個(gè)具身智能工業(yè)機(jī)器人領(lǐng)域報(bào)告重磅開(kāi)啟!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論