 NVIDIA Triton 系列文章(7):image_client 用戶端參數
NVIDIA Triton 系列文章(7):image_client 用戶端參數

作為服務器的最重要任務,就是要接受來自不同終端所提出的各種請求,然后根據要求執行對應的計算,再將計算結果返回給終端。
當 Triton 推理服務器運行起來之后,就進入等待請求的狀態,因此我們所要提出的請求內容,就必須在用戶端軟件里透過參數去調整請求的內容,這部分在 Triton 相關使用文件中并沒有提供充分的說明,因此本文的重點就在于用Python 版的 image_client.py 來說明相關參數的內容,其他用戶端的參數基本上與這個端類似,可以類比使用。
本文的實驗內容,是將 Triton 服務器安裝在 IP 為 192.168.0.10 的 Jetson AGX Orin 上,將 Triton 用戶端裝在 IP 為 192.168.0.20 的樹莓派上,讀者可以根據已有的設備資源自行調配。
在開始進行實驗之前,請先確認以下兩個部分的環境:
在服務器設備上啟動 Triton 服務器,并處于等待請求的狀態:
如果還沒啟動的話,請直接執行以下指令:
# 根據實際的模型倉根目錄位置設定TRITON_MODEL_REPO路徑
$ export TRITON_MODEL_REPO=${HOME}/triton/server/docs/examples/model_repository
執行Triton服務器
$ dockerrun--rm--net=host-v${TRITON_MODEL_REPO}:/modelsnvcr.io/nvidia/tritonserver:22.09-py3tritonserver--model-repository=/models在用戶端設備下載 Python 的用戶端范例,并提供若干張要檢測的圖片:
先執行以下指令,確認Triton服務器已經正常啟動,并且從用戶端設備可以訪問:
curl -v 192.168.0.10:8000/v2/health/ready只要后面出現的信息中有“HTTP/1.1 200 OK”部分,就表示一切正常。
如果還沒安裝 Triton 的 Python 用戶端環境,并且還未下載用戶端范例的話,請執行以下指令:
$ cd ${HOME}/triton
$ git clone https://github.com/triton-inference-server/client
$ cd client/src/python/examples
# 安裝 Triton 的 Python用戶端環境
$ pip3installtritonclient[all]attrdict-ihttps://pypi.tuna.tsinghua.edu.cn/simple最后記得在用戶端設備上提供幾張圖片,并且放置在指定文件夾(例如~/images)內,準備好整個實驗環境,就可以開始下面的說明。
現在執行以下指令,看一下 image_client 這個終端的參數列表:
python3 image_client.py會出現以下的信息:

接下來就來說明這些參數的用途與用法。
用“-u”參數對遠程服務器提出請求:
如果用戶端與服務器端并不在同一臺機器上的時候,就可以用這個參數對遠程 Triton 服務器提出推理請求,請執行以下指令:
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images/mug.jpg由于 Triton 的跨節點請求主要透過 HTTP/REST 協議處理,需要透過 8000 端口進行傳輸,因此在“-u”后面需要接上“IP:8000”就能正常使用。
請自行檢查回饋的計算結果是否正確!
2. 用“-m”參數去指推理模型:
從“python3 image_client.py”所產生信息的最后部分,可以看出用“-m”參數去指定推理模型是必須的選項,但是可以指定哪些推理模型呢?就得從 Triton 服務器的啟動信息中去尋找答案。
下圖是本范例是目前啟動的 Triton 推理服務器所支持的模型列表:
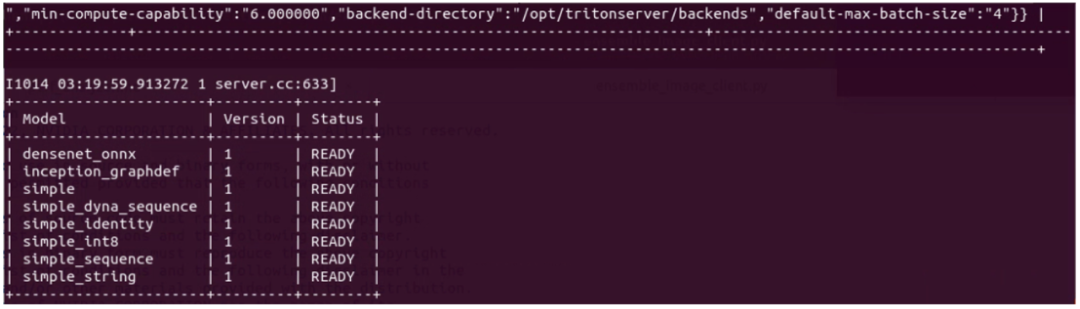
這里顯示有的 8 個推理模型,就是啟動服務器時使用“--model-repository=”參數指定的模型倉內容,因此客戶端使用“-m”參數指定的模型,必須是在這個表所列的內容之列,例如“-mdensenet_onnx”、“-m inception_graphdef”等等。
現在執行以下兩道指令,分別看看使用不同模型所得到的結果有什么差異:
$ python3 image_client.py -m densenet_onnx -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images/mug.jpg
$ python3image_client.py-minception_graphdef-u192.168.0.10:8000-sINCEPTION${HOME}/images/mug.jpg使用 densenet_onnx 模型與 inception_graphdef 模型所返回的結果,分別如下:

雖然兩個模型所得到的檢測結果一致,但是二者所得到的置信度表達方式并不相同,而且標簽編號并不一樣(504 與 505)。
這個參數后面還可以使用“-x”去指定“版本號”,不過目前所使用的所有模型都只有一個版本,因此不需要使用這個參數。
3. 使用“-s”參數指定圖像縮放方式:
有些神經網絡算法在執行推理之前,需要對圖像進行特定形式的縮放(scaling)處理,因此需要先用這個參數指定縮放的方式,如果沒有指定正確的模式,會導致推理結果的錯誤。目前這個參數支持{NONE, INSPECTION, VGG}三個選項,預設值為“NONE”。
在本實驗 Triton 推理服務器所支持的 densenet_onnx 與 inception_graphdef 模型,都需要選擇 INSPECTION 縮放方式,因此執行指令中需要用“-s INSPECTION”去指定,否則會得到錯誤的結果。
請嘗試以下指令,省略前面指定中的“-s INSPECTION”,或者指定為 VGG 模式,看看結果如何?
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s VGG ${HOME}/images/mug.jpg4. 對文件夾所有圖片進行推理
如果有多個要進行推理計算的標的物(圖片),Triton 用戶端可用文件夾為單位來提交要推理的內容,例如以下指令就能一次對 ${HOME}/images 目錄下所有圖片進行推理:
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images例如我們在文件夾中準備了 car.jpg、mug.jpg、vulture.jpg 三種圖片,如下:

執行后反饋的結果如下:

顯示推理檢測的結果是正確的!
5. 用“-b”參數指定批量處理的值
執行前面指令的結果可以看到“batch size 1”,表示用戶端每次提交一張圖片進行推理,所以出現 Request1、Request 2 與 Request 3 總共提交三次請求。
現在既然有 3 張圖片,可否一次提交 3 張圖片進行推理呢?我們可以用“-b”參數來設定,如果將前面的指令中添加“-b3”這個參數,如下:
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images -b 3現在顯示的結果如下:

現在看到只提交一次“batch size 3”的請求,就能對三張圖片進行推理。如果 batch 值比圖片數量大呢?例如改成“-b 5”的時候,看看結果如何?如下:

現在可以看到所推理的圖片數量是 5,其中 1/4、2/5 是同一張圖片,表示重復使用了。這樣就應該能清楚這個“batchsize”值的使用方式。
但如果這里將模型改成 densenet_onnx 的時候,執行以下指令:
python3 image_client.py -m densenet_onnx -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images -b 3會得到“ERROR: This model doesn't support batching.”的錯誤信息,這時候就回頭檢查以下模型倉里 densenet_onnx 目錄下的 config.pbtxt 配置文件,會發現里面設置了“max_batch_size: 0”,并不支持批量處理。
而 inception_graphdef 模型的配置文件里設置“max_batch_size: 128”,如果指令給定“-b”參數大于這個數值,也會出現錯誤信息。
6. 其他:
另外還有指定通訊協議的“-i”參數、使用異步推理 API 的“-a”參數、使用流式推理 API 的“--streaming”參數等等,屬于較進階的用法,在這里先不用過度深入。
以上所提供的 5 個主要參數,對初學者來說是非常足夠的,好好掌握這幾個參數就已經能開始進行更多圖像方面的推理實驗。
推薦閱讀
NVIDIA Jetson Nano 2GB 系列文章(1):開箱介紹

NVIDIA Jetson Nano 2GB 系列文章(2):安裝系統
NVIDIA Jetson Nano 2GB 系列文章(3):網絡設置及添加 SWAPFile 虛擬內存
NVIDIA Jetson Nano 2GB 系列文章(4):體驗并行計算性能
NVIDIA Jetson Nano 2GB 系列文章(5):體驗視覺功能庫
NVIDIA Jetson Nano 2GB 系列文章(6):安裝與調用攝像頭
NVIDIA Jetson Nano 2GB 系列文章(8):執行常見機器視覺應用
NVIDIA Jetson Nano 2GB 系列文章(9):調節 CSI 圖像質量
NVIDIA Jetson Nano 2GB 系列文章(10):顏色空間動態調節技巧
NVIDIA Jetson Nano 2GB 系列文章(11):你應該了解的 OpenCV
NVIDIA Jetson Nano 2GB 系列文章(12):人臉定位
NVIDIA Jetson Nano 2GB 系列文章(13):身份識別
NVIDIA Jetson Nano 2GB 系列文章(14):Hello AI World
NVIDIA Jetson Nano 2GB 系列文章(15):Hello AI World 環境安裝
NVIDIA Jetson Nano 2GB 系列文章(16):10行代碼威力
NVIDIA Jetson Nano 2GB 系列文章(17):更換模型得到不同效果
NVIDIA Jetson Nano 2GB 系列文章(18):Utils 的 videoSource 工具
NVIDIA Jetson Nano 2GB 系列文章(19):Utils 的 videoOutput 工具
NVIDIA Jetson Nano 2GB 系列文章(20):“Hello AI World” 擴充參數解析功能
NVIDIA Jetson Nano 2GB 系列文章(21):身份識別

NVIDIA Jetson Nano 2GB 系列文章(22):“Hello AI World” 圖像分類代碼
NVIDIA Jetson Nano 2GB 系列文章(23):“Hello AI World 的物件識別應用
NVIDIAJetson Nano 2GB 系列文章(24): “Hello AI World” 的物件識別應用
NVIDIAJetson Nano 2GB 系列文章(25): “Hello AI World” 圖像分類的模型訓練
NVIDIAJetson Nano 2GB 系列文章(26): “Hello AI World” 物件檢測的模型訓練
NVIDIAJetson Nano 2GB 系列文章(27): DeepStream 簡介與啟用
NVIDIAJetson Nano 2GB 系列文章(28): DeepStream 初體驗
NVIDIAJetson Nano 2GB 系列文章(29): DeepStream 目標追蹤功能
NVIDIAJetson Nano 2GB 系列文章(30): DeepStream 攝像頭“實時性能”
NVIDIAJetson Nano 2GB 系列文章(31): DeepStream 多模型組合檢測-1
NVIDIAJetson Nano 2GB 系列文章(32): 架構說明與deepstream-test范例
NVIDIAJetsonNano 2GB 系列文章(33): DeepStream 車牌識別與私密信息遮蓋
NVIDIA Jetson Nano 2GB 系列文章(34): DeepStream 安裝Python開發環境
NVIDIAJetson Nano 2GB 系列文章(35): Python版test1實戰說明
NVIDIAJetson Nano 2GB 系列文章(36): 加入USB輸入與RTSP輸出
NVIDIAJetson Nano 2GB 系列文章(37): 多網路模型合成功能
NVIDIAJetson Nano 2GB 系列文章(38): nvdsanalytics視頻分析插件
NVIDIAJetson Nano 2GB 系列文章(39): 結合IoT信息傳輸
NVIDIAJetson Nano 2GB 系列文章(40): Jetbot系統介紹
NVIDIAJetson Nano 2GB 系列文章(41): 軟件環境安裝
NVIDIAJetson Nano 2GB 系列文章(42): 無線WIFI的安裝與調試
NVIDIAJetson Nano 2GB 系列文章(43): CSI攝像頭安裝與測試
NVIDIAJetson Nano 2GB 系列文章(44): Jetson的40針引腳
NVIDIAJetson Nano 2GB 系列文章(46): 機電控制設備的安裝
NVIDIAJetson Nano 2GB 系列文章(47): 組裝過程的注意細節
NVIDIAJetson Nano 2GB 系列文章(48): 用鍵盤與搖桿控制行動
NVIDIAJetson Nano 2GB 系列文章(49): 智能避撞之現場演示
NVIDIAJetson Nano 2GB 系列文章(50): 智能避障之模型訓練
NVIDIAJetson Nano 2GB 系列文章(51): 圖像分類法實現找路功能
NVIDIAJetson Nano 2GB 系列文章(52): 圖像分類法實現找路功能
NVIDIAJetson Nano 2GB 系列文章(53): 簡化模型訓練流程的TAO工具套件
NVIDIA Jetson Nano 2GB 系列文章(54):NGC的內容簡介與注冊密鑰
NVIDIA Jetson Nano 2GB 系列文章(55):安裝TAO模型訓練工具
NVIDIA Jetson Nano 2GB 系列文章(56):啟動器CLI指令集與配置文件
NVIDIA Jetson Nano 2GB 系列文章(57):視覺類腳本的環境配置與映射
NVIDIA Jetson Nano 2GB 系列文章(58):視覺類的數據格式
NVIDIA Jetson Nano 2GB 系列文章(59):視覺類的數據增強
NVIDIA Jetson Nano 2GB 系列文章(60):圖像分類的模型訓練與修剪
NVIDIA Jetson Nano 2GB 系列文章(61):物件檢測的模型訓練與優化
NVIDIA Jetson Nano 2GB 系列文章(62):物件檢測的模型訓練與優化-2
NVIDIA Jetson Nano 2GB 系列文章(63):物件檢測的模型訓練與優化-3
NVIDIA Jetson Nano 2GB 系列文章(64):將模型部署到Jetson設備
NVIDIA Jetson Nano 2GB 系列文章(65):執行部署的 TensorRT 加速引擎
NVIDIA Jetson 系列文章(1):硬件開箱

NVIDIA Jetson 系列文章(2):配置操作系統
NVIDIA Jetson 系列文章(3):安裝開發環境
NVIDIA Jetson 系列文章(4):安裝DeepStream
NVIDIA Jetson 系列文章(5):使用Docker容器的入門技巧
NVIDIA Jetson 系列文章(6):使用容器版DeepStream
NVIDIA Jetson 系列文章(7):配置DS容器Python開發環境
NVIDIA Jetson 系列文章(8):用DS容器執行Python范例
NVIDIA Jetson 系列文章(9):為容器接入USB攝像頭
NVIDIA Jetson 系列文章(10):從頭創建Jetson的容器(1)
NVIDIA Jetson 系列文章(11):從頭創建Jetson的容器(2)
NVIDIA Jetson 系列文章(12):創建各種YOLO-l4t容器
NVIDIA Triton系列文章(1):應用概論
NVIDIA Triton系列文章(2):功能與架構簡介
NVIDIA Triton系列文章(3):開發資源說明
NVIDIA Triton系列文章(4):創建模型倉
NVIDIA Triton 系列文章(5):安裝服務器軟件
NVIDIA Triton 系列文章(6):安裝用戶端軟件
原文標題:NVIDIA Triton 系列文章(7):image_client 用戶端參數
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3953瀏覽量
93820
原文標題:NVIDIA Triton 系列文章(7):image_client 用戶端參數
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用NVIDIA Triton和TensorRT-LLM部署TTS應用的最佳實踐

如何在Ubuntu上安裝NVIDIA顯卡驅動?
解決HarmonyOS應用中Image組件白塊問題的有效方案

NVIDIA技術助力Pantheon Lab數字人實時交互解決方案
電能管理系統-用戶端智能化用電管理安全、可靠
Triton編譯器與GPU編程的結合應用
Triton編譯器的優化技巧
Triton編譯器的優勢與劣勢分析
Triton編譯器在機器學習中的應用
Triton編譯器支持的編程語言
Triton編譯器功能介紹 Triton編譯器使用教程

NVIDIA JetPack 6.0版本的關鍵功能






 工商網監
工商網監
評論